论文资源:https://arxiv.org/abs/1603.06937
一,总结概述
本文使用全卷积网络解决人体姿态分析问题,截至2016年5月,在MPII姿态分析竞赛中暂列榜首,PCKh(误差小于一半头高的样本比例)达到89.4%。与排名第二的CPM(Convolutiona Pose Machine)1方法相比,思路更明晰,网络更简洁。该论文体现了从模块到网络再到完整网络的设计思想。
使用的初级模块称为Residual Module,得名于其中的旁路相加结构。
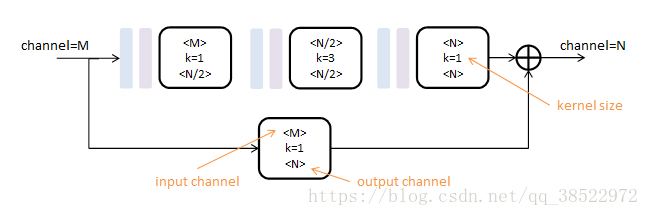
作用:Residual模块提取了较高层次的特征(卷积路),同时保留了原有层次的信息(跳级路)。不改变数据尺寸,只改变数据深度。可以把它看做一个保尺寸的高级“卷积”层。
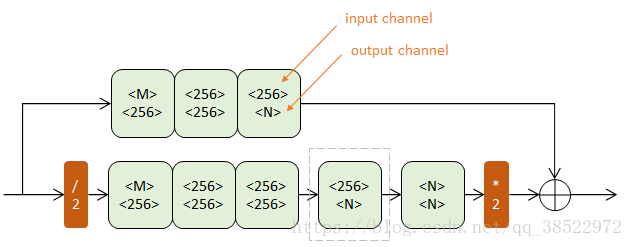
上下两个半路都包含若干Residual模块(浅绿),逐步提取更深层次特征。但上半路在原尺度进行,下半路经历了先降采样(红色/2)再升采样(红色*2)的过程。
降采样使用max pooling,升采样使用最近邻插值。n阶Hourglass子网络提取了从原始尺度到1/2 n 1/2n1/2^n尺度的特征。不改变数据尺寸,只改变数据深度。
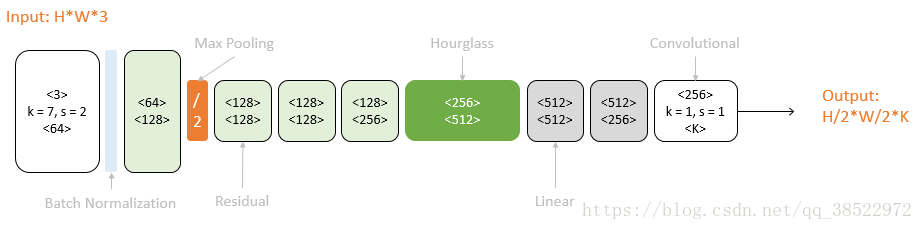
以一个Hourglass(深绿色)为中心,可以从彩色图像预测K个人体部件的响应图。原始图像经过一次降采样(橙色),输入到Hourglass子网络中。Hourglass的输出结果经过两个线性模块(灰色),得到最终响应图。期间使用Residual模块(浅绿)和卷积层(白色)逐步提取特征。而本文用的是以两个Hourglass(深绿色)为中心的二级网络。二级网络重复了一级网络的后半结构。第二个Hourglass的输入包含三路: 第一个Hourglass的输入数据 ,第一个Hourglass的输出数据 ,第一级预测结果 。这三路数据通过串接(concat)和相加进行融合,它们的尺度不同,体现了当下流行的跳级结构思想。如下图所示:


总结起来SHN的方法值得学习的地方有四点:使用模块进行网络设计 ,先降采样,再升采样的全卷积结构 , 跳级结构辅助升采样 ,中继监督训练。
评测数据集:在FLIC数据集上的[email protected]分别elbows(99%),elbows(97%)
二,论文翻译
摘要
这项工作介绍了一种新的卷积网络架构的任务人体姿势估计。特征在所有尺度上进行处理,并加以合并,以最好地捕捉与身体相关的各种空间关系。我们展示了如何结合中间监控来重复自底向上、自顶向下的处理对提高网络的性能至关重要。我们将架构称为“堆叠沙漏”网络,它基于池和上采样的连续步骤,这些步骤用于生成最终的预测集。最先进的结果是实现在FLIC和MPII基准竞争所有最近的方法。
1引言
在图像和视频中理解人物的关键步骤是准确的姿势估计。给定单个RGB图像,我们希望确定身体的重要关键点的精确像素位置。了解一个人的姿势和肢体清晰度对于高级任务如动作识别是有用的,而且在人机交互和动画领域也是基本的工具。
姿态估计是视觉领域中一个公认的问题,多年来一直困扰着研究人员,面临着各种严峻的挑战。一种好的姿势估计系统必须对遮挡和严重变形具有鲁棒性,对于稀有和新颖的姿态是成功的,并且对于服装和照明等因素引起的外观变化是不变的。早期的工作利用鲁棒的图像特征和复杂的结构化预测[1-9]解决了这些困难:前者用于产生局部解释,而后者用于推断全局一致的姿态。
然而,这种传统的管道已经被Curvu极大地改造了。人工神经网络(CuNETs)〔10—14〕,爆炸发展后的主要驱动力在许多计算机视觉任务中提高性能。最近的姿态估计系统[15-20]已经普遍采用ConvNets作为它们的主要构建块,在很大程度上取代了手工制作的特征和图形模型;这种策略已经对标准基准[1,21,22]产生了巨大的改进。
我们沿着这条轨迹继续前进,引入了一个新的“堆积沙漏”。 人体姿势预测的网络设计网络捕获和整合图像的所有尺度的信息。我们将该设计称为沙漏,基于我们对用于获得网络最终输出的汇集和后续上采样步骤的可视化。像许多产生像素级输出的卷积方法一样,沙漏网络汇聚到一个非常低的分辨率,然后对多个分辨率的特征进行上采样和组合[15,23]。另一方面,沙漏不同于先前的设计,主要是在其更对称的拓扑结构中。
我们通过连续放置多个沙漏,在一个沙漏上展开。模块一起端到端。这允许重复的自下而上、自上而下的跨尺度推理。结合中间监督的使用,重复的双向推理对网络的最终性能是至关重要的。最终的网络体系结构实现了对两个标准姿态估计基准(FLIC[1]和MPI Human Pos)的最新状态的显著改进。E〔21〕。在MPII上,所有接头的平均精度都有超过2%的提高,而对于更困难的接头则有高达4-5%的提高。就像膝盖和脚踝一样。
2相关工作
随着ToeHeV等对于“DeepPose”的引进介绍。〔24〕人类研究姿态估计开始从经典方法(1—9)转移到深度网络。使用他们的网络直接回归关节的X,Y坐标。[15]取而代之的是,通过并行地通过多个分辨率库运行图像以同时捕获各种尺度的特征来生成热图。我们的网络设计主要基于他们的工作,探索如何跨比例尺捕获信息,并调整他们的方法以结合不同分辨率的特征。
Tompson等人提出的方法的一个关键特征。〔15〕是节理使用VANNET和图形模型。他们的图形模型学习典型关节间的空间关系。其他人最近以类似的方式[17、20、25]解决了这个问题,对如何生成单项评分和对相邻关节进行成对比较进行了修改。 Chen 等人。[25]将检测聚类为典型方向,以便当分类器进行预测时,可获得指示相邻关节的可能位置的附加信息。在没有使用图形模型或任何明确的人体建模的情况下,我们可以获得更好的性能。
有几个例子的方法进行连续预测姿态估计。 Carreira等。[19]使用他们所谓的迭代错误反馈。输入中包括一组预测,每个通过网络的预测进一步细化这些预测。他们的方法需要多阶段训练,并且在每次迭代中共享权重。 Wei等。〔18〕基于多姿态机器(26)的工作,但现在采用了特征提取的神经网络。考虑到我们使用了中间监督,我们的工作在精神上与这些方法相似,但是我们的构建块(沙漏模块)是不同的。Hu&Ramanan[27]的架构更类似于我们的架构,也可以用于多个预测阶段,但是它们的模型将自下而上和自上而下的计算部分以及跨迭代的权重联系起来。
Tompson等人。建立在他们的工作在[ 15 ]级联改进预测。这有助于提高效率并减少其方法的内存使用,同时在高精度范围内改善定位性能[16]。一个考虑因素是,对于许多故障情况,局部窗口内的位置细化不会提供很大的改进,因为错误情况通常由闭塞或错误属性肢体组成。对于这两种情况,任何在局部尺度上的进一步评估都不会改善预测。
姿势估计问题有变化,包括使用额外的特征,如深度或运动线索。〔28—30〕也有 多人同时标注更具挑战性的任务〔17, 31〕。此外, Oliveira等人也有类似的工作。〔32〕基于完全卷积网络进行人类部分分割[23 ]。我们的工作仅集中于从RGB图像中的单个人的姿势的关键点定位的任务。
我们在叠加之前的沙漏模块与全卷积网络[23]和其他设计紧密相连,这些设计在多个尺度上处理空间信息以便进行密集预测[15,33-41]。谢等。〔33〕对典型体系结构进行了总结。我们的沙漏模块不同于这些设计,主要在于它在自底向上处理(从高分辨率到低分辨率)和自顶向下处理(从低分辨率到高分辨率)之间的更对称的容量分布。例如,完全卷积网络[23]和整体嵌套架构[33]在自底向上处理中都很重,但在自顶向下处理中却很轻,这仅包括跨多个尺度的预测的(加权)合并。完全卷积网络也被训练在多个阶段。
堆叠前的沙漏模块也与CONV DECONV和 编码器解码器结构〔42—45〕。Noh等。〔42〕使用CONV DECONV体系结构进行语义分割,ReMAAS等。〔44〕用它来预测物体的反射图。Zhao等。[43]通过增加重构损失,为有监督、无监督和半监督学习建立一个统一的框架,Yang 。〔46〕采用无编码连接的编码器解码器结构来进行图像生成。 Rasmus等人。[47]提出一种用于无监督/半监督特征学习的具有特殊“调制”跳过连接的去噪自动编码器。这些网络的对称拓扑是相似的,但其本质是操作是非常不同的,因为我们不使用unPoLoin或DENONV层。相反,我们依赖简单的最近邻上采样和跳过连接进行自顶向下处理。我们的工作的另一个主要区别是我们通过堆叠多个沙漏来执行重复的自下而上、自上而下的推理。
3网络体系结构
3.1沙漏设计
沙漏的设计是因为需要捕捉信息 每一个尺度。虽然局部证据对于识别面部特征和层叠沙漏网络对于人体姿势估计5只手来说是必不可少的,但是最终的姿势估计需要对整个身体有一个连贯的理解。NT关节是在图像中不同尺度下最好识别的许多线索之一。沙漏是一个简单的、最小的设计,它具有捕获所有这些特征并将它们结合在一起输出像素级预测的能力。 网络必须有一些机制来有效地处理和巩固跨尺度的特征。一些方法通过使用独立的流水线来解决这个问题,该流水线以多分辨率独立地处理图像,并在稍后在网络中组合特征[15,18]。相反,我们选择使用具有跳跃层的单个管道来保存每个分辨率的空间信息。该网络在4x4像素处达到其最低分辨率,允许应用更小的空间滤波器,以比较图像整个空间的特征。
沙漏设置如下:卷积层和最大池层用于将特征处理到非常低的分辨率。在每个最大池步骤中,网络分支并在原来的预合并分辨率上应用更多的卷积。在达到最低的分辨率之后,网络开始自上而下的跨比例尺的上采样和特征组合序列。为了将信息融合在两个相邻的分辨率上,我们遵循汤普生等人描述的过程。〔15〕并以较低的分辨率进行最近邻上采样,然后对两组特征进行元素叠加。沙漏的拓扑结构是对称的,所以在向下的每一层上都存在相应的层。 在达到网络的输出分辨率后,连续两个回合 应用1x1卷积来产生最终的网络预测。这个网络的输出是一组热图,其中对于给定的热图,网络预测每个像素处联合存在的概率。完整的模块(不包括最终的1x1层)如图3所示。
3.2 层的实现
在保持整体沙漏形状的同时,在层的具体实现中仍然有一些灵活性。不同的选择会对网络的最终表现和训练产生适中的影响。我们探索在我们的网络层设计的几种选择。最近的工作显示了具有1x1卷积的缩减步骤的价值,以及使用连续较小的滤波器捕获更大空间上下文的好处。〔12, 14〕例如,可以用两个独立的3x3滤波器代替5x5滤波器。我们测试了我们的整体网络设计,基于这些洞察力交换在不同的层模块。在从具有大滤波器且没有减少步骤的标准卷积层切换到诸如He等人提出的剩余学习模块之类的较新方法之后,网络性能得到了提高。[14]以及基于“初始”的设计[12]。在这些类型的设计的初始性能改进之后,对层的各种附加探索和修改对进一步提高性能几乎没有作用。表现或训练时间。
我们的最终设计广泛使用残余模块。过滤器更大不使用3x3,瓶颈限制了总数。 每个层的参数缩减总内存使用量。在我们的网络中使用的模块如图4所示。为了把它放到整个网络设计的上下文中,图3中的每个框代表一个单一的残差模块。
在256x256的全输入分辨率下操作需要大量的GPU内存,所以沙漏的最高分辨率(因此也是最终的) 输出分辨率为64×64。这并不影响网络产生精确联合预测的能力。整个网络从7x7卷积层开始,步长为2,接着是剩余模块和最大池循环,以便将分辨率从256降低到64。两个后续残差模块出现在图3所示的沙漏中。在整个沙漏中,所有残差模块输出256个特征。
3.3层沙漏中间监督
通过端到端地堆叠多个沙漏,我们将网络架构进一步细化,将一个沙漏的输出作为输入提供给下一个沙漏。这提供了具有用于重复自底向上、自顶向下的推理的机制的网络,允许在整个图像上重新评估初始估计和特征。这种方法的关键是预测我们可以应用损失的中间群体。预测是在通过每个沙漏之后生成的,其中网络有机会在本地和全局上下文中处理特性。随后的沙漏模块允许再次处理这些高级特征,以进一步评估和重新评估高阶空间关系。这与其他姿态估计方法类似,这些姿态估计方法在多个迭代阶段和中间监督下表现出很强的性能[18,19,30]。
仅限于使用中间监管的局限性单沙漏模块。什么是合适的地方,在管道中产生一套初步的预测?大多数高阶特征只存在于较低的分辨率,除了在上采样发生时的末尾。如果在网络进行上采样之后提供监控,则无法在更大的全球堆叠沙漏网络用于人体姿态估计7上下文中对这些特征进行相对重新评估。如果我们希望网络能够最好地预测预测,那么这些预测不能只在局部尺度上进行评估。与其他关节的关系预测,以及一般的背景和理解的完整形象是至关重要的。在汇集之前在流水线中更早地应用监视是可能的,但是在这点上,给定像素的特征是处理相对局部接收字段的结果,因此忽略关键的全局提示。
重复的自下而上,自上而下的推理与堆叠沙漏缓解这些担忧。局部和全局线索被集成在每个沙漏模块中,并且要求网络产生早期预测要求它在仅通过整个网络的一半时对图像有高层次的理解。自下而上、自上而下处理的后续阶段允许对这些特征进行更深层次的重新考虑。
这种在比例尺之间来回移动的方法特别重要,因为保持特征的空间位置对于完成最后的定位步骤是必不可少的。关节的精确位置是由网络作出的其他决定不可缺少的线索。对于像姿态估计这样的结构化问题,输出是许多不同特征的相互作用,这些特征应该结合在一起形成对场景的一致理解。相互矛盾的证据和解剖学上的不可能性是造成错误的主要原因,通过往返网络,可以保持精确的局部信息,同时考虑和再考虑特征的整体一致性。
通过将中间预测映射到具有附加1x1卷积的大量通道,我们将中间预测重新集成到特征空间中。图4)。所得到的输出直接用作后续沙漏模块的输入,该模块产生另一组预测。在最终的网络设计中,使用了八个沙漏。重要的是要注意,权重不是在沙漏模块之间共享的,并且损耗被应用于使用相同地面事实的所有沙漏的预测。损失和地面真相的细节
3.4训练细节
我们评估我们的网络上的两个基准数据集,FLIC〔1〕和MPII人类姿势〔21〕。FLIC由5003张图像(3987次训练,1016次测试)组成。图像被标注在上身上,大多数数字对着相机笔直。MPII人体姿态由大约25k张图像组成,为多人提供40k注释样本(28k训练,11k测试)。没有提供测试注释,因此在我们的所有实验中,我们在训练图像的子集上进行训练,同时评估大约3000个样本的高效验证集。MPII包括从广泛的人类活动拍摄的图像,具有挑战性的一系列广泛连接的全身姿势。
在给定的输入图像中经常可见多个人,但没有图形模型或其他后处理步骤,图像必须传送所有必要的信息,以便网络确定哪些人值得注释。我们通过训练网络来专门注释直接中心的人。这是在FLIC中根据.obox注释沿着x轴对中完成的,没有进行垂直调整或比例归一化。对于MPII,利用所有图像提供的比例和中心注释是标准的。对于每个样本,这些值用于裁剪目标人周围的图像。然后将所有输入图像调整为256x256像素。我们做数据增强,包括旋转(+/- 30度)和缩放(.75-1.25)。我们避免图像的平移增强,因为目标人物的位置是决定谁应该被网络注释的关键线索。
使用Torch 7[ 48 ]对网络进行训练,并使用RMSPROP进行优化。〔49〕学习率为2.5E-4。培训花费约3天12 GB Nvidia Ti'tanX GPU。我们把学习率降低了5倍。 验证精度平台。批量标准化(13)也用于改进培训。网络的单次前向通过需要75ms。为了生成最终的测试预测,我们通过网络运行图像的原始输入和翻转版本,并将热图平均在一起(在验证方面平均提高了1%)。网络的最终预测是给定关节的热图的最大激活位置。
与Tompson等同样的技术。〔15〕用于监督。应用均方误差(MSE)损失将预测热图与由以关节位置为中心的2D高斯(标准偏差为1px)组成的地真热图进行比较。为了提高在高精度阈值下的性能,在转换回图像的原始坐标空间之前,预测在其下一个最高邻居的方向上偏移四分之一像素。在MPII人体姿态中,一些关节没有对应的地面实况标注。在这些情况下,关节要么被截断,要么被严重阻塞,因此为了监视,提供了所有零点的地面真值热图。
4结果
4.1评价
使用标准关键点(PCK)的标准百分比进行评价。 度量在标准化范围内的检测百分比的度量 地面真相的距离。对于FLIC,距离由躯干大小和MPII归一化,由头部大小的一部分(称为PCKh)来表示。
FLIC:结果见图6和表1。我们在FLIC上的结果是非常有竞争力的达到99% PCK @ 0.2肘精度,97%手腕。重要的是要注意的是,这些结果是以观察者为中心的。 与其他人在FLIC上评估他们的输出是一致的。
MPII:我们在MPII Hu上的所有关节上都取得了最先进的结果?人体姿态数据集。所有数字都可以在表2中看到,如图7中的PCK曲线。对于手腕、手肘、膝盖和脚踝等困难的关节,我们根据最新的最新研究结果平均提高了3.5%([email protected]),平均错误率从16.3%下降到12.8%。最终肘关节准确度为91.2%,腕关节准确度为87.1%。在图5中可以看到网络对MPII的示例性预测。
4.2烧蚀实验
本文探讨了两种主要的设计方案:沙漏模块叠加的效果和中间监督的影响。这些不是相互独立的,因为我们在如何根据总体建筑设计应用中间监督方面受到限制。分别应用,每个对性能都有积极的影响,并且一起我们看到训练速度的进一步提高,最终的姿态估计性能。其结果可以在图8中看出,它显示了有效性的平均精度。设置为培训进展。精度度量考虑了所有关节,不包括那些与头部和躯干相关的关节,以允许在实验中更容易区分。
首先,为了探索层叠沙漏设计的效果,我们必须证明性能的变化是体系结构形状的函数,而不是由于更大、更深的网络的容量的增加。为了使这种比较,我们从基线网络组成的八个沙漏模块堆叠在一起。每个沙漏在每个分辨率中都有一个残差模块,如图3所示。我们可以把这些层混在一起进行各种网络安排。沙漏数量的减少会导致每个沙漏的容量增加。例如,相应的网络可以堆叠四个沙漏,并且在每个分辨率下具有两个连续的剩余模块(或者两个沙漏和四个剩余模块)。这说明了 图9。所有网络共享相同数量的参数和层,但是当应用更多的中间监控时略有不同。
为了看到这些选择的效果,我们首先比较两个堆叠网络。在沙漏中的每个阶段有四个残留模块,一个沙漏,但有八个残留模块。在图8中,这些分别被称为Hg堆叠和HG。当使用层叠设计时,尽管具有近似相同的层数和参数,但在训练上可以看到轻微的改进。接下来,我们考虑中间监管的影响。对于两个栈网络,我们遵循本文中所描述的应用监督的过程。在单个沙漏上应用相同的思想是不容易的,因为高阶全局特征只在较低分辨率下出现,并且跨尺度的特征直到流水线后期才被组合。我们探索在网络中的各个点上应用监控,例如在汇集之前或之后,以及以各种分辨率应用监控。最佳性能方法如图8中的HG-Int所示,在最终输出分辨率之前的下两个最高分辨率上采样后应用中间监控。包含(Hg堆栈INT)。
在图9中,我们比较2个、4个和8个堆栈模型的验证精度,它们共享大致相同数量的参数,并且包括 他们中间预测的准确性。有一个适度的改善 最终的性能为每一次的叠加从87.4%增加到87.8%到88.1%。中间阶段的效果更显著。例如,在每个网络的中途,中间预测的相应精度是:84.6%、86.5%和87.1%。注意,在8栈网络中途的精度恰好短于2栈网络的最终精度。
观察早期犯的错误并事后改正是很有意思的。通过网络。几个例子在图9中被可视化。常见错误 出现像其他人的关节混淆,或左和右错误归因。对于运行的图形,从最后的热图中可以看出 左右之间的决策对于网络来说仍然有点模糊。鉴于形象的出现,混乱是有道理的。值得注意的一个例子是网络最初在图像中可见的手腕上激活的中间例子。在进一步处理之后,热图根本不激活原始位置,而是为阻塞的手腕选择合理的位置。
5进一步分析
5.1多人
当一幅图像里有多个人时相干问题变得尤为重要。 网络必须决定谁要注释,但是有什么限制的选项来沟通到底谁应该得到注释。 为了这项工作的目的,提供的唯一信号是对中。 信任输入足够清晰以供解析的目标人员的缩放。不幸的是,这有时会导致当人们非常接近在一起或者甚至重叠时出现模糊的情况,如图10所示。由于我们正在训练一个系统来生成单个人的姿态预测,所以在模糊情况下的理想输出将显示对仅一个数字的关节的承诺。即使预测的质量较低,这也会显示出对当前任务的更深入的理解。从姿势估计系统估计手腕的位置而不考虑手腕可能属于谁不是期望的行为。
图10中的结果来自MPII测试图像。网络必须 为男孩和女孩生成预测,并提供它们各自的中心和尺度注释。使用这些值来裁剪网络的输入图像,得到图的第一和第三幅图像。在720x1280图像中,两个舞蹈演员的中心注释仅减少了26个像素。从定性上讲,两个输入图像之间最明显的差异是尺度的变化。这种差异足以使网络完全改变其估计,并预测正确的图形的注释。
对多人的注释进行更全面的管理超出了这项工作的范围。系统的许多故障情况是混淆多人的关节的结果,但是在许多具有严重图形重叠的示例中,网络将适当地挑选单个图形进行注释是有希望的。
5.2缺陷
遮挡性能很难评估,因为它常常分为两个不同的类别。第一个由关节不可见的情况组成,但是它的位置在图像的背景下是明显的。MPII通常为这些关节提供地面真实位置,另外的注释表示它们缺乏可见性。另一方面,第二种情况发生时,绝对没有关于特定关节可能位于何处的信息。例如,只有人体的上半部才可见的图像。在MPII中,这些关节将不具有与它们相关联的地面实况注释。
我们的系统不使用额外的可见性注释,但是我们可以还是看一下能见度对性能的影响。大约75%的肘部和手腕带有注释,在我们保持的验证集中被标记为可见的。在图11中,我们将整个验证集上的平均性能与可见的四分之三的关节的性能以及不可见的其余四分之一的关节的性能进行比较。而只考虑可见关节时,腕部精度从85.5%提高到93.6%(验证性能略差于测试集性能87.1%)。另一方面,在专门的闭塞关节的性能是61.1%。对于肘关节,准确度从基线的90.5%至95.1%,可见关节和下降到74%的闭塞关节。闭塞显然是一个重大的挑战,但网络仍然作出强有力的估计在大多数情况下。在许多示例中,网络预测和地面真值注释可能不一致,同时两者都驻留在有效位置,并且图像的模糊性意味着没有办法确定哪个是真正正确的。
我们还考虑更极端的情况,其中关节可能严重闭塞或截断,因此根本没有注释。在评估姿态估计系统时使用的PCK度量不能反映网络对这些情况的识别程度。如果没有为关节提供地面真值注释,就不可能评估系统所作预测的质量,因此它不会计入最终报告的PCK值。或者完全闭塞或截断关节将毫无意义。对于在真实的系统中使用,一定程度的元知识是必不可少的,并且理解不能对特定的关节做出好的预测是非常重要的。我们观察到,我们的网络对联合是否可用地面真值注释给出了一致和准确的预测。
我们考虑脚踝和膝盖的分析,因为这些是闭塞的。大多数情况下。下肢经常被从图像中剪除,如果我们总是可视化我们网络的所有联合预测,鉴于在这些情况下做出的荒谬的下肢预测,示例姿态图看起来是不可接受的。为了筛选出这些情况的简单方法,我们检查在给定相应的热图激活的情况下,如何确定联合的注释的存在。我们考虑阈值的热图的最大值或其均值。在图11中可以看到相应的精度回忆曲线。我们发现,仅仅基于热图的平均激活,就有可能正确地评估具有92.1%AUC的膝盖注释和96.0%AUC的踝关节注释的存在。这是在2958个样本的验证集上完成的,其中16.1%的可能膝盖和28.4%的可能踝关节没有基本真理注释。这是一个有希望的结果,表明热图作为一个有用的信号,表明截断和严重遮挡在图像的情况。
6结论
我们展示了一个堆叠沙漏网络产生人体姿态估计的有效性。这个网络用一个简单的机制来处理一系列多样且具有挑战性的姿势,以便重新评估和评估初始预测。中间监督对于训练网络至关重要,在堆叠沙漏模块的背景下工作最佳。仍然存在网络不能完美处理的困难情况,但是总体来说,我们的系统显示出强大的性能来应对各种挑战,包括严重的遮挡和邻近的多个用户。
参考文献1. Sapp, B., Taskar, B.: Modec: Multimodal decomposable models for human pose
estimation. In: Computer Vision and Pattern Recognition (CVPR), 2013 IEEE
Conference on, IEEE (2013) 3674–3681
2. Felzenszwalb, P., McAllester, D., Ramanan, D.: A discriminatively trained, multi?scale, deformable part model. In: Computer Vision and Pattern Recognition, 2008.
CVPR 2008. IEEE Conference on, IEEE (2008) 1–8
3. Pishchulin, L., Andriluka, M., Gehler, P., Schiele, B.: Strong appearance and
expressive spatial models for human pose estimation. In: Computer Vision (ICCV),
2013 IEEE International Conference on, IEEE (2013) 3487–3494
4. Bourdev, L., Malik, J.: Poselets: Body part detectors trained using 3d human pose
annotations. In: Computer Vision, 2009 IEEE 12th International Conference on,
IEEE (2009) 1365–1372
5. Johnson, S., Everingham, M.: Learning effective human pose estimation from
inaccurate annotation. In: Computer Vision and Pattern Recognition (CVPR),
2011 IEEE Conference on, IEEE (2011) 1465–1472
6. Ramanan, D.: Learning to parse images of articulated objects. Advances in Neural
Information Processing Systems 134 (2006)
7. Yang, Y., Ramanan, D.: Articulated human detection with flexible mixtures of
parts. Pattern Analysis and Machine Intelligence, IEEE Transactions on 35(12)
(2013) 2878–2890
8. Ferrari, V., Marin-Jimenez, M., Zisserman, A.: Progressive search space reduction
for human pose estimation. In: Computer Vision and Pattern Recognition, 2008.
CVPR 2008. IEEE Conference on, IEEE (2008) 1–8
9. Ladicky, L., Torr, P.H., Zisserman, A.: Human pose estimation using a joint pixel?wise and part-wise formulation. In: Computer Vision and Pattern Recognition
(CVPR), 2013 IEEE Conference on, IEEE (2013) 3578–3585
10. LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied
to document recognition. Proceedings of the IEEE 86(11) (1998) 2278–2324
11. Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep con?volutional neural networks. In: Advances in neural information processing systems.
(2012) 1097–1105
12. Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D.,
Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings
of the IEEE Conference on Computer Vision and Pattern Recognition. (2015) 1–9
13. Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by
reducing internal covariate shift. Proceedings of the 32nd International Conference
on Machine Learning (2015)
14. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition.
Computer Vision and Pattern Recognition, 2016. CVPR 2016. IEEE Conference
on (2015)
15. Tompson, J.J., Jain, A., LeCun, Y., Bregler, C.: Joint training of a convolutional
network and a graphical model for human pose estimation. In: Advances in Neural
Information Processing Systems. (2014) 1799–1807
16. Tompson, J., Goroshin, R., Jain, A., LeCun, Y., Bregler, C.: Efficient object
localization using convolutional networks. In: Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition. (2015) 648–656
17. Pishchulin, L., Insafutdinov, E., Tang, S., Andres, B., Andriluka, M., Gehler, P.,
Schiele, B.: Deepcut: Joint subset partition and labeling for multi person pose
estimation. Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Con?ference on (2015)
18. Wei, S.E., Ramakrishna, V., Kanade, T., Sheikh, Y.: Convolutional pose machines.
Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on
(2016)
19. Carreira, J., Agrawal, P., Fragkiadaki, K., Malik, J.: Human pose estimation with
iterative error feedback. Computer Vision and Pattern Recognition (CVPR), 2016
IEEE Conference on (2016)
20. Fan, X., Zheng, K., Lin, Y., Wang, S.: Combining local appearance and holistic
view: Dual-source deep neural networks for human pose estimation. In: 2015 IEEE
Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2015)
1347–1355
21. Andriluka, M., Pishchulin, L., Gehler, P., Schiele, B.: 2d human pose estimation:
New benchmark and state of the art analysis. In: Computer Vision and Pattern
Recognition (CVPR), 2014 IEEE Conference on, IEEE (2014) 3686–3693
22. Johnson, S., Everingham, M.: Clustered pose and nonlinear appearance models for
human pose estimation. In: Proceedings of the British Machine Vision Conference.
(2010) doi:10.5244/C.24.12.
23. Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic
segmentation. In: Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition. (2015) 3431–3440
24. Toshev, A., Szegedy, C.: Deeppose: Human pose estimation via deep neural net?works. In: Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Con?ference on, IEEE (2014) 1653–1660
25. Chen, X., Yuille, A.: Articulated pose estimation by a graphical model with im?age dependent pairwise relations. In: Advances in Neural Information Processing
Systems (NIPS). (2014)
26. Ramakrishna, V., Munoz, D., Hebert, M., Bagnell, J.A., Sheikh, Y.: Pose machines:
Articulated pose estimation via inference machines. In: Computer Vision–ECCV
2014. Springer (2014) 33–47
27. Hu, P., Ramanan, D.: Bottom-up and top-down reasoning with hierarchical recti-
fied gaussians. In: Computer Vision and Pattern Recognition (CVPR), 2016 IEEE
Conference on, IEEE (2016)
28. Jain, A., Tompson, J., LeCun, Y., Bregler, C.: Modeep: A deep learning framework
using motion features for human pose estimation. In: Computer Vision–ACCV
2014. Springer (2014) 302–315
29. Shotton, J., Sharp, T., Kipman, A., Fitzgibbon, A., Finocchio, M., Blake, A.,
Cook, M., Moore, R.: Real-time human pose recognition in parts from single
depth images. Communications of the ACM 56(1) (2013) 116–124
30. Pfister, T., Charles, J., Zisserman, A.: Flowing convnets for human pose estimation
in videos. In: Proceedings of the IEEE International Conference on Computer
Vision. (2015) 1913–1921
31. Chen, X., Yuille, A.L.: Parsing occluded people by flexible compositions. In:
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
(2015) 3945–3954
32. Oliveira, G.L., Valada, A., Bollen, C., Burgard, W., Brox, T.: Deep learning for
human part discovery in images. In: IEEE International Conference on Robotics
and Automation (ICRA). (2016)
33. Xie, S., Tu, Z.: Holistically-nested edge detection. In: Proceedings of the IEEE
International Conference on Computer Vision. (2015) 1395–1403
34. Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image
using a multi-scale deep network. In: Advances in neural information processing
systems. (2014) 2366–2374
35. Farabet, C., Couprie, C., Najman, L., LeCun, Y.: Learning hierarchical features
for scene labeling. Pattern Analysis and Machine Intelligence, IEEE Transactions
on 35(8) (2013) 1915–1929
36. Pinheiro, P., Collobert, R.: Recurrent convolutional neural networks for scene
labeling. In: Proceedings of the 31st International Conference on Machine Learning
(ICML-14). (2014) 82–90
37. Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with
a common multi-scale convolutional architecture. In: Proceedings of the IEEE
International Conference on Computer Vision. (2015) 2650–2658
38. Mathieu, M., Couprie, C., LeCun, Y.: Deep multi-scale video prediction beyond
mean square error. International Conference on Learning Representations (ICLR)
(2016)
39. Couprie, C., Farabet, C., Najman, L., LeCun, Y.: Indoor semantic segmentation
using depth information. International Conference on Learning Representations
(ICLR) (2013)
40. Bertasius, G., Shi, J., Torresani, L.: Deepedge: A multi-scale bifurcated deep
network for top-down contour detection. In: Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition. (2015) 4380–4389
41. Hariharan, B., Arbel′aez, P., Girshick, R., Malik, J.: Hypercolumns for object
segmentation and fine-grained localization. In: Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition. (2015) 447–456
42. Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmen?tation. In: Proceedings of the IEEE International Conference on Computer Vision.
(2015) 1520–1528
43. Zhao, J., Mathieu, M., Goroshin, R., Lecun, Y.: Stacked what-where auto-encoders.
arXiv preprint arXiv:1506.02351 (2015)
44. Rematas, K., Ritschel, T., Fritz, M., Gavves, E., Tuytelaars, T.: Deep reflectance
maps. Computer Vision and Pattern Recognition, 2016. CVPR 2016. IEEE Con?ference on (2015)
45. Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolu?tional encoder-decoder architecture for image segmentation. arXiv preprint
arXiv:1511.00561 (2015)
46. Yang, J., Reed, S.E., Yang, M.H., Lee, H.: Weakly-supervised disentangling with
recurrent transformations for 3d view synthesis. In Cortes, C., Lawrence, N.D., Lee,
D.D., Sugiyama, M., Garnett, R., eds.: Advances in Neural Information Processing
Systems 28. Curran Associates, Inc. (2015) 1099–1107
47. Rasmus, A., Berglund, M., Honkala, M., Valpola, H., Raiko, T.: Semi-supervised
learning with ladder networks. In: Advances in Neural Information Processing
Systems. (2015) 3546–3554
48. Collobert, R., Kavukcuoglu, K., Farabet, C.: Torch7: A matlab-like environment
for machine learning. In: BigLearn, NIPS Workshop. (2011)
49. Tieleman, T., Hinton, G.: Lecture 6.5-rmsprop: Divide the gradient by a run?ning average of its recent magnitude. COURSERA: Neural Networks for Machine
Learning (2012)