版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/y3over/article/details/86561267
Skip list是一个“概率型”的数据结构,可以在很多应用场景中替代平衡树。Skip list算法与平衡树相比,有相似的渐进期望时间边界,但是它更简单,更快,使用更少的空间。
Skip list是一个分层结构多级链表,最下层是原始的链表,每个层级都是下一个层级的“高速跑道”。

1.演示
下图简单演示过程。
1.1搜索
例子:查找元素 117
1.2插入
例子:插入 119, K = 2(索引层数)
丢硬币决定 K :插入元素的时候,元素所占有的层数完全是随机的,

1.3插入
例子:删除 71

2.代码
public class SkipList<K extends Comparable<? super K>, V> {
private static final Object BASE_HEADER = new Object();
private static final Random seedGenerator = new Random();
private transient volatile HeadIndex<K, V> head;
private transient int randomSeed;
public SkipList() {
head = new HeadIndex<K, V>(new Node<K, V>(null, BASE_HEADER, null), null, null, 1);
randomSeed = seedGenerator.nextInt() | 0x0100;
}
/**
* 打印跳跃表结果
*/
public void print() {
HeadIndex<K, V> q = head, p = q;
//打印索引数据
while (q != null) {
for (Index<K, V> r = q.right, d;;) {
if (r != null) {
Node<K, V> n = r.node;
K k = n.key;
System.out.print(k + " ");
d = r;
r = d.right;
} else
break;
}
System.out.println();
p = q;
q = (HeadIndex<K, V>) q.down;
}
//打印结点数据
Node<K, V> n = p.node.next;
while (n != null) {
Node<K, V> f = n.next;
System.out.print(n.key + " ");
n = f;
}
}
/**
* 根据key找到值
*/
@SuppressWarnings("unchecked")
public V get(K key) {
Node<K, V> b = findPredecessor(key);// 得到key的前驱结点
Node<K, V> n = b.next;
while (n != null) {
Node<K, V> f = n.next;
int c = key.compareTo(n.key);
if (c > 0) {
n = f;
continue;
}
if (c == 0) {
return (V) n.value;
}
}
return null;
}
/**
* 放入key和值
*/
public V put(K key, V value) {
Node<K, V> b = findPredecessor(key);// 得到key的前驱结点
Node<K, V> n = b.next;
while (n != null) {
Node<K, V> f = n.next;
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
return null;
}
break;
}
Node<K, V> z = new Node<K, V>(key, value, n);
b.next = z;
int level = randomLevel();//丢硬币决定
if (level > 0) {
insertIndex(z, level);
}
return value;
}
/**
* 根据key删除结点
*/
@SuppressWarnings("unchecked")
public V remove(K key) {
Node<K, V> b = findPredecessor(key);// 得到key的前驱结点
Node<K, V> n = b.next;
Node<K, V> f = null;
V v = null;
while (n != null) {
f = n.next;
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
v = (V) n.value;
break;
}
}
b.next = f;
n.value = null;
n.next = null;
findPredecessor(key);
HeadIndex<K, V> q = head;
while (q.right == null && q.level > 1) {
q = (HeadIndex<K, V>) q.down;
}
head = q;
return v;
}
// 执行插入操作:如上图所示,有两种可能的情况:
// 1.当level存在时,对level<=n都执行insert操作
// 2.当level不存在(大于目前的最大level)时,首先添加新的level,然后在执行操作1
private void insertIndex(Node<K, V> z, int level) {
HeadIndex<K, V> h = head;
int max = h.level;
if (level <= max) {// 情况1
Index<K, V> idx = null;
for (int i = 1; i <= level; ++i)// 首先得到一个包含1~level个级别的down关系的链表,最后的inx为最高level
idx = new Index<K, V>(z, idx, null);
addIndex(idx, h, level);// 把最高level的idx传给addIndex方法
} else { // 情况2 增加一个新的级别
level = max + 1;
Index<K, V> idx = null;
for (int i = 1; i <= level; ++i)// 该步骤和情况1类似
idx = new Index<K, V>(z, idx, null);
HeadIndex<K, V> oldh = head;
Node<K, V> oldbase = oldh.node;
HeadIndex<K, V> newh = new HeadIndex<K, V>(oldbase, oldh, null, level);// 创建新的;
head = newh;
addIndex(idx, newh, level);
}
}
/**
*在1~indexlevel层中插入数据
*/
private void addIndex(Index<K, V> idx, HeadIndex<K, V> h, int indexLevel) {
int insertionLevel = indexLevel;
int j = h.level;
Index<K, V> q = h;
Index<K, V> r = q.right;
Index<K, V> t = idx;
for (;;) {
if (r != null) {
int c = idx.node.key.compareTo(r.node.key);
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {// 在该层level中执行插入操作
q.link(t);
insertionLevel--;
if (insertionLevel == 0)
return;
t = t.down;
}
j--;
q = q.down;
r = q.right;
}
}
// 伪随机
private int randomLevel() {
int x = randomSeed;
x ^= x << 13;
x ^= x >>> 17;
randomSeed = x ^= x << 5;
if ((x & 0x8001) != 0)
return 0;
int level = 1;
while (((x >>>= 1) & 1) != 0)
++level;
return level;
}
private Node<K, V> findPredecessor(K key) {
for (Index<K, V> q = head, r = q.right, d;;) {
if (r != null) {
Node<K, V> n = r.node;
K k = n.key;
if (n.value == null) {
q.right = r.right;
r.right = null;
r = q.right;
continue;
}
int c = key.compareTo(k);
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if ((d = q.down) == null)
return q.node;
q = d;
r = d.right;
}
}
static final class HeadIndex<K, V> extends Index<K, V> {
final int level;
HeadIndex(Node<K, V> node, Index<K, V> down, Index<K, V> right, int level) {
super(node, down, right);
this.level = level;
}
}
static class Index<K, V> {
final Node<K, V> node;
final Index<K, V> down;
volatile Index<K, V> right;
Index(Node<K, V> node, Index<K, V> down, Index<K, V> right) {
this.node = node;
this.down = down;
this.right = right;
}
void link(Index<K, V> newSucc) {
Index<K, V> succ = right;
right = newSucc;
newSucc.right = succ;
}
}
static final class Node<K, V> {
final K key;
volatile Object value;
volatile Node<K, V> next;
Node(K key, Object value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
}
3.总结
跳跃的表的性质包括:
某个i层的元素,出现在i+1层的概率p是固定的,例如常取p=1/2或p=1/4;
平均来讲,每个元素出现在1/(1-p)个链表中;
最高的元素,例如head通常采用Int.MIN_VALUE作为的最小值,会出现在每一层链表中;
原始的链表元素如果是n,则链表最多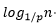
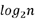
跳跃表的空间复杂度为O(n),插入删除的时间复杂度是