目录
概念介绍可以参考:[深度学习]理解RNN, GRU, LSTM 网络
Pytorch中所有模型分为构造参数和输入和输出构造参数两种类型。
- 模型构造参数主要限定了网络的结构,如对循环网络,则包括输入维度、隐层\输出维度、层数;对卷积网络,无论卷积层还是池化层,都不关心输入维度,其构造方法只涉及卷积核大小\步长等。这里的参数决定了模型持久化后的大小.
- 输入和输出的构造参数一般和模型训练相关,都需指定batch大小,seq大小(循环网络)\chanel大小(卷积网络),以及输入\输出维度,如果是RNN还需涉及h0和c0的初始化等。这里的参数决定了模型训练效果。
一 Liner
- Liner(x_dim,y_dim)
– 输入x,程序输入(batch,x)
– 输出y, 程序输出(batch,y)
import torch
import torch.nn as nn
from torch.autograd import Variable as V
line = nn.Linear(2, 4) # 输入2维,输出4维
print(line)
print(line.weight) # 参数是随机初始化的,维度为out_dim * in_dim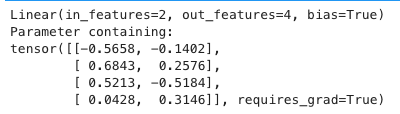
x = V(torch.randn(5,2)) # batch为5,即一次输入10个x
print(x)
line(x) # 输出为batch*4
二 RNN
首先介绍一下什么是rnn,rnn特别擅长处理序列类型的数据,因为他是一个循环的结构
一个序列的数据依次进入网络A,网络A循环的往后传递。
这里输入X一般是一个sequence, 如[我 爱 上海 小笼包] x1="我"

对于最简单的 RNN,我们可以使用下面两种方式去调用,分别是 torch.nn.RNNCell() 和 torch.nn.RNN(),这两种方式的区别在于 RNNCell() 只能接受序列中单步的输入,且必须传入隐藏状态,而 RNN() 可以接受一个序列的输入,默认会传入全 0 的隐藏状态,也可以自己申明隐藏状态传入。

# 构造RNN网络,x的维度5,隐层的维度10,网络的层数2
rnn_seq = nn.RNN(5, 10,2)
# 构造一个输入序列,长为 6,batch 是 3, 特征是 5
x = V(torch.randn(6, 3, 5))
#out,ht = rnn_seq(x, h0) # h0可以指定或者不指定
out,ht = rnn_seq(x)
# q1:这里out、ht的size是多少呢? out:6*3*10, ht:2*3*10
这就是RNN的基本结构类型。而最早的RNN模型,序列依次进入网络中,之前进入序列的数据会保存信息而对后面的数据产生影响,所以RNN有着记忆的特性,而同时越前面的数据进入序列的时间越早,所以对后面的数据的影响也就越弱,简而言之就是一个数据会更大程度受到其临近数据的影响。但是我们很有可能需要更长时间之前的信息,而这个能力传统的RNN特别弱,于是有了LSTM这个变体。
三 LSTM



这就是LSTM的模型结构,也是一个向后传递的链式模型,而现在广泛使用的RNN其实就是LSTM,序列中每个数据传入LSTM可以得到两个输出,而这两个输出和序列中下一个数据一起又作为传入LSTM的输入,然后不断地循环向后,直到序列结束。
注意共4个非线性变化。其中三个sigmoid变化分别对应的三个门:遗忘门f、输入门(当前状态)i、输出门o。这三个门的取值为[0,1],可以看做选择系数可以很好的控制信息的传导。
LSTM参数
- input_size 表示的是输入的数据维数
- hidden_size 表示的是输出维数
- num_layers 表示堆叠几层的LSTM,默认是1
- bias True 或者 False,决定是否使用bias, False则b_h=0. 默认为True
- batch_first True 或者 False,因为nn.lstm()接受的数据输入是(序列长度,batch,输入维数),这和我们cnn输入的方式不太一致,所以使用batch_first,我们可以将输入变成(batch,序列长度,输入维数)
- dropout 表示除了最后一层之外都引入一个dropout,
- bidirectional 表示双向LSTM,也就是序列从左往右算一次,从右往左又算一次,这样就可以两倍的输出
LSTM数据格式:
-
num_layers: 我们构建的循环网络有层lstm -
num_directions: 当bidirectional=True时,num_directions=2;当bidirectional=False时,num_directions=1
LSTM Input 数据格式
LSTM输入的X数据格式尺寸为(seq_len, batch, input_size),此外h0和c0尺寸如下
-
h0(num_layers * num_directions, batch_size, hidden_size) -
c0(num_layers * num_directions, batch_size, hidden_size)
LSTM Output 数据格式
LSTM输出数据格式尺寸为(seq_len, batch, hidden_size * num_directions);输出的hn和cn尺寸如下
-
hn(num_layers * num_directions, batch_size, hidden_size) -
cn(num_layers * num_directions, batch_size, hidden_size)
详细介绍LSTM单元

是网络的输出维数,比如M,因为输出的维度是M,权重w的维数就是(M, M)和(M, K),b的维数就是(M, 1)和(M, 1),最后经过sigmoid激活函数,得到的f的维数是(M, 1)。
对于第一个数据,需要定义初始的h_0和c_0,所以nn.lstm()的输入Inputs:input, (h_0, c_0),表示输入的数据以及h_0和c_0,这个可以自己定义,如果不定义,默认就是0
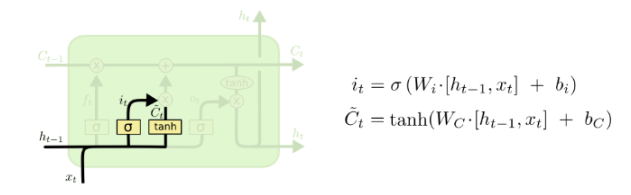
第二步也是差不多的操作,只不多是另外两个权重加上不同的激活函数,一个使用的是sigmoid,一个使用的是tanh,得到的输出和
都是(M, 1)。

接着这个乘法是矩阵每个位置对应相乘,然后将两个矩阵加起来,得到的输出是(M, 1)。
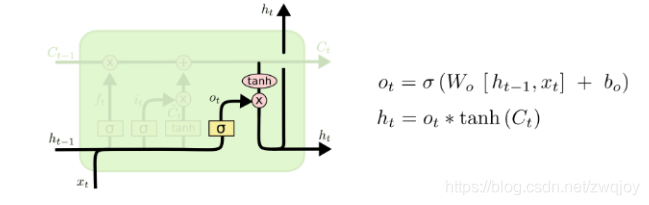
最后一步得到的也是(M, 1),然后
经过激活函数tanh,再和
每个位置相乘,得到的输出
也是(M, 1)。
最后得到的输出就是和
,维数分别都是(M, 1),而输入
维数都是(K, 1)。
四 LSTM 代码例子
Example 1
# 输入维度 50,隐层100维,两层
lstm_seq = nn.LSTM(50, 100, num_layers=2)
# 查看网络的权重,ih和hh,共2层,所以有四个要学习的参数
print(lstm_seq.weight_hh_l0.size())
print(lstm_seq.weight_ih_l0.size())
print(lstm_seq.weight_hh_l1.size())
print(lstm_seq.weight_ih_l1.size())
# q1: 输出的size是多少?
#torch.Size([400, 100])
#torch.Size([400, 50])
#torch.Size([400, 100])
#torch.Size([400, 100])# 输入序列seq= 10,batch =3,输入维度=50
lstm_input = V(torch.randn(10, 3, 50))
out, (h, c) = lstm_seq(lstm_input) # 使用默认的全 0 隐藏状态
# q1:out和(h,c)的size各是多少?out:(10*3*100),(h,c):都是(2*3*100)
print(out.shape, h.shape, c.shape)
#torch.Size([10, 3, 100]) torch.Size([2, 3, 100]) torch.Size([2, 3, 100])Example 2
通过这样定义一个一层的LSTM输入是10,输出是30
from torch.autograd import Variable
lstm = nn.LSTM(10, 30, batch_first=True)
print(lstm.weight_hh_l0.size())
print(lstm.weight_ih_l0.size())
print(lstm.bias_hh_l0.size())
print(lstm.bias_ih_l0.size())
#torch.Size([120, 30])
#torch.Size([120, 10])
#torch.Size([120])
#torch.Size([120])可以分别得到权重的维数,注意之前我们定义的4个weights被整合到了一起,比如这个lstm,输入是10维,输出是30维,相对应的weight就是30x10,这样的权重有4个,然后pytorch将这4个组合在了一起,方便表示,也就是lstm.weight_ih_l0,所以它的维数就是120x10
我们定义一个输入
x = Variable(torch.randn((50, 100, 10)))
h0 = Variable(torch.randn(1, 50, 30))
c0 = Variable(torch.randn(1, 50 ,30))
- x的三个数字分别表示batch_size为50,序列长度为100,每个数据维数为10
- h0的第二个参数表示batch_size为50,输出维数为30,第一个参数取决于网络层数和是否是双向的,如果双向需要乘2,如果是多层,就需要乘以网络层数
- c0的三个参数和h0是一致的
out, (h_out, c_out) = lstm(x, (h0, c0))

这样就可以得到网络的输出了,和上面讲的一致,另外如果不传入h0和c0,默认的会传入相同维数的0矩阵
这就是我们如何在pytorch上使用RNN的基本操作了,了解完最基本的参数我们才能够使用其来做应用。
Example 3
import torch
from torch import nn
from torch.autograd import Variable
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
# 超参数
EPOCH = 1
BATCH_SIZE = 64
TIME_STEP = 28 # rnn time step / image height
INPUT_SIZE = 28 # rnn input size / image width
LR = 0.01
DOWNLOWD_MNIST = False # 如果没有下载好MNIST数据,设置为True
# 下载数据
# 训练数据
train_data = datasets.MNIST(root='./mnist', train=True, transform=transforms.ToTensor(), download=DOWNLOWD_MNIST)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 测试数据
test_data = datasets.MNIST(root='./mnist', train=False, transform=transforms.ToTensor())
test_x = Variable(test_data.test_data).type(torch.FloatTensor)[:2000] / 255.
test_y = np.squeeze(test_data.test_labels.numpy())[:2000]
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM(
input_size=INPUT_SIZE,
hidden_size=64,
num_layers=2, # hidden_layer的数目
batch_first=True, # 输入数据的维度一般是(batch, time_step, input),该属性表征batch是否放在第一个维度
)
self.out = nn.Linear(64, 10)
def forward(self, x):
# rnn 运行的结果出了每层的输出之外,还有该层要传入下一层进行辅助分析的hidden state,
# lstm 的hidden state相比于 RNN,其分成了主线h_n,分线h_c
r_out, (h_n, h_c) = self.rnn(x, None) # x shape ( batch, step, input_size), None 之前的hidden state(没有则填None)
out = self.out(r_out[:, -1, :]) # 选取最后一个时刻的output,进行最终的类别判断
return out
rnn = RNN()
# print(rnn)
# 优化器
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR)
# 误差函数
loss_func = nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
b_x = Variable(x.view(-1, 28, 28)) # reshape x to (batch, time_step, input_size)
b_y = Variable(y)
output = rnn(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = rnn(test_x)
pred_y = np.squeeze(torch.max(test_output, 1)[1].data.numpy())
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, ' | train loss: %.4f' % loss.data.numpy(), ' | test accuracy: %.2f' % accuracy )
# 输出前10个测试数据的测试值
test_output = rnn(test_x[: 10].view(-1, 28, 28))
pred_y = np.squeeze(torch.max(test_output, 1)[1].data.numpy())
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')![]()
更多的RNN的应用可以看这个资源