Learning Semantic Concepts and Order for Image and Sentence Matching
CVPR 2018
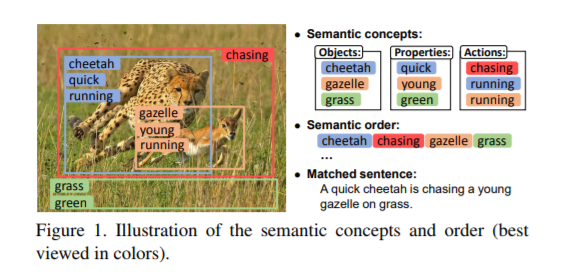
一、Motivation
目前该领域主要问题之一是像素级别的图片描述缺少高层次的语义信息,之前的做法都是提取一个全局的CNN特征向量。这样一些主要的信息就会占据主导地位,背景一些的就会被忽略。这篇文章提出了语义增强图片及语句匹配模型。
二、Model
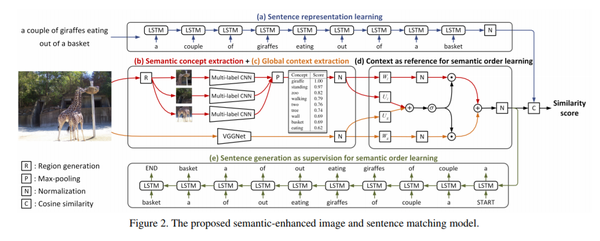
1.Sentence Vector:LSTM得到文本特征,最后一个时间步的隐藏状态为s(维度为H)
2.Semantic Concept Extraction:提取图像的多个proposal,然后用multi-label CNN对每一个proposal进行分类得到多个(proposal的个数)分类的向量,然后利用element-wise max-pooling得到一个向量(scores vector)为p
即:对于图像,先生成一堆区域框,然后将这些框拉伸成正方形给定的大小。上图中的region生成的方法参照了{ Cnn: Single-label to multi-label. arXiv, 2014}中的方法。然后分别放入到CNN中去。
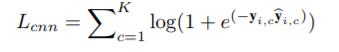
图片多标签loss function,K个词汇
3.Global Context Extraction:用VGG提取图像的全局特征向量(global vector)为g
4.Feature Confusion(gated fusion unit):将scores vector与global vector通过a gated manner融合得到一个融合后的向量(final vector)为v
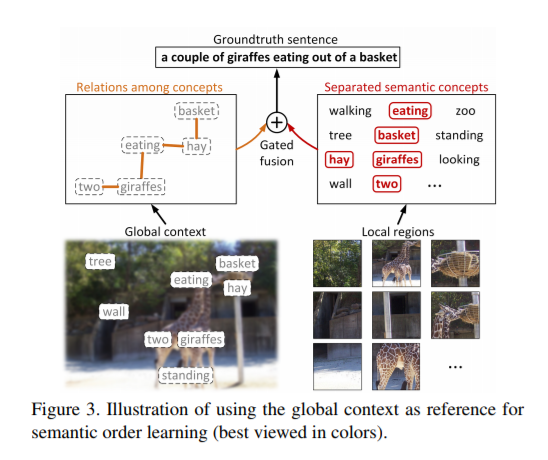
全局和局部特征组合在一起。但是它们(全局和局部)的重要性在不同图幅间并不是一致的。这篇文章最大的亮点在这儿,设计了一个gated fusion unit门融合单元。 门控单元融合:可以有选择的平衡语义概念和上下文的相对重要性
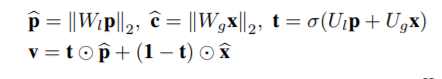
三、Joint Matching and Generation
图片总是能训练得到一个语句,但是要匹配相同的意思准确性不高。直接匹配的方法并不太好,这篇文章使用语句监督(ground truth semantic)图片特征向量生成的语句。
共同执行图像和句子匹配以及句子生成,最小化以下组合目标函数:
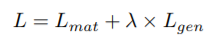
匹配目标函数:
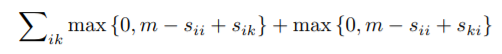
生成目标函数:
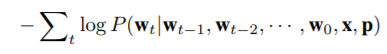
由x和p计算图像特征v,然后将其与句子特征s进行比较以获得它们的余弦相似度得分
四、总结
亮点在于:
1.提取高层次的语义信息
2.设计了一个gated fusion unit门融合单元将全局和局部特征组合在一起(全局和局部的重要性在不同图幅间并不一致)
3.用语句生成作为图像特征学习的监督