数据竞赛-“达观杯”文本智能处理-Day6:模型优化
【Task4 模型优化】:
1)进一步通过网格搜索法对3个模型进行调优(用5000条数据,调参时采用五折交叉验证的方式),并进行模型评估,展示代码的运行结果。(可以尝试使用其他模型)
2)模型融合,模型融合方式任意,并结合之前的任务给出你的最优结果。
- 例如Stacking融合,用你目前评分最高的模型作为基准模型,和其他模型进行stacking融合,得到最终模型及评分结果。
结果展示如下表:
| 模型 | 最优参数 | F1评分 |
|---|---|---|
| LR | {‘C’: 100} | 0.74 |
| SVM | {‘gamma’: 0.1, ‘C’: 100} | 0.73 |
| LightGBM | {‘gamma’: 0.001, ‘C’: 0.001} | 0.65 |
| 最优结果 | {‘gamma’: 0.01, ‘C’: 100} | 0.75 |
1.网格搜索法(Grid Search)
网格搜索算法是一种通过遍历给定的参数组合来优化模型表现的方法。
为什么叫网格搜索?以有两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索。
2.交叉验证
“交叉验证法"先将数据集D划分为k个大小相似的互斥子集,即D1 U D2 U…U Dk, Di n Dj = ø ( í != j).每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到.然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集;这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值。显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为强调这一点,通常把交叉验证法称为"k折交叉验证”.k最常用的取值是10,此时称为10折交叉验证;其他常用的k有5、20等。
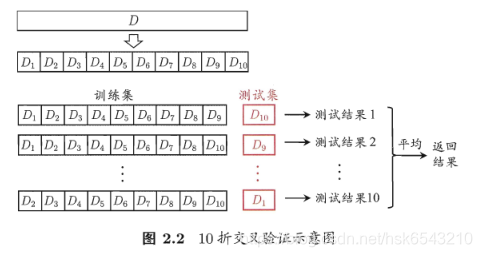
为减小因样本划分不同而引入的差别,k折交叉验证通常要随机使用不同的划分重复p次,最终的评估结果是这p次k折交叉验证结果的均值,例如常见的有" 10次10折交叉验证”。
3.模型调参
#读取特征
import time
import pickle
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix,f1_score
from sklearn.model_selection import cross_val_score
import lightgbm as lgb
import xgboost as xgb
features_path = './feature/feature_file/data_w_tfidf.pkl'#tfidf特征的路径
fp = open(features_path, 'rb')
x_train, y_train, x_test = pickle.load(fp)
fp.close()
X_train, X_test, Y_train, Y_test = train_test_split(x_train, y_train, test_size=0.3, random_state=2019)
# LR
t_start = time.time()
best_score = 0.0
# for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
log_model = LogisticRegression(C=C,random_state =2019)
scores = cross_val_score(log_model,X_train,Y_train,cv=5) #5折交叉验证
score = scores.mean() #取平均数
if score > best_score:
best_score = score
best_parameters = {"C":C}
log_model = LogisticRegression(**best_parameters)
log_model.fit(X_train,Y_train)
test_score = log_model.score(X_test,Y_test)
print("Best score on validation set:{:.2f}".format(best_score))
print("Best parameters:{}".format(best_parameters))
print("Score on testing set:{:.2f}".format(test_score))
t_end = time.time()
print("训练结束,耗时:{}min".format((t_end - t_start) / 60))
LogisticRegression(C=100, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
Best score on validation set:0.70
Best parameters:{'C': 100}
Score on testing set:0.74
训练结束,耗时:3.092217266559601min
# svm
t_start = time.time()
best_score = 0.0
for gamma in [0.001,0.1]:
for C in [10,100]:
svm = SVC(gamma=gamma,C=C,random_state =2019)
scores = cross_val_score(svm,X_train,Y_train,cv=5) #5折交叉验证
score = scores.mean() #取平均数
if score > best_score:
best_score = score
best_parameters = {"gamma":gamma,"C":C}
svm = SVC(**best_parameters)
svm.fit(X_train,Y_train)
test_score = svm.score(X_test,Y_test)
print("Best score on validation set:{:.2f}".format(best_score))
print("Best parameters:{}".format(best_parameters))
print("Score on testing set:{:.2f}".format(test_score))
t_end = time.time()
print("训练结束,耗时:{}min".format((t_end - t_start) / 60))
SVC(C=100, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.1, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Best score on validation set:0.68
Best parameters:{'gamma': 0.1, 'C': 100}
Score on testing set:0.73
训练结束,耗时:26.319817582766216min
# lightGBM
t_start = time.time()
best_score = 0.0
# lgb_model = LGBMClassifier()
for gamma in [0.001,0.01]:
for C in [0.001,0.01,]:
# for gamma in [0.001,0.01,0.1,1,10,100]:
# for C in [0.001,0.01,0.1,1,10,100]:
lgb_model = lgb.LGBMClassifier(gamma=gamma,C=C,random_state =2019)
scores = cross_val_score(svm,X_train,Y_train,cv=5) #5折交叉验证
score = scores.mean() #取平均数
if score > best_score:
best_score = score
best_parameters = {"gamma":gamma,"C":C}
lgb_model = lgb.LGBMClassifier(**best_parameters)
lgb_model.fit(X_train,Y_train)
test_score = lgb_model.score(X_test,Y_test)
print("Best score on validation set:{:.2f}".format(best_score))
print("Best parameters:{}".format(best_parameters))
print("Score on testing set:{:.2f}".format(test_score))
t_end = time.time()
print("训练结束,耗时:{}min".format((t_end - t_start) / 60))
LGBMClassifier(C=0.001, boosting_type='gbdt', class_weight=None,
colsample_bytree=1.0, gamma=0.001, importance_type='split',
learning_rate=0.1, max_depth=-1, min_child_samples=20,
min_child_weight=0.001, min_split_gain=0.0, n_estimators=100,
n_jobs=-1, num_leaves=31, objective=None, random_state=None,
reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0,
subsample_for_bin=200000, subsample_freq=0)
Best score on validation set:0.68
Best parameters:{'gamma': 0.001, 'C': 0.001}
Score on testing set:0.65
训练结束,耗时:28.898845402399697min
4.模型融合
a) Voting
从最简单的Voting说起,这也可以说是一种模型融合。假设对于一个二分类问题,有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。
b) Averaging
对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6
这两种方法看似简单,其实后面的高级算法也可以说是基于此而产生的,Bagging或者Boosting都是一种把许多弱分类器这样融合成强分类器的思想。
c) Bagging
Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。大概分为这样两步:
- 重复K次
- 有放回地重复抽样建模
- 训练子模型
2.模型融合
- 分类问题:voting
- 回归问题:average
Bagging算法不用我们自己实现,随机森林就是基于Bagging算法的一个典型例子,采用的基分类器是决策树。R和python都集成好了,直接调用。
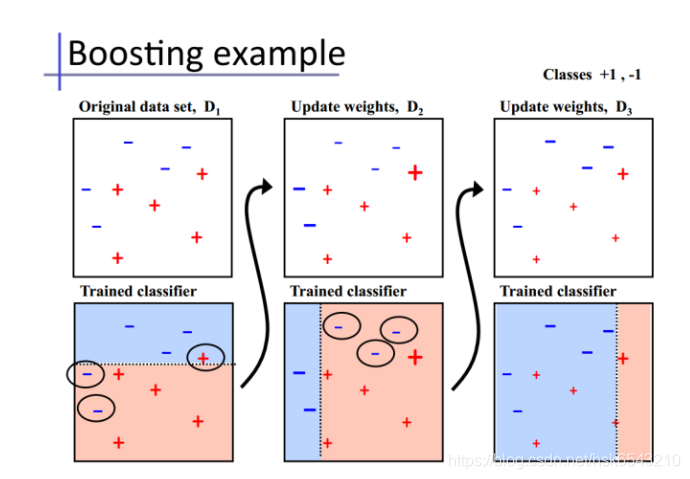
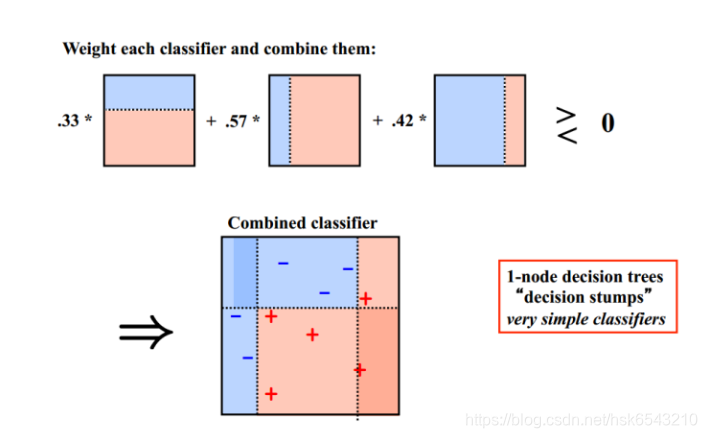
d) Boosting
Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
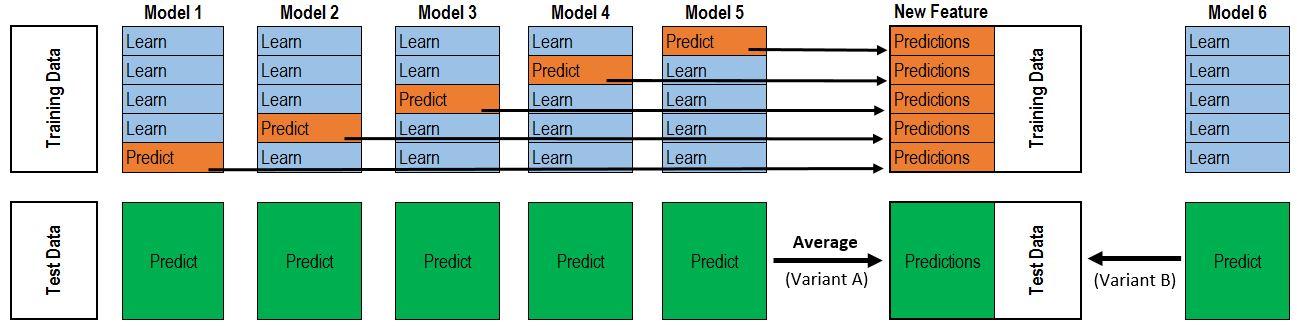
e) Stacking
#读取特征
# from sklearn.feature_selection import SelectFromModel
# from sklearn.linear_model import LogisticRegression
# from sklearn.svm import LinearSVC
# from sklearn.svm import SVC
# from sklearn.metrics import confusion_matrix,f1_score
# from sklearn.model_selection import cross_val_score
# import lightgbm as lgb
# import xgboost as xgb
import time
import pandas as pd
import numpy as np
import sys
import pickle
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
import xgboost as xgb
from xgboost import XGBClassifier
import lightgbm as lgb
from lightgbm import LGBMClassifier
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_validate
from mlxtend.classifier import StackingClassifier
features_path = './feature/feature_file/data_w_tfidf.pkl'#tfidf特征的路径
fp = open(features_path, 'rb')
x_train, y_train, x_test = pickle.load(fp)
fp.close()
X_train, X_test, Y_train, Y_test = train_test_split(x_train, y_train, test_size=0.3, random_state=2019)
lr = LogisticRegression(random_state=2019,C=0.1)
lgb = LGBMClassifier(boosting_type='GBDT',random_state=2019,silent=0)
gbdt = GradientBoostingClassifier(random_state=2019,max_depth=3,n_estimators=50)
xgbc = XGBClassifier(random_state=2019,max_depth=3,eta=0.1,subsample=0.6)
rf = RandomForestClassifier(n_estimators=500,oob_score=True, random_state=2019)
svm = SVC(random_state=2019,tol=0.01)
sclf = StackingClassifier(classifiers=[lr, gbdt, xgbc,rf,svm], meta_classifier=lgb)
# sclf1 = StackingClassifier(classifiers=[gbdt, xgbc,svm], meta_classifier=lgb)
# sclf2 = StackingClassifier(classifiers=[gbdt, xgbc,svm], meta_classifier=lr)
# sclf3 = StackingClassifier(classifiers=[svm], meta_classifier=lr)
def get_scores(model, X_train, X_test, Y_train, Y_test):
model.fit(X_train, Y_train)
y_train_predict = model.predict(X_train)
y_test_predict = model.predict(X_test)
if hasattr(model, "decision_function"):
y_train_proba = model.decision_function(X_train)
y_test_proba = model.decision_function(X_test)
else:
y_train_proba = (model.predict_proba(X_train))[:, 1]
y_test_proba = (model.predict_proba(X_test))[:, 1]
# accuracy
train_accuracy = metrics.accuracy_score(Y_train, y_train_predict, average="micro")
test_accuracy = metrics.accuracy_score(Y_test, y_test_predict, average="micro")
# recision
train_precision = metrics.precision_score(Y_train, y_train_predict, average="micro")
test_precision = metrics.precision_score(Y_test, y_test_predict, average="micro")
# recall
train_recall = metrics.recall_score(Y_train, y_train_predict, average="micro")
test_recall = metrics.recall_score(Y_test, y_test_predict, average="micro")
# f1-score
train_f1 = metrics.f1_score(Y_train, y_train_predict, average="micro")
test_f1 = metrics.f1_score(Y_test, y_test_predict, average="micro")
# auc
train_auc = metrics.roc_auc_score(Y_train, y_train_proba)
test_auc = metrics.roc_auc_score(Y_test, y_test_proba)
# roc 曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(Y_train, y_train_proba)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(Y_test, y_test_proba)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
#输出各种得分
print("训练集准确率:", train_accuracy)
print("测试集准确率:", test_accuracy)
print("==================================")
print("训练集精准率:", train_precision)
print("测试集精准率:", test_precision)
print("==================================")
print("训练集召回率:", train_recall)
print("测试集召回率:", test_recall)
print("==================================")
print("训练集F1-score:", train_f1)
print("测试集F1-score:", test_f1)
print("==================================")
print("训练集AUC:", train_auc)
print("测试集AUC:", test_auc)
t_start = time.time()
get_scores(sclf, X_train, X_test, Y_train, Y_test)
print("训练结束,耗时:{}min".format((t_end - t_start) / 60))
参考文献: