版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a19990412/article/details/88981564
-
Min Cut

含义很简单,就是将不属于同一类的所有点之间的相似度累加起来就好了。
是一种描述不同类之间 分离程度。 -
缺点:这个方法倾向于切割小的组出来。

-
这篇论文提出的想法之一:
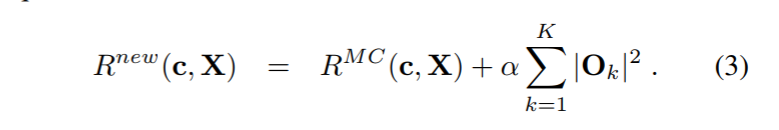
-
进一步做一个变形。中间用到了一步,就是将属于同一类的就算部分补全,使得公式更加整洁。通过化简构造出了一个常数的部分,之后,就只需要考虑后面的非常数部分了。
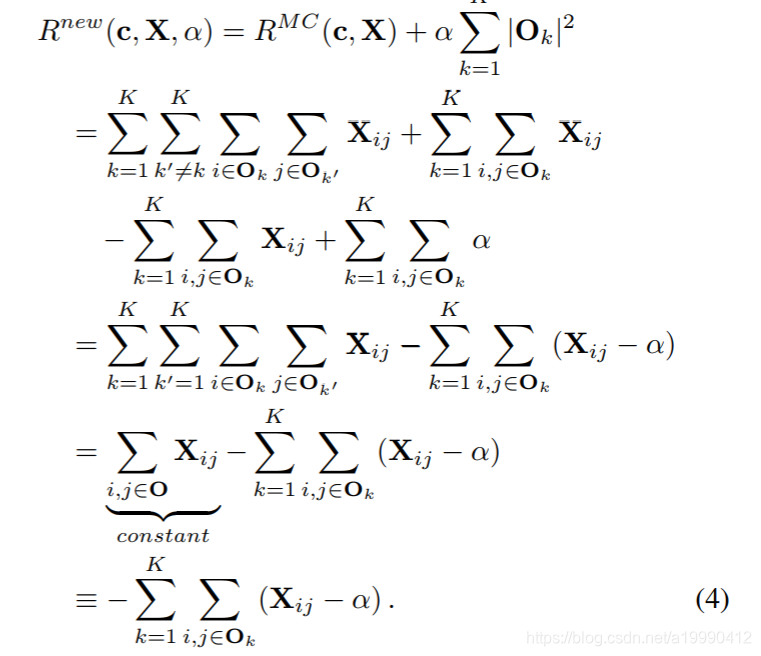
- 也就是考虑每个类内部的聚合程度。而这个 只是将类内部的点的数量信息显示了出来。个人认为,这个部分,跟之前的Ratio Cut 有点类似,虽然目标函数有些不一样,但思想都是一致的
论文中也有这样说到这个。
This formulation provides a rich family of alternative clustering
models where different regularizations are induced by
different values of α. However, choosing a very large α can
lead to equalizing the size of the clusters that are inherently
very unbalanced in size.
- 该公式提供了丰富的替代聚类系列
由不同的正则化引起的模型
不同的α值。但是,选择一个非常大的α可以使得聚类的结果均衡,就算原来的大小就是不均衡的。
很明显,这个模型需要做很多的关于超参数的修改。这样很麻烦,而且有时候根本没办法调整这个alpha。所以,本文又提出了一个改进。
- we propose a particular shift of pairwise similarities which
takes the connectivity of the objects into account and does not
require fixing any free parameter.
就是关于X做一个Shift。
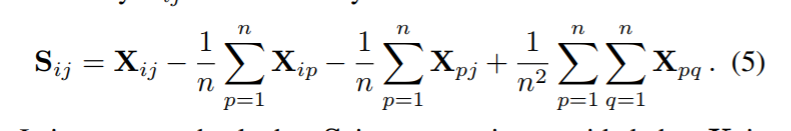
这样,就使得行列之和都会变为0了。
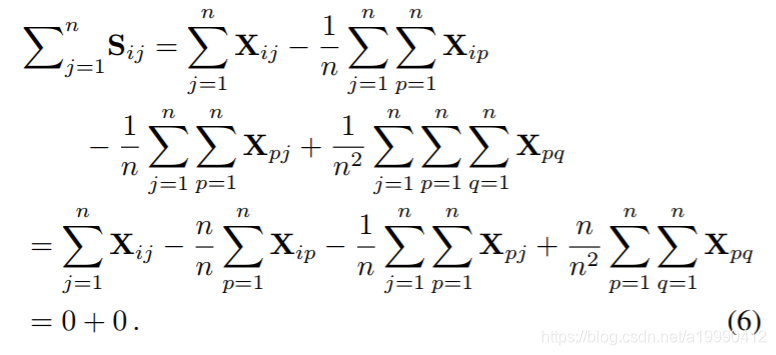
于是直接改写这个公式,得到新的损失函数:
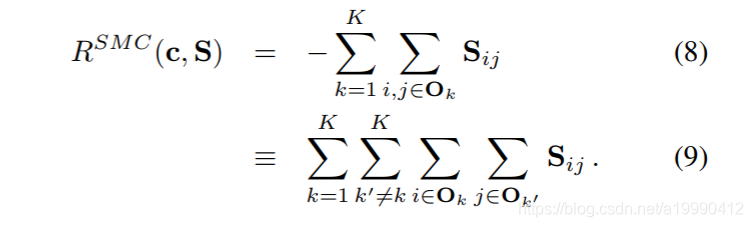
会发现,这个损失函数,就是不再存在有超参数了。