1、聚类模型的构建
sklearn 提供了多种聚类算法,主要用到的库为cluster,cluster中有很多聚类算法,如K-Means、Spectral cluster等
聚类算法的实现需要估计器Estimator,估计器有fit和predict两个算法,如下:
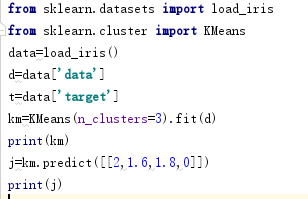

我们利用iris数据集测试,首先利用fit训练算法,再利用predict去预测,我们的重点在于预测类别,我们发现我们预测的类别为1类别,共三个类别。注意输入的预测源为二维数据。聚类的簇数也是我们设定的,n_clusters=3,其实本身数据源也有三个类别。另外利用km.labels_可以得出聚类后的类别标签,即聚成了几类
2、评价聚类模型
最好的结果是组内相似性很大,组间相似性很小。模型就是比较优的。
利用sklearn中的metrics模块可以进行评价。如下:


t为真是标签,km.labels_为预测标签,也就是聚类的时候,就已经将数据分类并且有相应的标签了
最后我们得出整体效用为0.8,越接近于1表明模型越好。
另外因为簇数是我们认为划分的,如果要更加系统的评价,我们可以利用循环,分成不同的簇数,分别评价模型的好坏,选择最优的。
其余的聚类算法和聚类模型的评价方法,请自行查阅资料。如这是有真实标签的情况下,如果没有真实标签,模型怎么评价呢?