SenseTime出品
来源:https://arxiv.org/pdf/1712.05896.pdf
基于印象机制的高效多帧特征融合,解决defocus and motion
blur等问题(即视频中某帧的质量低的问题),同时提高速度和性能。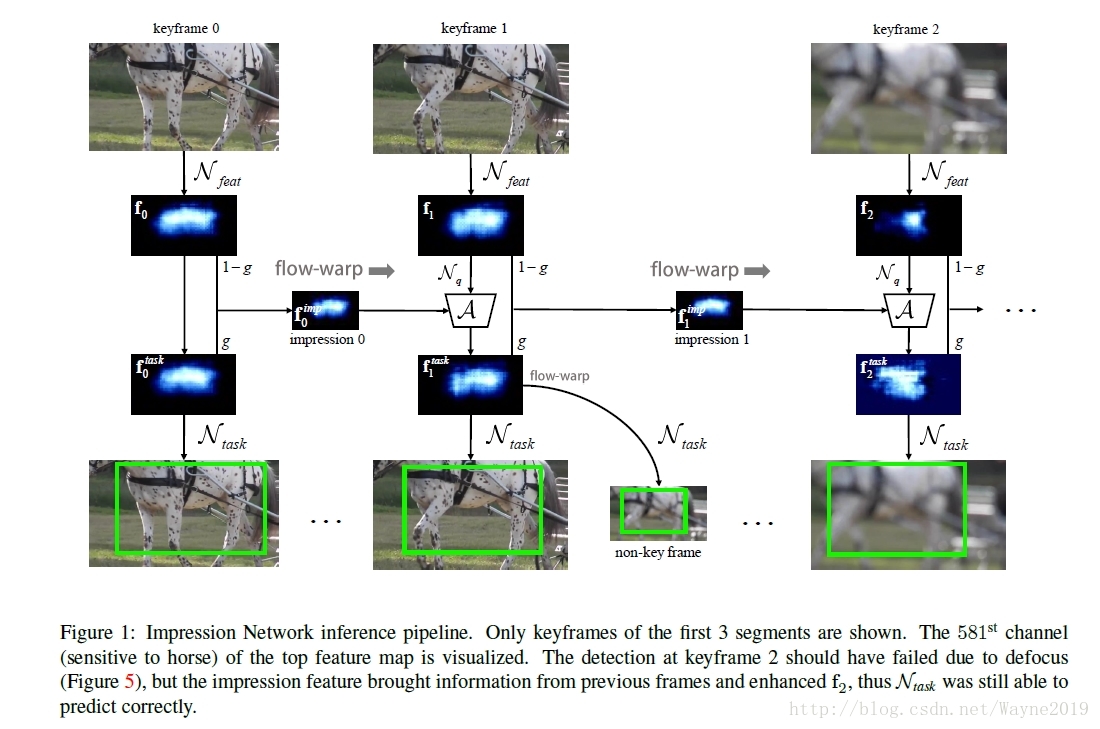
类似TSN,每个segment选一个key frame(注意,TSN做视频分类是在cnn最后才融合不同的segments)。特征融合前需要用Optical flow(FlowNet-S)来对齐。
目前使用的是fixed segment length,联想Deep Alternative Neural Network使用的自适应视频分段方法。
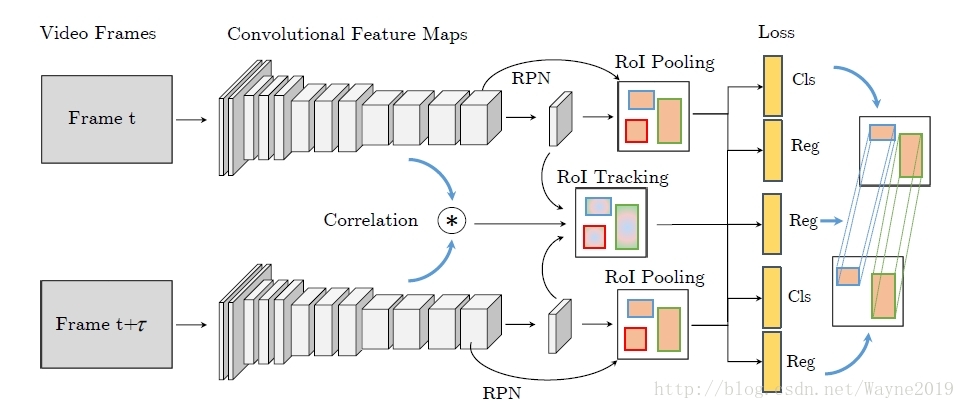
Detect to Track and Track to Detect
思考:track是不是可以代替印象网络中的光流来自动做对齐?
Mobile Video Object Detection with Temporally-Aware Feature Maps 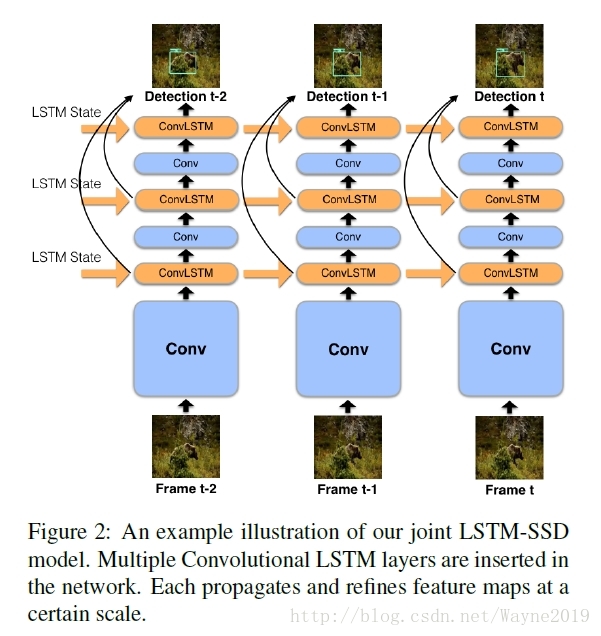
哈哈,看来帧间特征的关联就是光流,TSN,印象机制,RNN,3d conv这几种常见办法了。
注意这里用的是卷积LSTM!且改进成了高效的Bottleneck-LSTM:
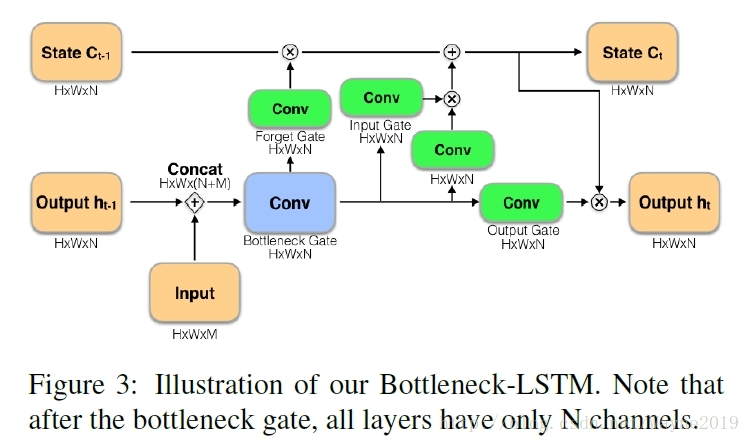
Spatial-Temporal Memory Networks for Video Object Detection
也是为了通过简单的帧来加强质量差的帧:

记忆机制(是不是和印象机制差不多?):
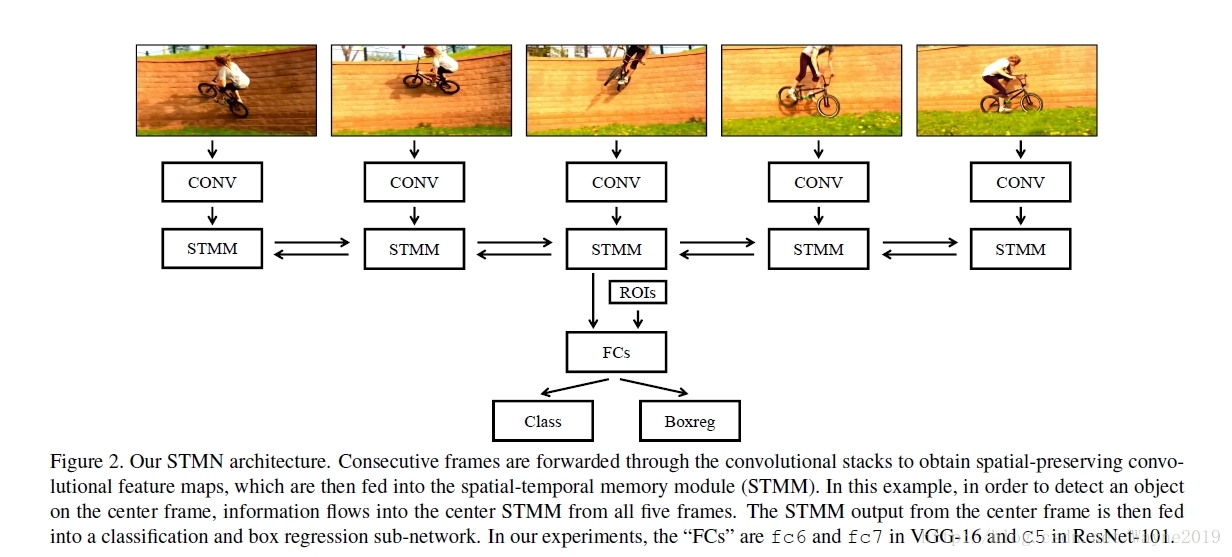
STMM是ConvGRU的改进,以更好地利用ImageNet预训练权重。
使用更高效的MatchTrans module来对齐帧间的特征(而不是光流。可以看出最近的文章思路都很像==),大概是基于近邻的思路。
动作分类中记忆机制会不会比TSN好,是否需要做对齐?
Towards High Performance Video Object Detection
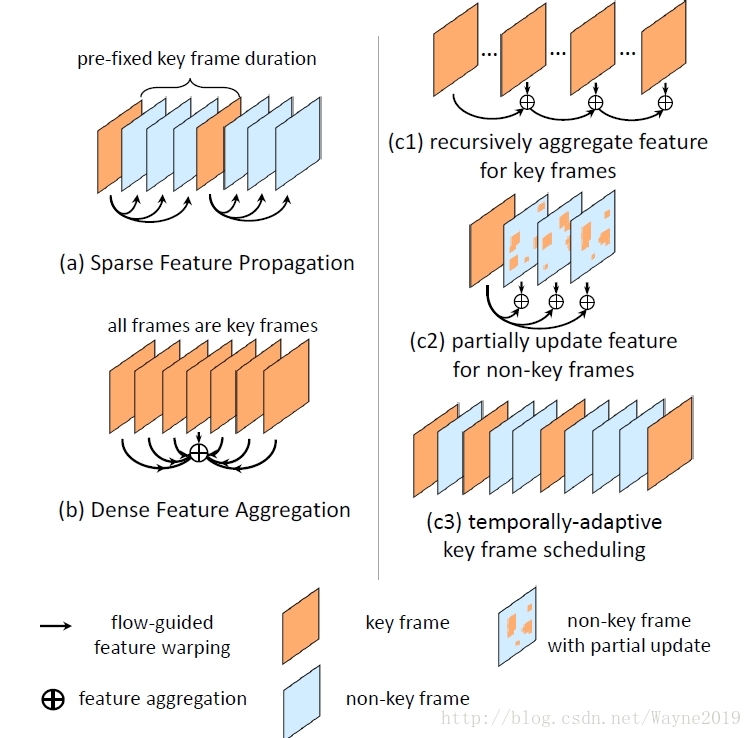
路子和印象机制那篇很像,也是稀疏的特征传递,用flow对齐。好像方法更精致一些(虽然论文好像上传的很仓促,是因为最近太多类似工作上传了吗?)?比如对key frame进行了自适应?、
参考:
【1】https://blog.csdn.net/wayne2019/article/category/7077174