RNN 模型
Recurrent Neural Network (回流神经网络,有的译做递归神经网络)
时间序列模型最常用最强大的的工具就是递归神经网络(recurrent neural network, RNN)。相比与普通神经网络的各计算结果之间相互独立的特点,RNN的每一次隐含层的计算结果都与当前输入以及上一次的隐含层结果相关。通过这种方法,RNN的计算结果便具备了记忆之前几次结果的特点。
简单来说,RNN可以通过t个历史记录预测t+1。看下图可能更容易理解它的原理

右侧为计算时便于理解记忆而产开的结构。简单说,x为输入层,o为输出层,s为隐含层,而t指第几次的计算;V,W,U为权重,其中计算第t次的隐含层状态时为St = f(U*Xt + W*St-1),实现当前输入结果与之前的计算挂钩的目的。
RNN的局限:
由于RNN模型如果需要实现长期记忆的话需要将当前的隐含态的计算与前n次的计算挂钩,即St = f(U*Xt + W1*St-1 + W2*St-2 + ... + Wn*St-n),那样的话计算量会呈指数式增长,导致模型训练的时间大幅增加,因此RNN模型一般不直接用来进行长期记忆计算。另外,传统RNN处理不了长期依赖问题,这是个致命伤。
其他关于RNN评价的概括总结:
现实中的RNN因为层次较深,比较难优化,单纯的BPTT(back-propagation through time)容易出现问题。
对于时间序列的模型中,在非线性模型这一块, 应该就是RNN, 它是表达能力很强的一个模型. 但是RNN的training比较困难, 同时RNN的参数选择(layer, activation function, hidden neuron, learning rate)都难以优化.
对于纯粹时间序列预测,目前最理想的方法应该就是RNN及其变体了。标准的RNN要达到好的效果会比较难训练,目前它的带记忆的变体,比如LSTM(long-short term memory)和GRU(gated recurrent unit)都非常热门。进一步的,这些模型还可以和其它神经网络模型组合,比如在LSTM下面堆叠若干层的CNN等等,这样基本上就是目前深度学习(deep learning)中常见的处理时间序列最好的模型了。当然这也要配置和训练得当才能得到好的效果(包括数据预处理、恰当的参数等)。
LSTM 模型
LSTM(Long Short-Term Memory)模型是一种RNN的变型
简单来说,这个模型相对于RNN的改进就是:既要提取有用的记忆信息,又要去除没用的记忆信息。通过下图容易理解

演示了阀门是如何工作的:通过阀门控制使序列第1的输入的变量影响到了序列第4,6的的变量计算结果。
黑色实心圆代表对该节点的计算结果输出到下一层或下一次计算;空心圆则表示该节点的计算结果没有输入到网络或者没有从上一次收到信号。
LSTM模型应该是针对RNN处理不了长期依赖问题所做出的改进模型,对于之前的历史数据只提取有用的,而过滤掉了噪声,这样从某种程度上就减少了模型的计算量。备注:Python中有不少包可以直接调用来构建LSTM模型,比如pybrain, kears, tensorflow, cikit-neuralnetwork等。
移动平均模型
移动平均模型是最简单的时间序列模型,分为一次移动平均和多次移动平均
一次移动平均
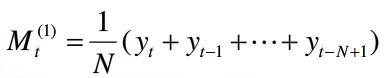
二次移动平均
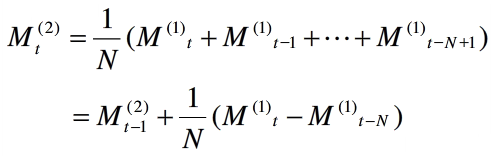
当预测目标的基本趋势是在某一水平上下波动时,可用一次移动平均,当预测目标的基本趋势与某一线性模型相吻合时,常用二次移动平均。当序列同时存在线性趋势与周期波动时,可用趋势移动。平均移动平均的思想是:取最近N期序列值的平均值作为未来各期的预测结果,一般N的取值范围在5-200之间,当历史序列的基本趋势变化不大时且序列中随机变动的成分较多时,N的取值应该大一些,否则应该小一些,当有确定的季节变动周期资料中,移动平均的项数应取周期长度。选择最佳N值的有效方法是,比较若干模型的预测误差,均方预测误差最小者为好。
指数平滑模型
指数平滑法是生产预测中常用的一种方法。所有预测方法中,指数平滑是用得最多的一种。指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。

![]() 为t+1期的指数平滑趋势预测值;
为t+1期的指数平滑趋势预测值;![]() 为t期的指数平滑趋势预测值;
为t期的指数平滑趋势预测值;![]() 为t期实际观察值;
为t期实际观察值;
一次指数平滑法只适合于具有水平发展趋势的时间序列分析,只能对近期进行预测。如果碰到时间序列具有上升或下降趋势时,在这个上升或下降的过程中,预测偏差会比较大,这时最好用二次指数平滑法进行预测,
1、优点:所需数据资料少,就可以预测出来所需要的结果,指数平滑法是在移动平均法基础上发展起来的一种时间序列分析预测法,兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数是通过计算指数平滑值,配合一定的时间序列预测模型对现象的未来进行预测。
2、缺点:赋予远期较小的比重,近期较大的比重,所以只能进行短期预测。
ARIMA模型
在整个调查过程中,该模型的出现频率是最高的,评价来看应该是使用最广泛的一个模型,但关于其具体适用范围的介绍却很少。
是由Box-Jenkins提出的更加全面的时间序列分析模型,也称为整合自回归移动平均模型,该模型的基础是自回归和移动平均模型(ARMA模型),在数学上,指数平滑模型仅仅是ARIMA模型的特例。
ARIMA模型包括两个特殊模型
<1>自回归模型(AR模型)
设某变量的一个观测值是由其以前的p个观测值的线性组合加上随机误差项at而得,at也称为白噪声,假设at在不同时间上是相互独立无关的。
该模型看上去就像是自己对自己回归一样,所以称为自回归模型,一阶自回归模型记为AR(1),p阶自回归模型记为AR(p),计算AR模型的目的是了解预测值和几个过去值有关,相关关系如何,并确定各阶参数φ
<2>移动平均模型(MA模型)
设某变量的一个观测值是由目前和以前的q个随机误差的线性回归而得
计算MA模型的目的是求解θ的估计值,at的假设和AR模型一样
对于AR(p)模型,如果at不是白噪声,而是MA(q)模型的形式,那么就得出了ARMA(p,q)模型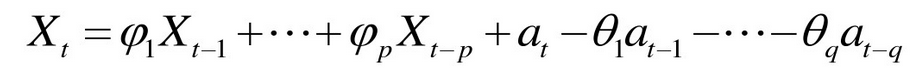
显然,ARMA(P,0)就是AR(p),ARMA(0,q)就是MA(q),整个模型有p+q个参数要估计。ARMA(p,q)模型的前提条件是时间序列平稳和可逆,对于不平稳的时间序列必须经过差分变换,转化为平稳的,因此平稳之后的ARMA(p,q)模型就是ARIMA(p,d,q)模型,d为差分阶数,当不需要差分时,d=0,ARIMA(p,d,q)=ARIMA(p,0,q)=ARMA(p,q),拟合ARIMA模型就是确定阶数p,d,q,由于p,q和自相关函数ACF及偏相关函数PACF有关,因此需要结合自相关图和偏相关图进行识别确定。
STL分解法
STL分解法是一个兼具通用性和鲁棒性的时间序列分解法。STL是”Seasonal and Trend decomposition using Loess”的简写。
STL分解基于Loess(局部加权回归法),即局部加权回归散点平滑法,是1990年由密歇根大学的R. B. Cleveland教授以及AT&T Bell实验室的W. S. Cleveland等人提出来的一种对时间序列进行分解的方法。STL分解将时间序列分解成季节项、趋势项及残余项。
优点:
1.可以处理任何类型的季节变动因素的数据,而不仅仅是季度或是月份的数据
2.季度成分可以被允许随着时间变化而变化,并且用户可以自行控制变化率
3.用户可以自行控制趋势-周期成分的平滑度
4.对异常值有更好的鲁棒性
缺点:
1.它只适用于加法模型
2.it does not automatically handle trading day or calendar variation
Random Walk Model
备注:该部分取自英文pdf,有些名词怕在翻译过程中翻译的不好,而失去了它原本想要表达的意思,故此部分用英文原文
The random walk model is very simple. Without a constant, it uses the current value of the time series to forecast all future values, i.e.,
Ft(k) = Yt for all k≥![]() 1
1
该式子意思应该是在t+k时刻的预测值等于在t时刻的实际值
This model is often used for data that does not have a fixed mean and for which the history of the process is irrelevant given its current position. The time series is thus equally likely to go up or down at any point in time.
If a constant is included, then the forecast is given by
Ft(k) = Yt+k*∆![]()
where ∆ ![]() estimates the average change from one period to the next. The forecast function for such a model is a straight line with slope equal to ∆
estimates the average change from one period to the next. The forecast function for such a model is a straight line with slope equal to ∆![]() .
.
文章中预测旧金山金洲大桥在20年间,每个月的交通量效果图

The plot shows:
Observed data: shown using point symbols.
2.One-ahead forecasts: shown as a solid line passing through the data.
3.Forecasts for future values: extension of the forecasts past the end of the data.
4.95% prediction limits: the red bounds around the forecasts.
Note the wide prediction limits, typical of random walk models.
Trend Models
The Mean, Linear Trend, Quadratic Trend, Exponential Trend, and S-Curve models all fit various types of regression models to the data, using time as the independent variable. The models are fit by least squares, resulting in estimates of up to 3 coefficients: a, b, and c. Forecasts from the models are as follows:

Since they weight all data equally, regression models are often not the best methods for forecasting time series data.
在本问题中,二次模型是几个中效果最好的,下面是该模型的效果图,同样是交通数据

怎么选择以上四个模型:
画图看它的趋势,如果呈线性,则用线性模型;如果有些弯曲或者呈指数型,则用二次模型或指数模型;如果是一个S形状,则用S-curve trend model
也可以拟合四个模型,并比较它们的测量指标,如MAPE, MAD 和 MSD。 选择指标最小的模型。
其他模型
ARCH模型
ARCH模型能准确地模拟时间序列变量的波动性的变化,它在金融工程学的实证研究中也应用广泛,使人们能更加准确地把握风险(波动性),尤其是应用在风险价值(Value at Risk)理论中,在华尔街是尽人皆知的工具。
时间序列分析方法的优点
既考虑了观测数据在时间序列上的依存性,又考虑了随机波动的干扰
将ARCH中的方差用ARMA模型表示,则ARCH模型变形为GARCH模型
机器学习中的SVR, randomForest, lasso,xgboost,在这些资料中,更多的是讲述如何使用它们,或者是做了一些小改进,但是关于适用的范围或者使用的特点的描述就比较少。