1、sklearn.datasets 库里有很多适用于机器学习的数据库,可以按需下载和导入。
from sklearn.datasets import load_breast_cancer
data=load_breast_cancer()
加载的数据集通常包括数据,标签,特征名称和描述性信息,分别为data\target\feature_name\DESCR
如可以用cancer[‘target’]得到数据集的标签,就像列表引用一样。
之前一直想不明白标签是什么,其实就是类别,每一列是一个特征(特征就是每个类比的名字),每一行就是一个项目。这个项目由各个特征的数值和所属类别组成,仅此而已。
2、数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data[‘data’],data[‘target’],test_size=0.3, random_state=0)
print(data.shape)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
注意对数据和标签都进行了划分,如果是分类回归,则传入数据和标签,如果是聚类,则仅传入数据即可。
3、转换器使用
为了帮助用户实现大量的特征处理,sklearn把相关功能封装为转换器,其中有三个方法,fit、transform、fit_transform
其中fit方法就是通过分析提取信息,transform进行转换,具体如下:
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler().fit(x_train) #生成规则
x_trainscaler=scaler.transform(x_train) #应用规则
print(x_trainscaler)
print(np.min(x_trainscaler))
print(np.max(x_trainscaler))
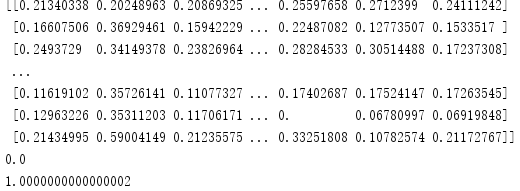
进行离差标准化后数据均处于0到1之间。相比于pandas方法,更加快速简单。
更多数据处理函数可自行查阅。
4、特征分解模块的使用,如PCA降维等,如下:
同样是转换器的使用,应用fit、transform ,生成规则,再应用规则,只是函数变化而已。
from sklearn.decomposition import PCA
pca=PCA(n_components=5).fit(x_trainscaler) #生成规则
x_pca=pca.transform(x_trainscaler) #应用规则
print(x_trainscaler.shape)
print(x_pca.shape)

我们发现降维之后的特征减少到了5个,当然,这是我们自行规定的特征个数,那么问题来了,我们认为规定的个数不一定就是最佳的,我们如何得到最佳的特征个数呢?
可以使用n_components=‘mle’,这样系统会自动根据某些方法进行确定特征个数
另外感兴趣的小伙伴可以去查看其他参数,如svd_solver、copy等。正常情况下,默认即可。