1、什么是跳跃表
对于单链表来说,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是O(n)。

如果我们想要提高其查找效率,可以考虑在链表上建索引的方式。每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引。

这个时候,我们假设要查找节点8,我们可以先在索引层遍历,当遍历到索引层中值为 7 的结点时,发现下一个节点是9,那么要查找的节点8肯定就在这两个节点之间。我们下降到链表层继续遍历就找到了8这个节点。原先我们在单链表中找到8这个节点要遍历8个节点,而现在有了一级索引后只需要遍历五个节点。从这个例子里,我们看出,加来一层索引之后,查找一个结点需要遍的结点个数减少了,也就是说查找效率提高了,同理再加一级索引。

从图中我们可以看出,查找效率又有提升。在例子中我们的数据很少,当有大量的数据时,我们可以增加多级索引,其查找效率可以得到明显提升。
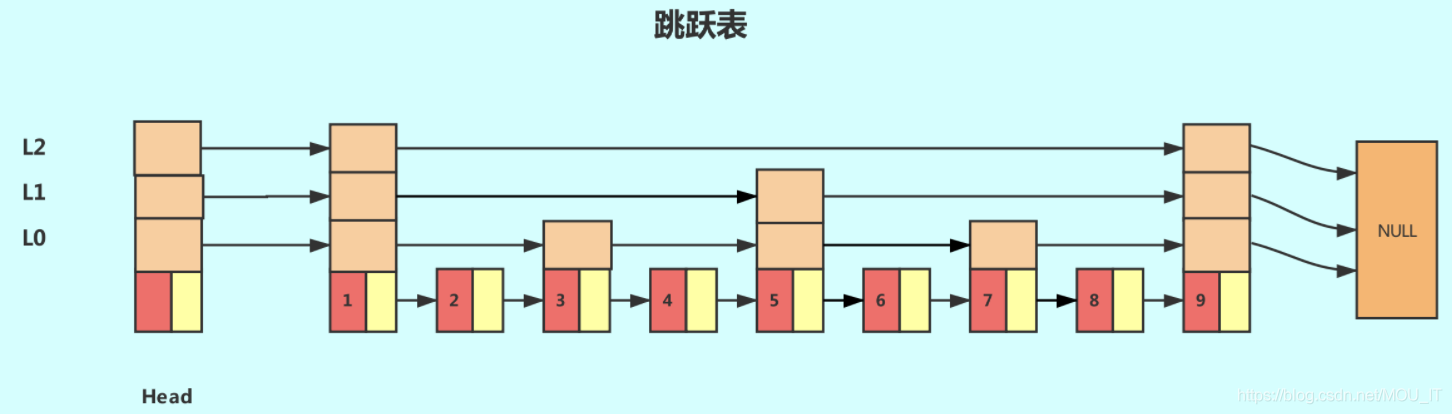
这种链表加多级索引的结构,就是跳跃表,每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,这个过程是通过一个随机函数生成器得到,这样子就构成了一个跳跃表。这就是为什么论文“Skip Lists : A Probabilistic Alternative to Balanced Trees ”中有“概率”的原因了,就是通过随机生成一个结点中指向后续结点的指针数目。跳跃表使用概率均衡技术而不是使用强制性均衡,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效。
2、跳跃表的实现
2.1 定义数据结构
struct skipNode {
int key;
int value;
int level; // size表示该节点存在的最高层数
skipNode* *next; //skipNode* 的数组
skipNode(int k, int v, int size) : key(k), value(v), level(size)
{
next = new skipNode*[size];
}
};
class skipList {
public:
skipList(int, int, float prob = 0.5, int maxNum = 10000);
~skipList();
skipNode* find(const int) const;
void erase(const int);
void insert(const int k, const int v);
protected:
// 获得新的level
int getNewLevel()const;
// 搜索指定key的附近节点
skipNode* search(const int) const;
private:
float cutOff; // 用于生成新的层级
int levels; // 当前已经分到了多少层
int maxLevel; // 层数上限
int maxKey; // key值上限
int dataSize; // 节点个数
skipNode* headerNode;
skipNode* tailNode;
skipNode** last; // 因为是单链结构,所以保存查找的节点的前一个节点
};2.2 初始化跳跃表
/* prob = 每隔 1/prob 个节点分一层
headKey = 头节点的key值,所有节点key值均不大于此key值
tailKey = 为节点的key值,所有节点key值均不大于此key值
maxNum = 跳表最大接受的节点个数
*/
skipList::skipList(int headKey, int tailKey, float prob, int maxNum)
{
cutOff = prob * RAND_MAX;
maxLevel = (int)ceil(logf((float)maxNum) / logf(1 / prob));
levels = 0;
maxKey = headKey;
dataSize = 0;
//初始化头尾节点
headerNode = new skipNode(headKey, 0, maxLevel + 1);
tailNode = new skipNode(tailKey, 0, 0);
//上次对比的节点
last = new skipNode*[maxLevel + 1];
//初始化头尾节点指向
for (int i = 0; i <= maxLevel; i++)
headerNode->next[i] = tailNode;
}
skipList::~skipList()
{
skipNode* node;
// 第0层包含了所有的节点
while (headerNode != tailNode)
{
node = headerNode->next[0];
delete headerNode;
headerNode = node;
}
delete tailNode;
delete[] last;
}
/* 利用随机数是否大于cutoff值获得新的level值,但新的level值不超过maxLevel,防止浪费 */
int skipList::getNewLevel() const
{
int lev = 0;
while (rand() <= cutOff)
lev++;
return lev <= maxLevel? lev: maxLevel;
}
skipNode* skipList::search(const int theKey) const
{
if (theKey > maxKey)
return NULL;
skipNode* node = headerNode;
for (int i = levels; i >= 0; i--)
{
while (node->next[i]->key < theKey)
node = node->next[i];
/* 因为节点处在单链上,所以,这里保存该节点的前一个节点,方便插入 */
last[i] = node;
}
return node->next[0];
}
2.3 查找
查找就是给定一个key,查找这个key是否出现在跳跃表中,如果出现,则返回其值,如果不存在,则返回不存在。
skipNode * skipList::find(const int theKey) const
{
if (theKey >= maxKey)
return NULL;
skipNode* node = headerNode;
for (int i = levels; i >= 0; i--)
while (node->next[i]->key < theKey)
node = node->next[i];
if (node->next[0]->key == theKey)
return node->next[0];
return NULL;
}2.4 插入
插入包含如下几个操作:
- 查找到需要插入的位置;
- 申请新的结点;
- 调整指针;
void skipList::insert(const int k, const int v)
{
if (k > maxKey) {
cout << "key = " << k << "不能比maxKey = " << maxKey << "大" << endl;
return;
}
skipNode* node = search(k);
/* 节点已存在 */
if (node->key == k)
{
node->value = v;
return;
}
/* 节点不存在, 此时node在新加的节点右侧,生成新的层次 */
int newLevel = getNewLevel();
if (newLevel > levels)
{
newLevel = ++levels;
last[newLevel] = headerNode;
}
skipNode* newNode = new skipNode(k, v, newLevel);
/* last节点数组保存了该节点的前一个节点, 每一层都插入 */
for (int i = 0; i <= newLevel; i++)
{
newNode->next[i] = last[i]->next[i];
last[i]->next[i] = newNode;
}
dataSize++;
return;
}2.5 删除
删除操作类似于插入操作,包含如下3步:
- 查找到需要删除的结点
- 删除结点
- 调整指针
void skipList::erase(const int theKey)
{
if (theKey > maxKey)
return;
skipNode* node = search(theKey);
if (node->key != theKey)
return;
for (int i = 0; i <= levels && last[i]->next[i] == node; i++)
last[i]->next[i] = node->next[i];
/* 删除没有数据的层 */
while (levels > 0 && headerNode->next[levels] == tailNode)
levels--;
delete node;
dataSize--;
}2.6 主函数
int main()
{
skipList list(999, 1000);
list.insert(1, 100);
list.insert(3, 300);
list.insert(2, 200);
list.insert(7, 700);
list.insert(6, 600);
list.insert(4, 400);
list.insert(5, 500);
skipNode* node = list.find(3);
list.erase(3);
node = list.find(3);
}