一、竞赛介绍
网址:http://www.dcjingsai.com/common/cmpt/“达观杯”文本智能处理挑战赛_竞赛信息.html
任务:建立模型通过长文本数据正文(article),预测文本对应的类别(class)
数据:包含两个csv文件
1、train_set.csv:此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列: 第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。 注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的!
2、test_set.csv:此数据用于测试。数据格式同train_set.csv,但不包含class。 注:test_set与train_test中文章id的编号是独立的。
评分标准:
binary-classification
采用各个品类F1指标的算术平均值,它是Precision 和 Recall 的调和平均数。
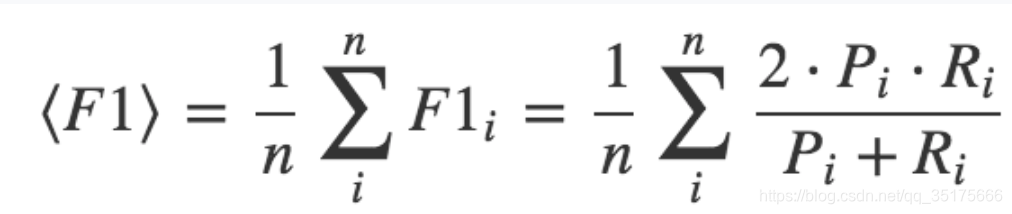
其中,Pi是表示第i个种类对应的Precision, Ri是表示第i个种类对应Recall。
二、数据初识
使用pandas的read_csv方法读取数据
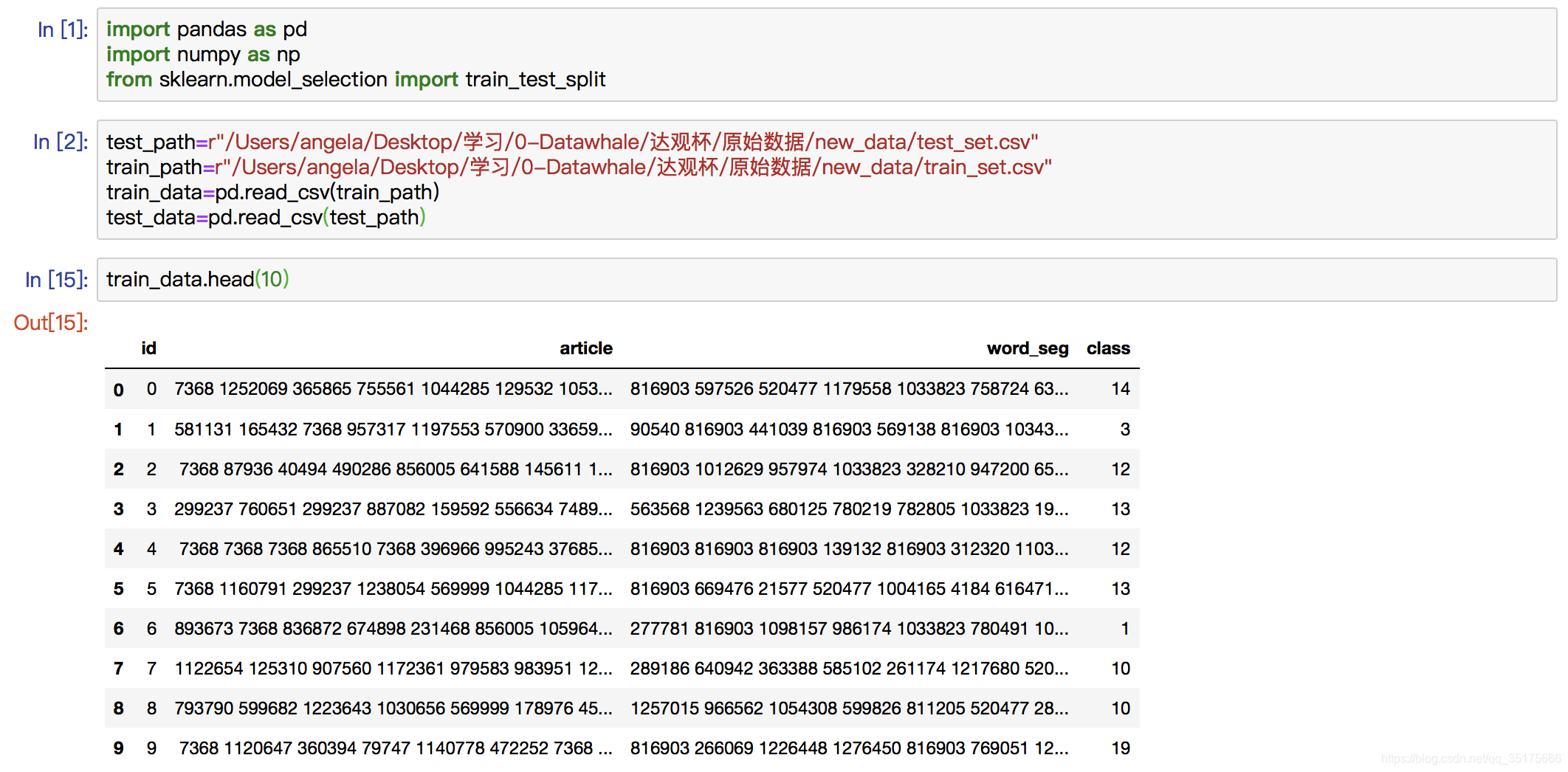
打印出train_data的前十条数据:
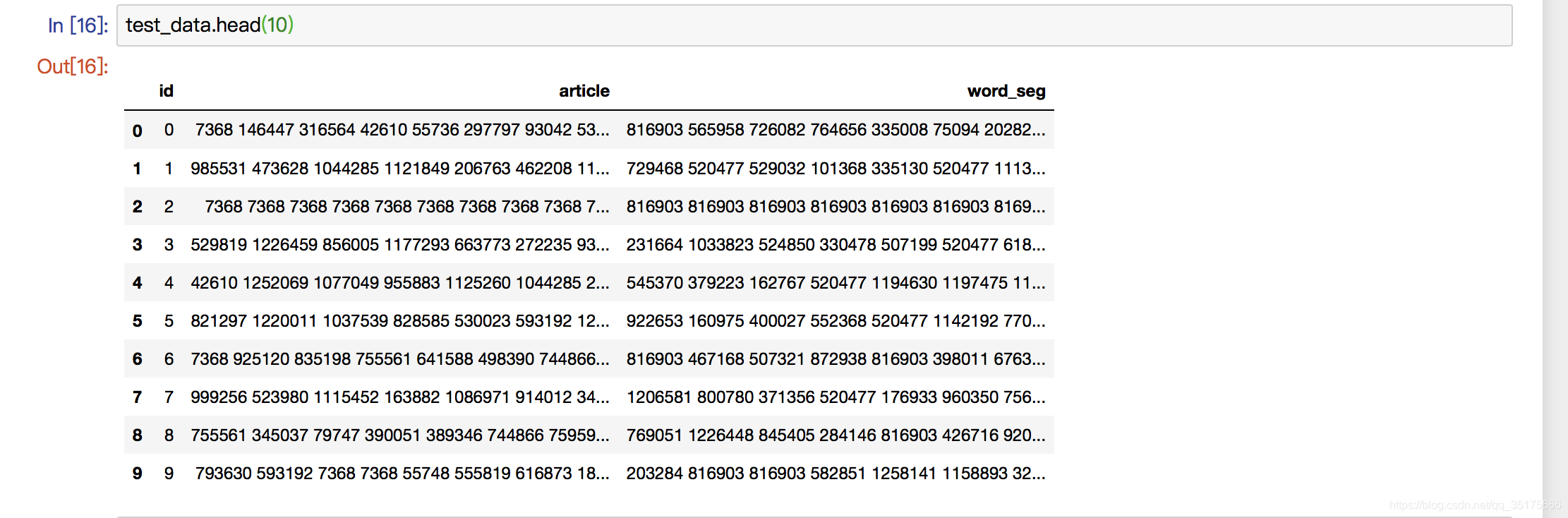
打印出test_data的前十条数据:
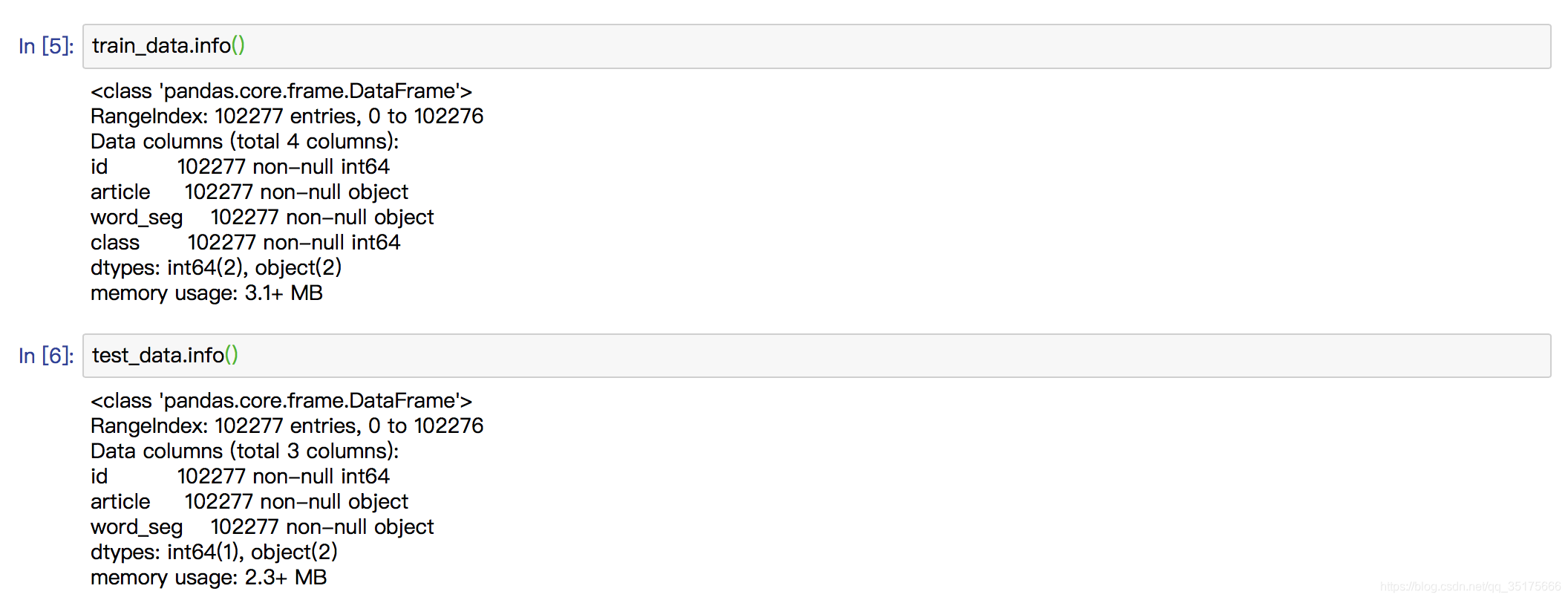
打印出文件的信息:
检测数据是否有空值:

划分训练集和验证集:

打印训练集和验证集的信息:
参考博客:
https://blog.csdn.net/weixin_38966454/article/details/89046445