Spark Streaming的核心
1.核心概念
StreamingContext:要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark StreamingContext功能的主要入口点。
一个StreamingContext对象可以由SparkConf对象来创建,需要指定Seconds。
import org.apache.spark._ import org.apache.spark.streaming._ val conf = new SparkConf().setAppName(appName).setMaster(master) val ssc = new StreamingContext(conf, Seconds(1))
注意点:batch interval可根据你的应用程序需求的延迟要去以及集群可用的资源情况来设置
一个StreamingContext对象也可以由已存在SparkContext对象来创建,需要指定Seconds。
import org.apache.spark.streaming._ val sc = ... // existing SparkContext val ssc = new StreamingContext(sc, Seconds(1))
为什么可以通过SparkConf或是SparkContext对象创建StreamingContext对象呢?
#通过阅读源码中StreamingContext.scala去了解
class StreamingContext private[streaming] ( sc_ : SparkContext, cp_ : Checkpoint, batchDur_ : Duration #多久执行一次 ) extends Logging{ #this是附属构造器 def this(sparkContext: SparkContext, batchDuration: Duration)={ this(sparkContext, null, batchDuration) } #传进一个SparkConf,调用StreamingContext.createNewSparkContext返回的是一个sparkContext,最后调用了上面this这个附属构造器 def this(conf: SparkConf, batchDuration: Duration)={ this( StreamingContext.createNewSparkContext(conf),null,batchDuration) }
一旦StreamingContext定义好之后,可用做以下事情:
-
- 通过input DStreams来定义输入源;如果要处理hdfs上文件,通过StreamingContext拿到一个输入的DStreams
- 通过对DStreams应用transformation和output操作来定义流计算
- 开始接收数据并使用streamingContext.start()处理它
- 等待使用streamingContext.awaitTermination()停止处理(手动或由于任何错误)
- 可以使用streamingContext.stop()手动停止处理
注意事项:
-
-
- 一旦streamingContext启动,就不能设置或是添加新的流计算
- 一旦streamingContext停止了,就不能重启它;
- 只能有一个streamingContext存活在JVM中
- StreamingContext上的stop()也会停止SparkContext。 要仅停止StreamingContext,请将stop()的可选参数stopSparkContext设置为false。
- 只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext),就可以重复使用SparkContext创建多个StreamingContexts
-
DStreams(Discretized Streams):是Spark Streaming提供的基本抽象,它表示持续化的数据流,可从输入数据流接收过来,也可以是输入流通过transform操作转成另一个Dstream;本质上,一个DStream代表这一系列连续的RDDs,DStream中每个RDD都包含来自特定时间间隔(batch interval)的数据。

对DStream操作算子,比如map/flatMap,其实底层会被翻译为对DStream中每个RDD都做相同的操作,因为一个DStream是由不同批次的RDD所构成的。

InputDStream:是一个DStream,表示输入数据的流是从源头接收过来的;每个input DStream都需要关联一个receivers对象,receivers对象从源头接收数据并将该数据存储在Spark的内存中以供后期进行处理,但是InputDStream如果是文件系统,就不需要关联receivers对象,因为数据已经存储在文件系统上了不需要receivers对象去接收数据,直接通过文件系统的api访问返回的就是一个DStream。
Spark Streaming中提供了两种内置的流源:
基本来源:StreamingContext API中直接提供的源。 示例:文件系统和套接字连接。
高级资源:Kafka,Flume,Kinesis等资源可通过额外的实用程序类获得。 这些需要链接到额外的依赖项,如链接部分所述。
2.Transformations Operations: 与RDD类似,转换允许修改来自输入DStream的数据。 DStreams支持普通Spark RDD上可用的许多转换。
一些常见的Transformations Operations有:map,flatMap,filter,union,count等等
3.Output Operations:该操作允许将DStream的数据推送到外部系统,如数据库或文件系统。 由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有DStream转换的实际执行(类似于RDD的操作)。 目前,定义了以下output operations:print,saveAsTextFile, foreachRDD等等
4.案例实战
案例一:Spark Streaming处理socket数据
/** *Spark Streaming 处理Socket数据 * 测试,使用nc -lk 9999 */ object NetworkWordCount{ def main(args:Array[String]): Unit = { val sparkConf = new SparkConf().setMaster('local[2]').setAppName('NetworkWordCount') #创建StreamingContext需要SparkConf和batch interval val ssc = new StreamingContext(sparkConf,Seconds(5)) val lines = ssc.socketTextStream('localhost',9999) val result = lines.flarMap(_.split(" ")).map((_,1)).reduceByKey(_+_) result.print() ssc.start() ssc.awaitTermination() } }
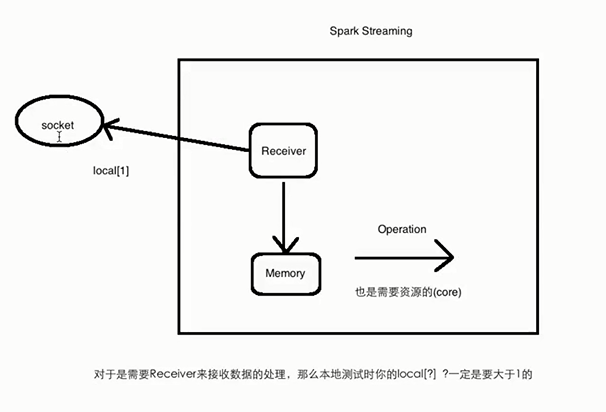
对于需要Receiver接收的数据的处理,本地测试时local[?]为什么要大于1?
因为receiver需要一个线程来接收数据,后面的operation也需要线程来处理。
案例二:Spark Streaming处理HDFS文件数据
/** *Spark Streaming 处理文件系统(local,hdfs)数据 */ object FileWordCount{ def main(args:Array[String]): Unit = { val sparkConf = new SparkConf().setMaster('local').setAppName('FileWordCount') #创建StreamingContext需要SparkConf和batch interval val ssc = new StreamingContext(sparkConf,Seconds(5)) val lines = ssc.textFileStream("file://Users/rocky/data/imooc/ss/") #监控指定文件夹下数据 val result = lines.flarMap(_.split(" ")).map((_,1)).reduceByKey(_+_) result.print() ssc.start() ssc.awaitTermination() } }
#注意事项:监控文件夹下的添加的文件需要相同的格式;对于递归的子目录情况是不支持的;不能在已有文件中添加内容,添加了也不会被处理,因为处理过的文件将不会再被处理文件必须以原始性方式创建