LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
MacOS安装
没看安装指南就pip install后,会显示错误
Mac的安装显示错误后的解决办法
1.pip uninstall lightGBM
2.根据github上的提示一步步执行
3. pip3 install lightGBM 后仍报错,但此错误有提示,按照提示执行brew reinstall libomp后,可正常食用。
据说正确的安装姿势:
brew install cmake
brew install gcc
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
#在cmake之前有一步添加环境变量
export CXX=g++-7 CC=gcc-7
mkdir build ; cd build
cmake ..
make -j4
cd ../python-package
sudo python setup.py install
实例:
# coding: utf-8
# pylint: disable = invalid-name, C0111
# 函数的更多使用方法参见LightGBM官方文档:http://lightgbm.readthedocs.io/en/latest/Python-Intro.html
import json
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
iris = load_iris() # 载入鸢尾花数据集
data=iris.data
target = iris.target
X_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2)
# 加载你的数据
# print('Load data...')
# df_train = pd.read_csv('../regression/regression.train', header=None, sep='\t')
# df_test = pd.read_csv('../regression/regression.test', header=None, sep='\t')
#
# y_train = df_train[0].values
# y_test = df_test[0].values
# X_train = df_train.drop(0, axis=1).values
# X_test = df_test.drop(0, axis=1).values
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(X_train, y_train) # 将数据保存到LightGBM二进制文件将使加载更快
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train) # 创建验证数据
# 将参数写成字典下形式
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
print('Start training...')
# 训练 cv and train
gbm = lgb.train(params,lgb_train,num_boost_round=20,valid_sets=lgb_eval,early_stopping_rounds=5) # 训练数据需要参数列表和数据集
print('Save model...')
gbm.save_model('model.txt') # 训练后保存模型到文件
print('Start predicting...')
# 预测数据集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration) #如果在训练期间启用了早期停止,可以通过best_iteration方式从最佳迭代中获得预测
# 评估模型
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5) # 计算真实值和预测值之间的均方根误差
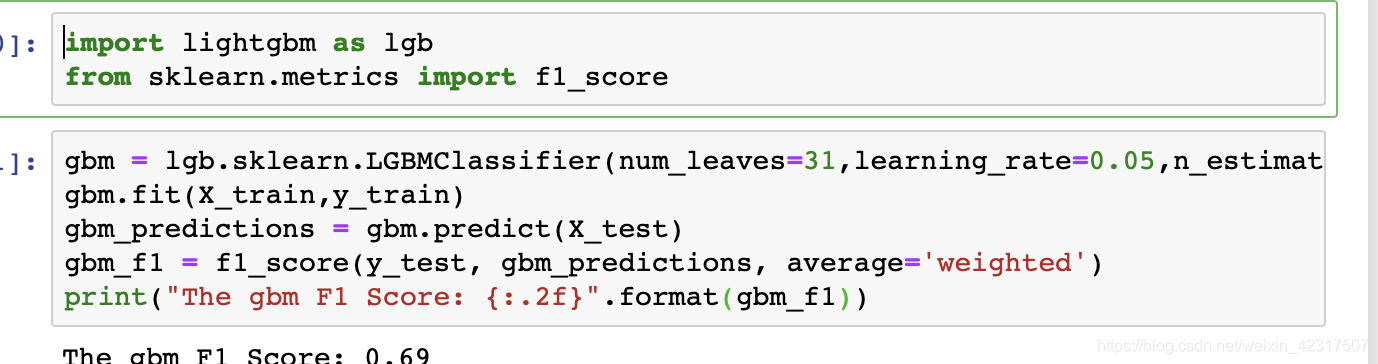
达观杯数据测试集: 验证集(8:2) F1 Score