提出BN的文献: Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. 32nd International Conference on Machine Learning, ICML 2015, 1, 448–456.
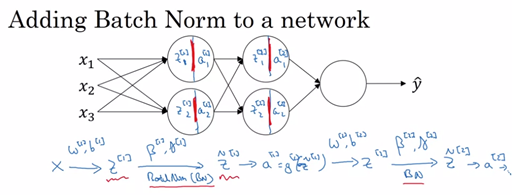
Batch Normalization(归一化)
结论:
BN就是通过一定的规范化手段,默认情况下把每层神经网络任意神经元这个输入值的分布是拉回到均值为0方差为1的标准正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题,并且能够加快训练的收敛速度,同时增强神经网络的泛化能力。
展开介绍:
在逻辑回归中,使用归一化输入特征可以加快学习过程。归一化是指先从训练集中减去平均值,然后除以方差。
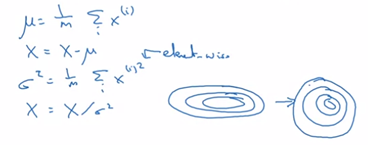
这样的方法同样适用于神经网络的输入层,这样可以得到一个均值为0方差为1的输入。但是这不适用于神经网络的隐藏层,因为隐藏层有不同的分布会更有意义,所以对于隐藏层的归一化:![]() ,这里
,这里![]() 和
和![]() 是你神经网络学习到的参数,也可以用Adam的方式更新。
是你神经网络学习到的参数,也可以用Adam的方式更新。
BN操作使隐藏单元值的均值和方差标准化,即![]() 有固定的均值和方差,均值和方差可以是0和1,也可以是其它值,它是由
有固定的均值和方差,均值和方差可以是0和1,也可以是其它值,它是由![]() 和
和![]() 两参数控制的
两参数控制的
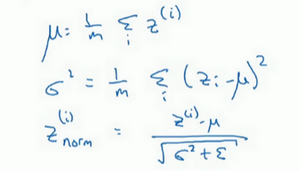

在TensorFlow中,tf.nn.batch_normalization可以一行代码实现Batch归一化(BN)。
因为在Batch归一化的过程中,你要计算![]() 的均值,再减去平均值,所以加上的常数b都将会被均值减去所抵消,
的均值,再减去平均值,所以加上的常数b都将会被均值减去所抵消,![]() 这个参数变得没有意义,所以参数实际是变为了成
这个参数变得没有意义,所以参数实际是变为了成![]() ,然后再计算归一化的
,然后再计算归一化的![]() ,
,![]() ,这就为什么最后会用参数
,这就为什么最后会用参数![]() 作为控制参数,影响转移或偏置条件。
作为控制参数,影响转移或偏置条件。
BN用于调节计算的![]() 和
和![]() 是在整个mini-batch上进行计算,但是在测试的时候,如果只有一个样本,一个样本的均值和方差没有意义。所以为了将神经网络运用于测试,就需要单独估计
是在整个mini-batch上进行计算,但是在测试的时候,如果只有一个样本,一个样本的均值和方差没有意义。所以为了将神经网络运用于测试,就需要单独估计![]() 和
和![]() 。在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的
。在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的![]() 和
和![]() 的值。还可以用指数加权平均来粗略估算
的值。还可以用指数加权平均来粗略估算![]() 和
和![]() ,然后在测试中使用
,然后在测试中使用![]() 和
和![]() 的值来进行你所需要的隐藏单元
的值来进行你所需要的隐藏单元![]() 值的调整。如果你使用的是某种深度学习框架,通常会有默认的估算
值的调整。如果你使用的是某种深度学习框架,通常会有默认的估算![]() 和
和![]() 的方式,一样会起到比较好的效果。
的方式,一样会起到比较好的效果。
为什么能增加神经网络的泛化能力?

如果是用左图的训练集训练的网络,是很难在右图的测试集上有好的表现的,因为右图的猫比左图的猫多了颜色。而Batch归一化可以减少输入值改变的问题,因为进行了标准化,固定了隐藏单元输出的均值和方差,使得左图训练出的网络在右图有相对较好的表现。
还有一点是因为Batch归一化通常和mini-batch同时使用,所以均值和方差是在小批次的数据集上计算的,而不是整个数据集,所以会引入噪声,因为给隐藏单元添加了噪声,迫使后面的隐藏单元不过分依赖前面的任何一个隐藏单元,从而起到了正则化的效果。(所以应用较大的mini-batch可以减少正则化效果)
