版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/83341924
1 源码
package mystreaming
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object AccWordcount {
/*
* (hello,1),(hello,1),(tom,1)
* (hello,Seq(1,1)),(tom,Seq(1))
* Option[Int],以前的结果
* Seq 这个批次某个单词的次数
*
* */
val func = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.map{case(word,current_count,history_count) => (word,current_count.sum + history_count.getOrElse(0)) }
//iter.map(t=>(t._1,t._2.sum + t._3.getOrElse(0)))
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(m => (x, m)) }
}
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
val conf = new SparkConf().setAppName("AccWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
/*
* updateStateByKey 必须设置 checkpoint
* */
sc.setCheckpointDir("d://checkpoint")
//接收数据
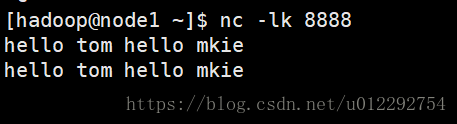
val ds = ssc.socketTextStream("node1", 8888)
//DStream 是一个特殊的 RDD
val result = ds.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(func,new HashPartitioner(sc.defaultParallelism),true)
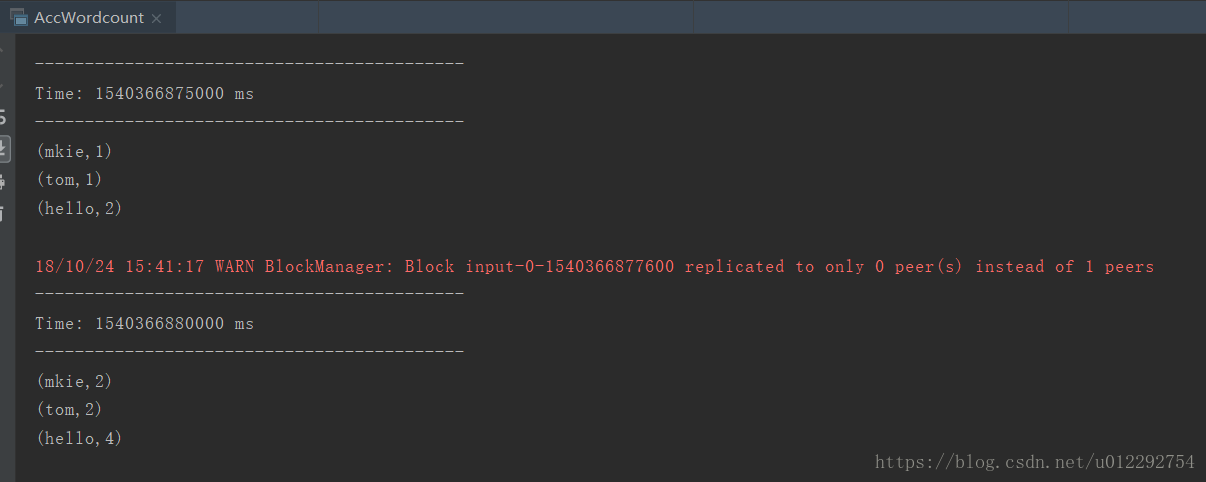
result.print()
ssc.start()
ssc.awaitTermination()
}
}
2 测试