达观杯文本处理1
一、获取数据
1.数据下载
数据下载地址:
http://www.dcjingsai.com/common/cmpt/“达观杯”文本智能处理挑战赛_赛体与数据.html
下载后会得到一个压缩包,训练集和测试集数据均在里面.
二.处理过程
1.读取
直接读取内存爆炸了,本文只选取了其中的一些复制到excel中,。
import numpy as np
import pandas as pd
df = pd.read_excel("tr.xlsx")
print(df.shape)
print(df.columns)

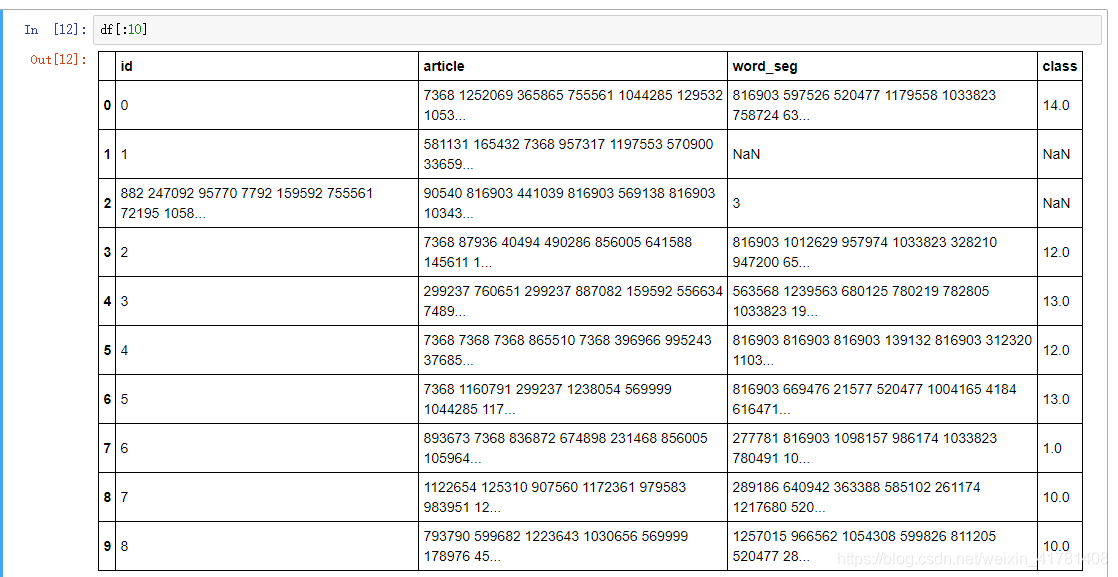
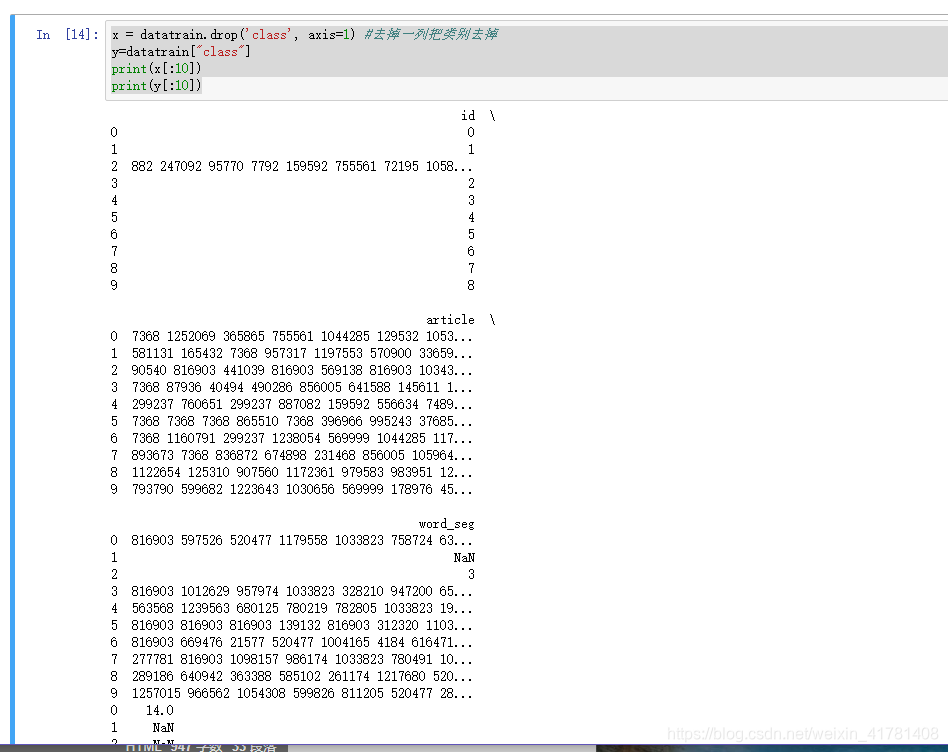
2.分离特征和类别
x = df.drop('class', axis=1) #去掉一列
y=df["class"]
print(x[:10])
print(y[:10])


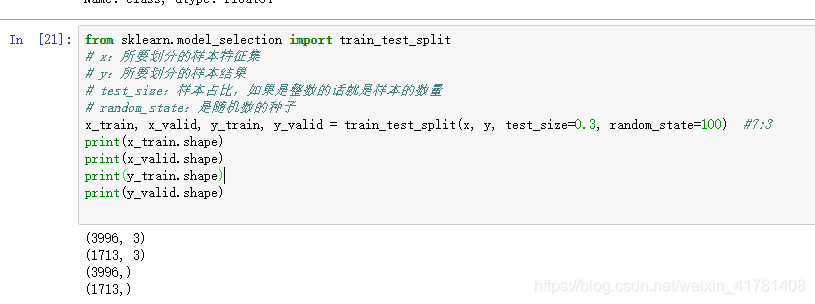
3.将数据shuffle一下。随机一下。
from sklearn.model_selection import train_test_split
# x:所要划分的样本特征集
# y:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.3, random_state=100) #7:3
print(x_train.shape)
print(x_valid.shape)
print(y_train.shape)
print(y_valid.shape)
三.最终改造后的版本
1.读取数据

2.将特征与类别分离
3.保存数据和处理一些乱码问题
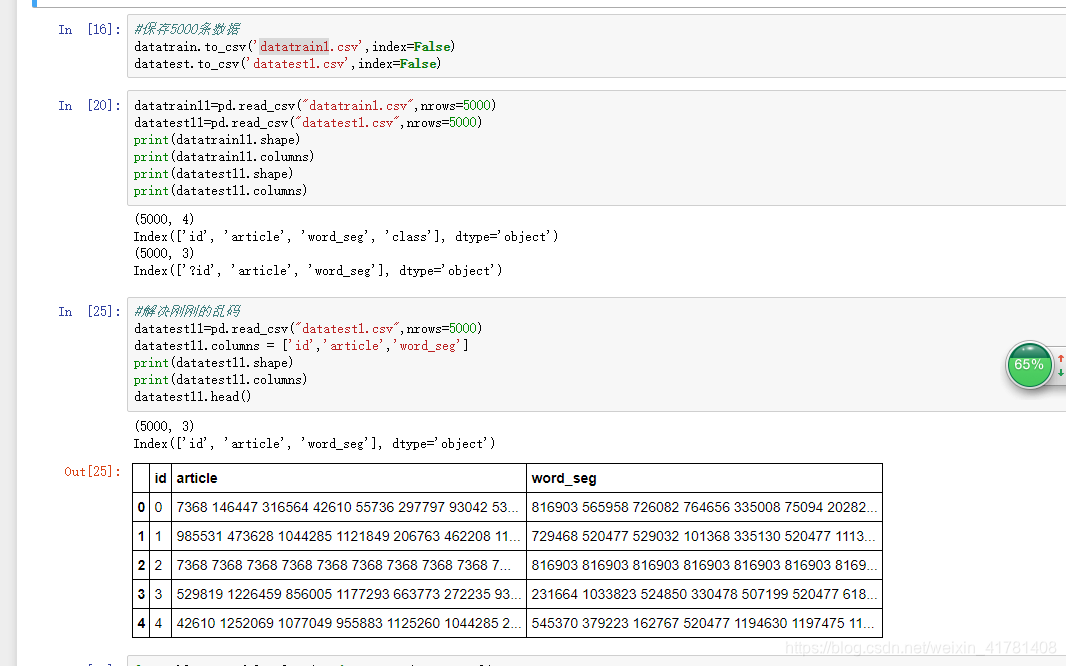
4.清除无用数据并将数据shuffle一下
