目录
一个引言
时间序列是时间间隔不变的情况下收集的时间点集合。分析这些集合来确定长期趋势,为了预测未来或进行其他形式的分析。但是什么使Time Series不同于常规回归问题呢?有两个原因:
1. 时间序列是与时间有关的。因此线性模型的基础假设:观察值是独立的是不适应这个场景的。
2. 伴随着增加和减少的趋势,大多数时间序列会存在季节性趋势,比如,特定时间的特定变化。例如,如果你看到羊毛夹克随时间变化的销量,你一定会发现冬季的销量会很高。
定义
时间序列是按时间顺序排列的、随时间变化且相互关联的数据序列。分析时间序 列的方法构成数据分析的一个重要领域,即时间序列分析。 时间序列根据所研究的依据不同,可有不同的分类。
按 研究对象的数量,有 一元时间序列 和 多元时间序列
按 时间的连续性,有 离散时间序列 和 连续时间序列
按 序列的统计特性,有 平稳时间序列 和 非平稳时间序列。如果一个时间序列的概率分布与时间t无关,则称该序列为严格的(狭义的)平稳时间序列。如果序列的一、二阶矩存在,而且对任意时刻t满足:
(1)均值为常数
(2)协方差为时间间隔γ的函数,则称该序列为宽平稳时间序列,也叫广义平稳时间序列。
按 时间序列的分布规律 来分, 有高斯型时间序列和非高斯型时间序列。
确定性时间序列分析方法概述
时间序列预测技术是通过对预测目标自身时间序列的处理,从而研究其变化趋势。一个时间序列往往是以下几类变化形式的叠加或耦合。我们常认为一个时间序列可以分解为以下四大部分:
(1)长期趋势变动(T)。指时间序列朝着一定的方向持续上升或下降,或停留在 某一水平上的倾向,它反映了客观事物的主要变化趋势。
(2)季节变动(S)。在一年内随着季节的变化而发生的有规律的周期性变动。
(3)循环变动(C)。通常是指周期为一年以上,由非季节因素引起的涨落起伏波形相似的波动。
(4)不规则变动(I)。是一种无规律可循的变动,包括严格的随机变动和不规则的突发性影响很大的变动两种模型。
确定性时间序列模型类型
我们通常用表示长期趋势项,
表示季节变动趋势项,
表示循环变动趋势项,
表示随机干扰项。常见的确定性时间序列模型有以下几种类型:
(1)加法模型
(2)乘法模型
(3)混合模型
其中是观测目标的观测记录,
,
。如果在预测时间范围内,无突然变动且随机变动的方差
较小,并且有理由认为过去和现在的演变趋势将继续发展到未来时,可用一些经验方法进行预测。
移动平均法
移动平均法(Moving average,MA) 可以作为一种数据平滑的方式 ,以每天的气温数据为例,今天的天气可能与过去的十天的气温有线性关系;或者有的人对食物有一种节俭的美德,他们做的饭菜能看出有些是上一顿的,当然也有一部分是今天的做的,再假设隔两顿的都被倒掉了,并且每天都是这样的,那么这碗饭菜可能就是一部分上一顿的再加上一部分今天现做的,这就是一个一阶的移动平均。
移动平均法是根据时间序列资料逐渐推移,依次计算包含一定项数的时序平均数, 以反映长期趋势的方法。当时间序列的数值由于受周期变动和不规则变动的影响,起伏 较大,不易显示出发展趋势时,可用移动平均法,消除这些因素的影响,分析、预测序列的长期趋势。 移动平均法有简单移动平均法,加权移动平均法,趋势移动平均法等。
简单移动平均法

近N 期序列值的平均值作为未来各期的预测结果。一般 N 的取值范围: 5≤N≤ 200。当历史序列的基本趋势变化不大且序列中随机变动成分较多时,N 的 取值应较大一些。否则 N 的取值应小一些。在有确定的季节变动周期的资料中,移动平均的项数应取周期长度。选择佳 N 值的一个有效方法是,比较若干模型的预测误 差。预测标准误差小者为好。
简单移动平均法只适合做近期预测,而且是预测目标的发展趋势变化不大的情况。 如果目标的发展趋势存在其它的变化,采用简单移动平均法就会产生较大的预测偏差和滞后。
加权移动平均法
在简单移动平均公式中,每期数据在求平均时的作用是等同的。但是,每期数据所包含的信息量不一样,近期数据包含着更多关于未来情况的信心。因此,把各期数据等同看待是不尽合理的,应考虑各期数据的重要性,对近期数据给予较大的权重,这就 是加权移动平均法的基本思想。

例 2 我国 1979~1988 年原煤产量如表 2 所示,试用加权移动平均法预测 1989 年 的产量

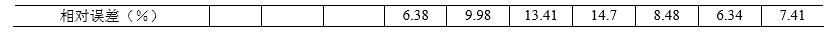

趋势移动平均法
简单移动平均法和加权移动平均法,在时间序列没有明显的趋势变动时,能够准确 反映实际情况。但当时间序列出现直线增加或减少的变动趋势时,用简单移动平均法和 加权移动平均法来预测就会出现滞后偏差。因此,需要进行修正,修正的方法是作二次 移动平均,利用移动平均滞后偏差的规律来建立直线趋势的预测模型。这就是趋势移动平均法。 一次移动的平均数为



例 3 我国 1965~1985 年的发电总量如表 3 所示,试预测 1986 年和 1987 年的发 电总量。
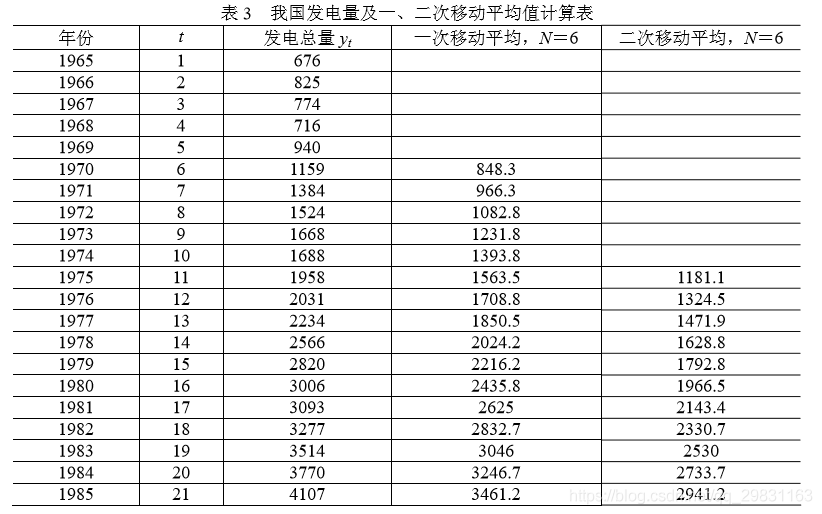
解 由散点图 1 可以看出,发电总量基本呈直线上升趋势,可用趋势移动平均法 来预测。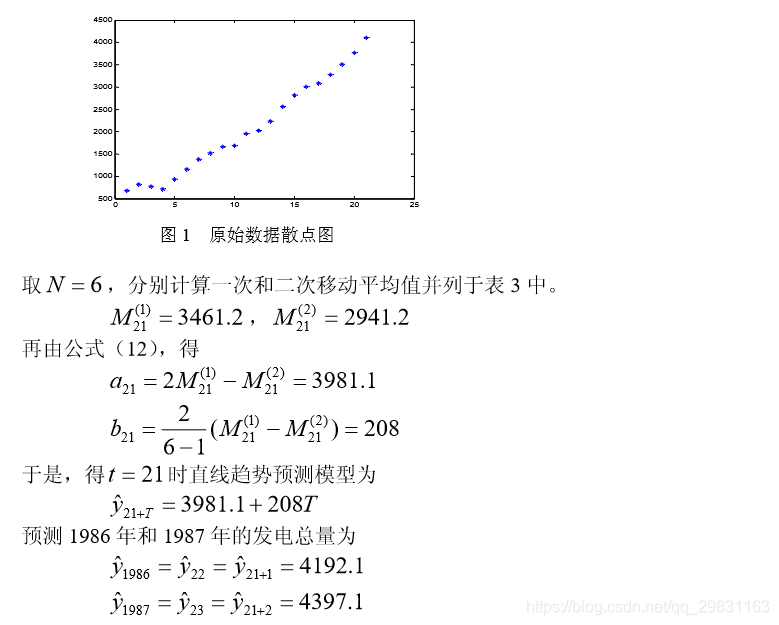
指数平滑法
一次指数平滑法
1.预测模型

2.加权系数的选择
3.初始值的确定
例 4 某市 1976~1987 年某种电器销售额如表 4 所示。试预测 1988 年该电器销售 额。

二次指数平滑法
例 5 仍以例 3 我国 1965~1985 年的发电总量资料为例,试用二次指数平滑法预 测 1986 年和 1987 年的发电总量


三次指数平滑法
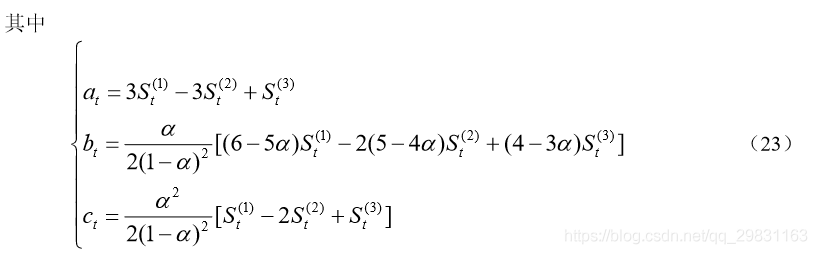
例 6 某省 1978~1988 年全民所有制单位固定资产投资总额如表 7 所示,试预测 1989 年和 1990 年固定资产投资总额。 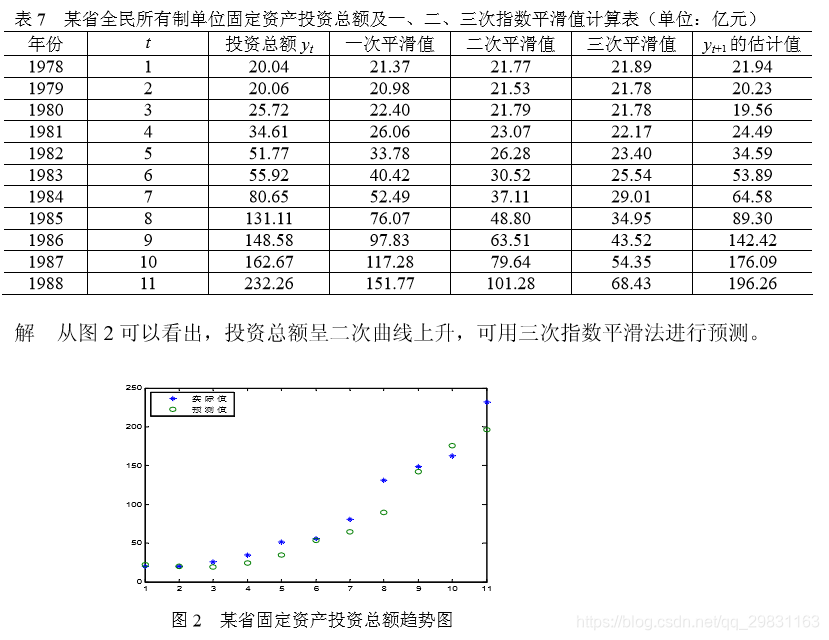
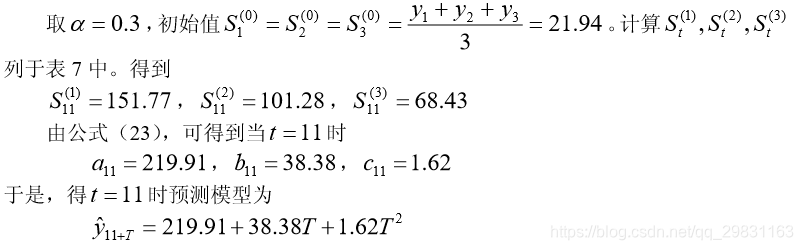

指数平滑预测模型的评价
指数平滑预测模型是以时刻t为起点,综合历史序列的信息,对未来进行预测的。 选择合适的加权系数 α 是提高预测精度的关键环节。根据实践经验, α 的取值范围一 般以 0.1~0.3 为宜。 α 值愈大,加权系数序列衰减速度愈快,所以实际上 α 取值大小 起着控制参加平均的历史数据的个数的作用。 α 值愈大意味着采用的数据愈少。因此, 可以得到选择 α 值的一些基本准则。
(1)如果序列的基本趋势比较稳,预测偏差由随机因素造成,则 α 值应取小一些, 以减少修正幅度,使预测模型能包含更多历史数据的信息。
(2)如果预测目标的基本趋势已发生系统地变化,则 α 值应取得大一些。这样, 可以偏重新数据的信息对原模型进行大幅度修正,以使预测模型适应预测目标的新变 化。
一般自回归模型 AR(n)
白噪声序列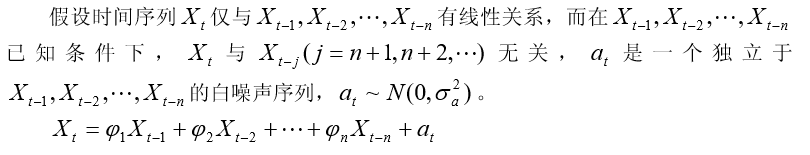

移动平均模型 MA(m)
自回归移动平均模型
ARMA 模型的特性
在时间序列的时域分析中,线性差分方程是极为有效的工具。事实上,任何一个 ARMA 模型都是一个线性差分方程。
AR(1)系统的格林函数
格林函数就是描述系统记忆扰动程度的函数。

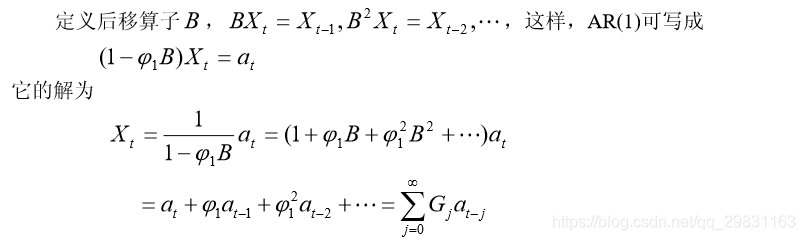
由于格林函数就是差分方程解的系数函数,格林函数的意义可概括如下:
ARMA (2,1)系统的格林函数 的隐式 


逆函数和可逆性 

————————————————
版权声明:本文为CSDN博主「wamg潇潇」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_29831163/article/details/89448959