作者:LiNaiHan
单位:电子科学与技术 & MSRA & STCA
会议:AAAI
时间:2019.4
abstract
tacotron的问题:(1)train和infer的效率低;(2)用的是RNN,很难建模长时依赖。
本文用NMT的multi-head self-atttention替代tacotron2中的RNN和attention。(1)encoder和decoder可以并行构建,效率提高。(2)因为self-attention,任何两个时刻的输入都可以直接联系起来,解决了长时依赖的问题。
输入phoneme序列,输出mel序列,用wavenet合成语音。
introduction
回顾了一下TTS的传统方法和深度学习的方法实现。
深度学习依赖RNN/LSTM构建长时依赖。RNN的结构中,给输入产生序列输出,其中当前的输出会取决于当前以及之前时刻的输入,这就导致了模型的非并行性。此外,许多时间步之间的信号因为多次重复处理可能已经存在偏差。因此NMT任务中用transformer结构替代了RNN/LSTM。
本文结合了transformer和tacotron各自的有点,提出transformer-TTS,采用self-attention作用:(1)替代RNN建模,不需要过去的时刻,提高并行性;(2)替代tacotron的attention,multi-head多方面建模。
transformer缩短了前传(反传)中信号通过任何两个输入(输出)组合之间的路径长度(低至1)。这对建模韵律很有帮助,因为某一处的韵律不仅取决于附近的词,还依赖句子级的语义。
3. Neural TTS with Transformer
3.1 Text-to-Phoneme Converter
英文的发音有规律,神经网络可以学习这一规律,但是需要大量数据量,并且难以某些特殊的case。用的是专门的rule system将字符转换成音素。
3.2 Scaled Positional Encoding
因为transformer结构的非自回归性,打乱输入顺序,同一输入对应的输出是一样的。因此需要考虑输入帧的绝对位置。用 triangle positional embeddings表示每一帧的绝对和相对位置。

是帧的绝对位置
channel index
vector dimension
在NMT任务中,encoder和decoder都是在语言空间编码,而TTS是在不同的空间编码。因此NMT的fixed positional embedding就不太合适了。因此,对 triangle positional embeddings加一个可训练的参数
,从而自动在encoder和decoder-prenet 的输出之间调节scale。
??没懂scale是啥
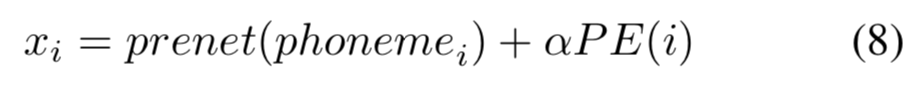
3.3 Encoder Pre-net
延用tacotron2的3层CNN结构,text-embedding(512-d),channel-512,batch norm, ReLU。因为ReLU的输出(0-1),triangle positional embeddings范围【-1,1】,因此将0-center的向量直接与非负向量相差会有问题,模型性能也会被干扰。
作用:(1)用一层线性层为center consistent进行调整。
(2)和triangle positional embeddings有一致的维度
3.4 Decoder Pre-net
结构:2层256的全连接层,ReLU激活
ps.(1)尝试了无激活的fc层,但是attention对齐矩阵不对
(2)尝试把隐层增加到512,但是除了训练时间增大,结果没有明显变好
作用:把mel谱建模到phoneme embedding相同的子空间
解释:phoneme和mel来自不同的子空间,但是phoneme embedding是trainable,thus adaptive。通过decoder pre-net 可以测量<phoneme, mel spec>的相似度。
结论:推测mel谱的子空间是一个256维度可以表示的复杂空间,(4.6有证明—decoder的positional embedding scale维度比encoder小。)
3.5 Encoder
multi-head attention 取代了bi-directional RNN,长时依赖(长句子韵律更好),并行计算。
3.6 Decoder
multi-head attention取代location sensitive attention,self-atttehtion取代RNN。把multi-head 的dot product修改成location sensitive,但是会使计算量加倍。
3.7 Mel Linear, Stop Linear and Post-net
两个单独的projection预测mel和stop token。
只有stop点的样本为正,其他都为负。这种不平衡可能会使stop无法正常阻断,为此我们在尾部正停止的点加(5-8)的正权重平衡。
4 Experiment
4.1 training setupment
25h的英文女生数据集,每句话千50ms sil,后100ms sil。
固定的batch size会有一些问题:(1)语句长短不一,会存在一些很长的句子,这样会消耗大量的计算资源。(2)batch size小,会使得模型的并行计算优势不突出。
使用dynamic batch size----最大的mel 帧数是保持不变的。
单卡的训练效果不好,合成语音质量很差;换到多卡,增大batch size这个问题得到解决。
4.4 Training Time Comparison
| 模型 | 每一步的训练时间 | 参数量 | 总训练时间 |
|---|---|---|---|
| transformer | 0.4s | 2倍 | 3天 |
| tacotron | 1.7s | 1 | 4.5天 |
4.5 Evaluation
- MOS,CMOS测试:测试baseline,tacotron和transformer的MOS,比较tacotron和transformer的CMOS(两者比较打分,哪个更倾向)。
- 谱清晰度(高频部分)对比展示
