版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a19990412/article/details/88706351
On Spectral Clustering: Analysis and an algorithm
这是一篇引用量很高(7k+)的paper。开篇的abstract就吸引人。
- 概括: 本文提出了一种简单的谱聚类算法,该算法易于实现而且表现的不错,并且基于矩阵摄动理论,我们可以分析算法并找出可以预期的良好条件。
这篇文章的算法主要是关注与n维空间的聚类点。对于这类问题,一个标准的方法就是基于一个生成的方法,在这些方法当中,比如EM算法被用来学习mixture density(混合密度)。
These approaches suffer from several drawbacks. 这些方法有些缺陷。
一个比较好的方法就是用谱方法来做聚类。这里,第一步是,选从距离矩阵中获取最大几个特征向量。Here, one uses the top eigenvectors of a matrix derived from the distance between points.
算法
简直不要太感动!这篇论文把算法写得太清晰了!!!
给定一个点集
,然后将这个分到k个类当中。
- 定义一个亲和矩阵 。其中 如果i不等于j,否则为0.
- 定义D是一个对角矩阵。对角元素是A的第i行的求和。定义一个矩阵
- 找到L的k个最大特征向量 (选出正交的避免重复的特征值)。然后得到矩阵 。注意这里是将这个作为了列向量然后得到的矩阵。
- 定义矩阵Y,是X的正则化了每一行的之后的结果,使得X的每一行都具有单位长度。
- 把Y的每行都作为一个在 的点。聚类他们到K个不同的类,通过kmeans,或者其他上面什么方法。(降低失真 minimize distortion)
- 将初始的点分配,就按照Y的每一行所分配的对应的类j。

实现
- 可以跟这篇文章做对比 Spectral clustering 谱聚类讲解及实现
import numpy as np
import numpy as np
from sklearn.cluster import KMeans
def spectral_cluster(X, n_clusters=3, sigma=1):
'''
n_cluster : cluster into n_cluster subset
sigma: a parameter of the affinity matrix
'''
def affinity_matrix(X, sigma=1):
N = len(X)
A = np.zeros((N, N))
for i in range(N):
for j in range(i+1, N):
A[i][j] = np.exp(-np.linalg.norm(X[i] - X[j])**2 / (2 * sigma ** 2))
A[j][i] = A[i][j]
return A
A = affinity_matrix(X, sigma)
def laplacianMatrix(A):
dm = np.sum(A, axis=1)
D = np.diag(dm)
sqrtD = np.diag(1.0 / (dm ** 0.5))
return np.dot(np.dot(sqrtD, A), sqrtD)
L = laplacianMatrix(A)
def largest_n_eigvec(L, n_clusters):
eigval, eigvec = np.linalg.eig(L)
index = np.argsort(np.sum(abs(eigvec), 0))[-n_clusters:]
# n_clusters largest eigenvectors' indexes.
return eigvec[:, index]
newX = largest_n_eigvec(L, n_clusters)
def renormalization(newX):
Y = newX.copy()
for i in range(len(newX)):
norm = 0
for j in newX[i]:
norm += (newX[i] ** 2)
norm = norm ** 0.5
Y[i] /= norm
return Y
Y = renormalization(newX)
kmeans = KMeans(n_clusters=n_clusters).fit(Y)
return kmeans.labels_
-
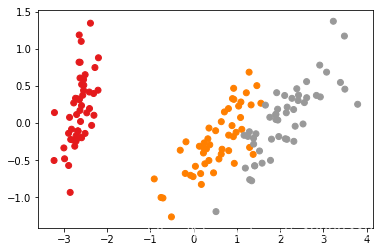
测试效果不错。但是发现对于那些出现重叠部分的数据(或者是靠的比较近(在欧式空间下)的数据,分类效果就不是很好了)
-
导入数据
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.decomposition import PCA
X_reduced = PCA(n_components=2).fit_transform(iris.data)
- 谱聚类版本
y = spectral_cluster(X_reduced, n_clusters=3, sigma=1)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=y, cmap=plt.cm.Set1)
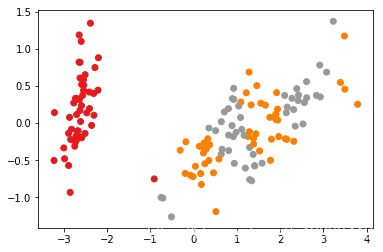
- 真实数据版本