一、时间序列概念
在生产和科学研究中,对某一个或一组变量x(t)进行观察测量,将在一系列时刻t1, t2, …, tn (t为自变量)按照时间次序排列,并用于解释变量和相互关系的数学表达式。在相等的时间间隔内收集到的不同时间点的数据集合我们称之为时间序列,这种有时间意义的序列也称为动态数据,被用来预测长期的发展趋势。这样的动态数据在自然、经济及社会等领域都是很常见的。如在一定生态条件下,动植物种群数量逐月或逐年的消长过程、某证券交易所每天的收盘指数、每个月的gnp、失业人数或物价指数等等。
二、时间序列与回归问题的区别
1.时间序列跟时间相关,而回归模型的假设是:观察结果之间相互独立,不存在依赖关系。
2.时间序列,随着时间的变化会出现上升或下降,也可能会出现季节性波动。
三、时间序列模型
(一)使用ARIMA模型,要求数据具有平稳性。
平稳性:要求经由时间序列所得到的你和缺陷在未来的一段时间内仍能顺着现有的形态‘惯性’的延续下去,序列的均值和方差不发生明细的变化。
平稳性分为严平稳和弱平稳:
严平稳:分布不随时间的改变而改变。如白噪声(正太分布),无论如何取,期望都是0方差为1.
弱平稳:期望与相关系数(依赖性)不变。某时刻t的值Xt依赖于他过去的信息。
(二)差分法:时间序列在t与t-1时刻的插值(一阶差分)
(三)常用的时间序列模型有
1.AR模型(Autoregressive model:自回归模型)
2.MA模型(moving average model:滑动平均模型)
3.ARMA模型(Auto-Regressive and Moving Average Model:自回归滑动平均模型)
4.ARIMA模型(Autoregressive Integrated Moving Average Model:自回归积分滑动平均模型)
1.AR模型(Autoregressive model:自回归模型)
描述当前值与历史值之间的关系,用变量自身历史数据对自身进行预测。
自回归模型必须满足平稳性要求。

限制:用自身数据进行预测,必须具有平稳性,必须具有自相关性,如果相关系数小于0.5,不宜采用,只适用于预测和自身前期相关的现象。
2.MA模型(moving average model:滑动平均模型)
关注自回归模型中的误差累加项,能有效消除预测中的随机波动。

3.ARMA模型(Auto-Regressive and Moving Average Model:自回归滑动平均模型)
前两者的结合
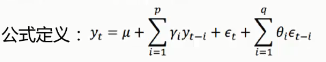
4.ARIMA模型(Autoregressive Integrated Moving Average Model:自回归积分滑动平均模型)
**原理:**将非平稳的时间序列转化为平稳的时间序列后,将因变量仅对它的滞后值及随机误差项现值和滞后值进行回归所建立的模型
ARIMA(p,d,q):p为自回归项,MA为平均移动,q为平均移动项数,d为时间序列成为平稳时所做的差分次数。
四、模型参数选定
1.p、q值选定
自相关函数AFC:
有序的随机变量序列与其自身相比较,自相关函数反映了同一序列在不同时序的取值之间的相关性
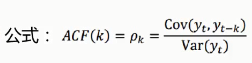
pk的取值范围[-1,1]
偏自相关函数(PACF)


五、ARIMA建模流程:
1.将序列平稳(差分法确定d)
2.p和q阶数确定:ACF与PACF
3.ARIMA(p,d,q)
六、模型评估标准:

可输出最合适的p、q
模型残差检验:
残差是否平均值为0 且方差为正太分布
QQ图:线性即正太分布

七、时间序列模型应用