SkipList跳跃表
有序的数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
平均时间复杂度:
底层无索引的链表:
带索引,如果需要找中间的某个节点,比如寻找 42 ,过程大概是这样的:
数据结构
哈希表结构
作为字典的底层实现
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//指向zskiplistNode的头、尾节点
unsigned long length;//底层节点的个数
int level;//当前最高索引层数
} zskiplist;
跳跃表节点
typedef struct zskiplistNode {
sds ele;
double score;//分数
struct zskiplistNode *backward;//前一个节点的指针
struct zskiplistLevel {
struct zskiplistNode *forward;//下一个节点的指针
unsigned int span;
} level[];//该节点在哪一些层级嗯。
} zskiplistNode;

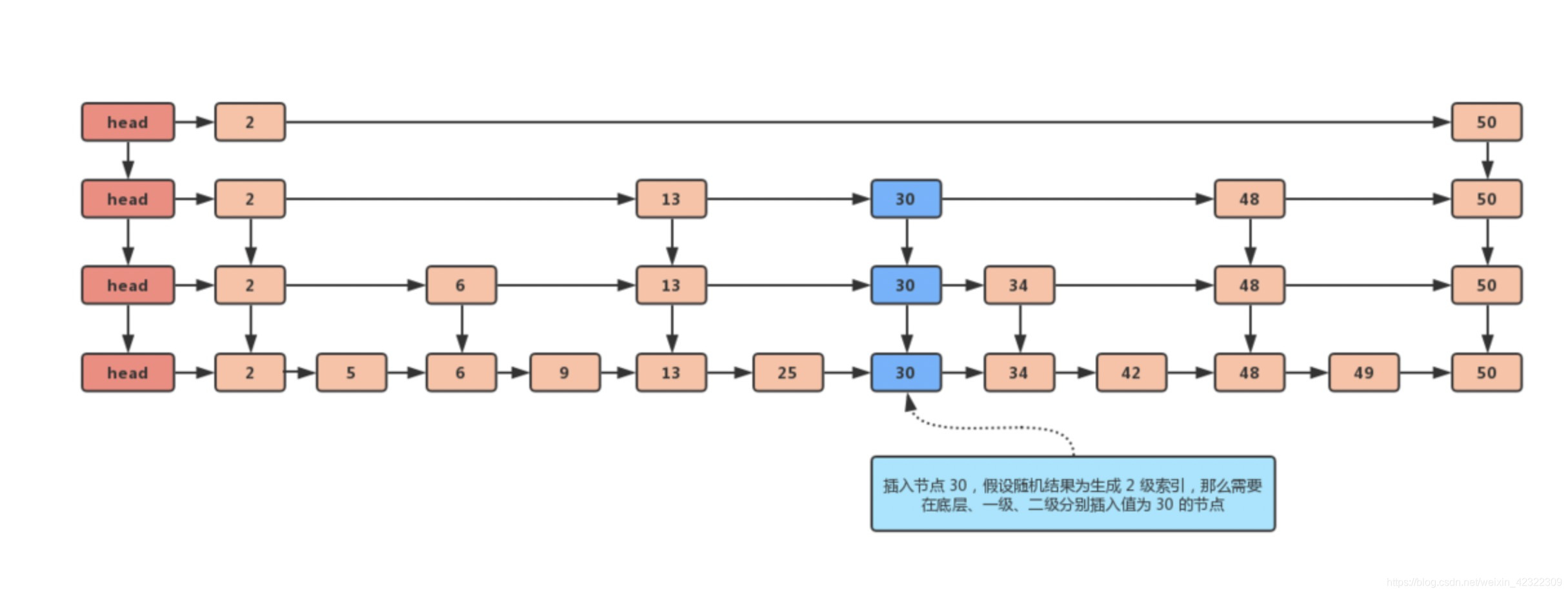
插入节点
在最底层的数据链表中插入数据,然后调整索引;
其中每一层的索引链表中是否需要增加新增的节点,其实并没有什么标准答案,我们尽量做到索引的平均分布即可,常用的就是【随机判断】决定是否需要新增或调整索引,当有新节点插入的时候,通过概率算法判断这个节点需要插入到几级节点中。
比如:
- 底层数据链表有 N 个元素,随机选择 N/2 个元素作为 1 级索引,随机选择 N/4 个元素作为 2 级索引…一直到顶层索引;
- 新插入数据节点,1/2 概率不插入任何一级索引,1/4 概率返回需要插入 1 级索引,1/8 概率返回需要插入到 2 级索引,以此类推;
- 这里要注意一点,插入 2 级索引的时候,同时也需要插入 1 级索引;也就是插入 n 级索引的时候,同时也要插入 1~( n-1 ) 级索引。
删除节点
删除数据节点,并删除每一层的索引节点
总结
- 可以把跳跃表看成多个有序链表(最底层的数据链表+多层索引链表);
- 查找的过程中,从最长层开始查找,找到对应的区间再到下一层查找 ;
- 每个节点都有两个指针,分别指向右边和下边;
- 插入新节点时,随机判断该节点是否要插入索引,最高插入几级索引;
- 插入 n 级索引的时候,同时也要插入 1~(n-1) 级索引;
- 跳跃表和红黑树等平衡树相比,更容易实现,并且不需要维护平衡性;
- Redis 中的 ZSet 的一种实现方式是 skipList 与 hashTable 的结合;
- Google 的 LevelDB 、Facebook 的 RocksDB ,它们都是使用了跳跃表这种数据结构。