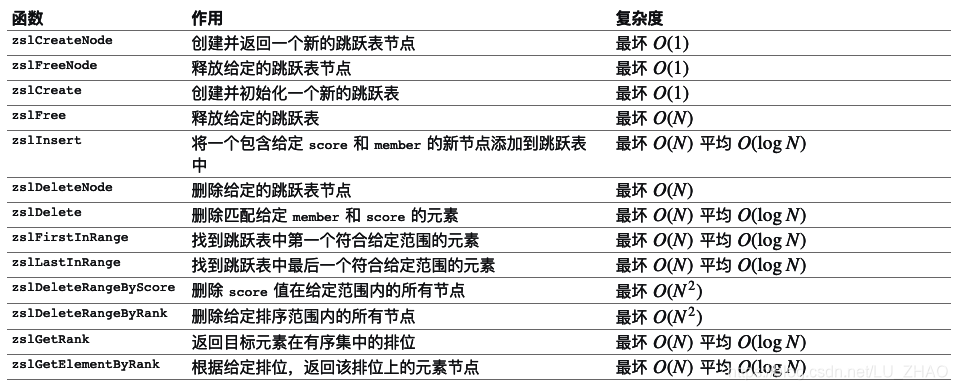
跳跃表(skiplist)是一种随机化的数据,跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美 —— 查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
从图中可以看到, 跳跃表主要由以下部分构成:
- 表头(head):负责维护跳跃表的节点指针。
- 跳跃表节点:保存着元素值,以及多个层。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾:全部由 NULL 组成,表示跳跃表的末尾。
跳跃表的实现
为了满足自身的功能需要, Redis 基于 William Pugh 论文中描述的跳跃表进行了以下修改:
- 允许重复的 score 值:多个不同的 member 的 score 值可以相同。
- 进行对比操作时,不仅要检查 score 值,还要检查 member :当 score 值可以重复时,单靠 score 值无法判断一个元素的身份,所以需要连 member 域都一并检查才行。
- 每个节点都带有一个高度为 1 层的后退指针,用于从表尾方向向表头方向迭代:当执行 ZREVRANGE 或 ZREVRANGEBYSCORE 这类以逆序处理有序集的命令时,就会用到这个属性。
跳跃表在 Redis 的唯一作用, 就是实现有序集数据类型。
这个修改版的跳跃表由 redis.h/zskiplist 结构定义:
typedef struct zskiplist {
// 头节点,尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前表内节点的最大层数
int level;
} zskiplist;
跳跃表的节点由 redis.h/zskiplistNode 定义:
typedef struct zskiplistNode {
// member 对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 这个层跨越的节点数量
unsigned int span;
} level[];
} zskiplistNode;
API: