来自清华的一篇文章,发表在ECCV2018上,是对FGFA做的改进。
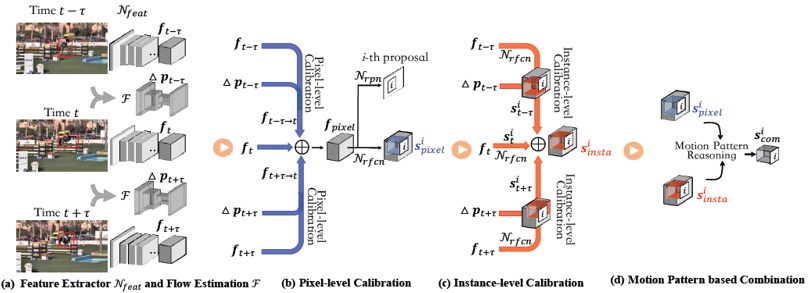
针对R-FCN这一目标检测算法做出的专有改进,目前看来这个方法只适合用在R-FCN,无法迁移到其他目标检测算法,如faster rcnn、SSD等。
具体的做法是这样的,FGFA就是图中左半部分,分别提取相邻帧的图片特征,并用光流做对齐,这篇文章有意思的点在于他对多帧特征进行的是求和去平均值,
没用加权平均,作者称直接取平均得到的结果和加权平均相差不大,还能减少计算量。作者称左边这一步为像素级的对齐。右边是作者提出的实例级的对齐,将每一张图片的
特征送入检测网络,得到多个proposal的位置敏感图,再利用光流对得到的位置敏感图进行对齐,将对齐后的结果取平均做一个增强,达到了还不错的效果。

在VID上达到了78.1的mAP,但文章里没有提速度,感觉比FGFA会慢一些。