版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xianqianshi3004/article/details/88062291
初试数据:
数据包含2个csv文件:
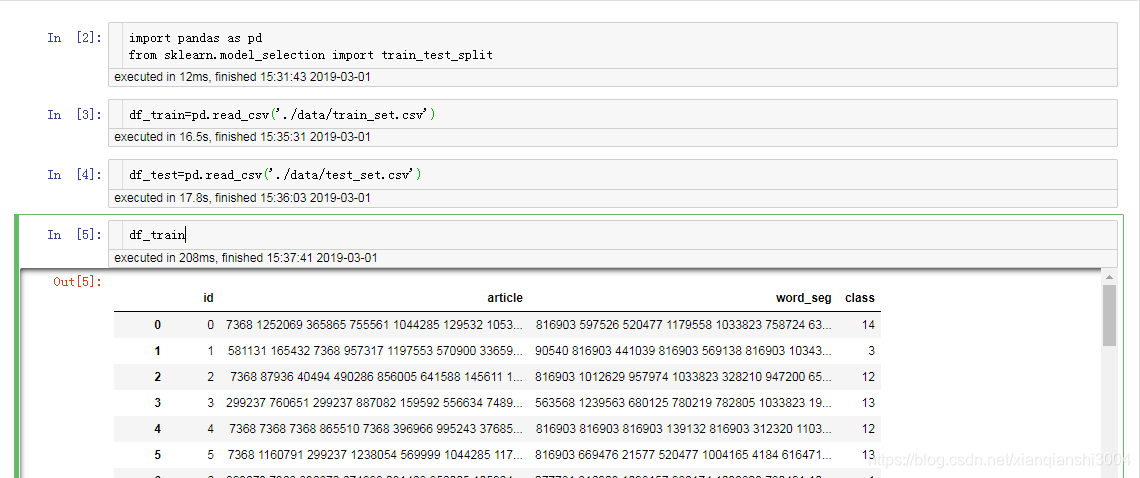
train_set.csv:此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列:
- 第一列是文章的索引(id),
- 第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);
- 第三列是在“词”级别上的表示,即词语相隔正文(word_seg);
- 第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的!
test_set.csv:此数据用于测试。数据格式同train_set.csv,但不包含class。
注:test_set与train_test中文章id的编号是独立的
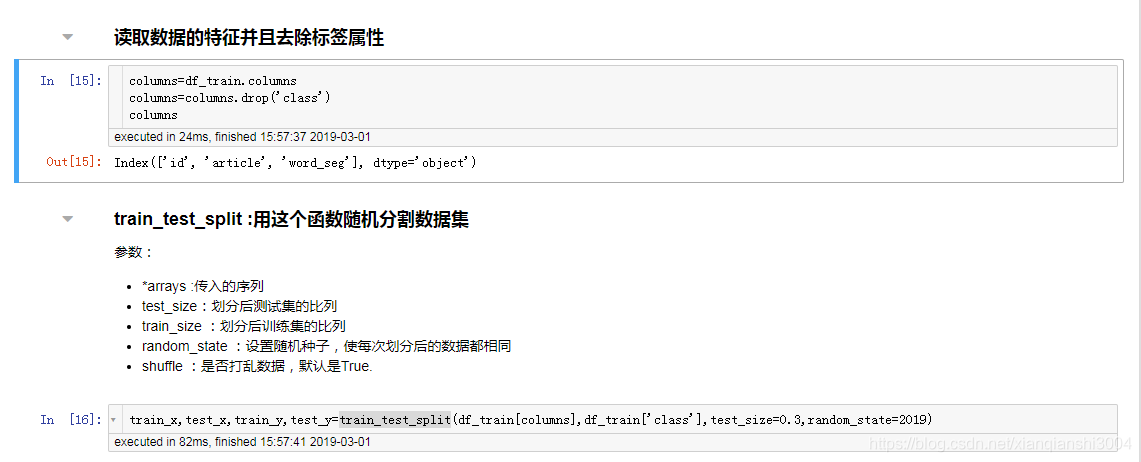
因为数据的每一行包括字的组合和词的组合,两者之间没有相关性,所以我打算在以后的数据数理中主要处理词,以为词才能更好的把文章的意思表达处理。
接下来让我们来看看数据: