Contribution
- 提出一个新颖的recurrent filter learning 框架从而去捕捉空间与时间信息,并且不要求在线fine-tune(on tracking)
设计一个高效有效的初始化和更新target appearance 方法,具体而言就是conv LSTM作为记忆单元更新目标表观
网络结构
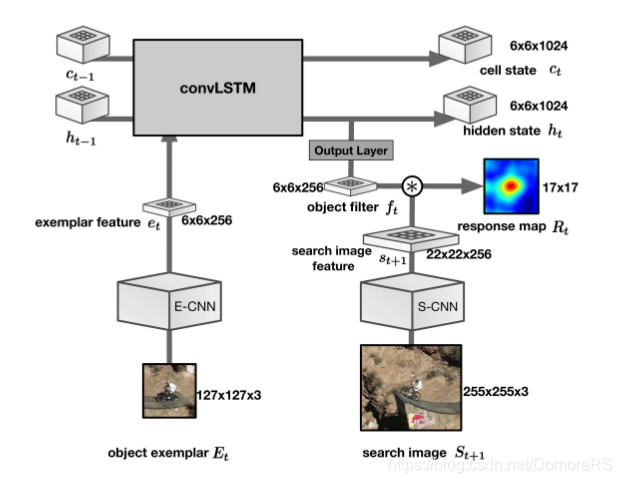
从groundtruth来crop object exemplar \(E_{t}\)(127 * 127 * 3)经过E-CNN(exemplar feature extractor),得到exemplar feature\(e_{t}\)(6 * 6 * 256),作为conv-LSTM的输入,conv-LSTM接收\(e_{t}\),还接受上一个状态的hidden state \(h_{t-1}\)和cell state \(c_{t-1}\),产生当前状态的hidden state \(h_{t}\)(6 * 6 * 1024)和cell state \(c_{t}\)(6 * 6 * 1024), 产生的hidden state \(h_{t}\) 经过output layer(1 * 1 * 256的卷积核) 产生 object filter \(f_{t}\) (6 * 6 * 256),在下一帧的Search image \(S_{t+1}\)(255 * 255 * 3)经过 S-CNN 特征提取之后得到Search image feature(22 * 22 * 256)进行correlation 操作(实际是卷积)得到响应映射\(R_{t}\)(17 * 17)
S-CNN 与E-CNN
S-CNN 与E-CNN参数是不同的(实验证明这样的效果是最好的),卷积网络结构是相同的网络如图
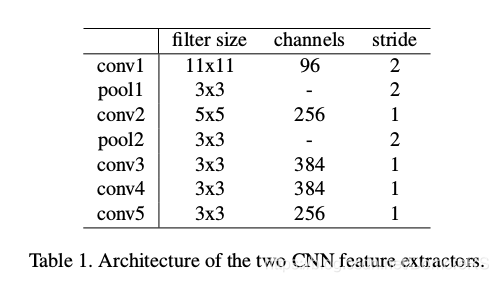
conv 之后都有用BatchNormalization加速网络收敛,除了Conv-5 ,都用激活函数ReLu
convolutional LSTM 的结构
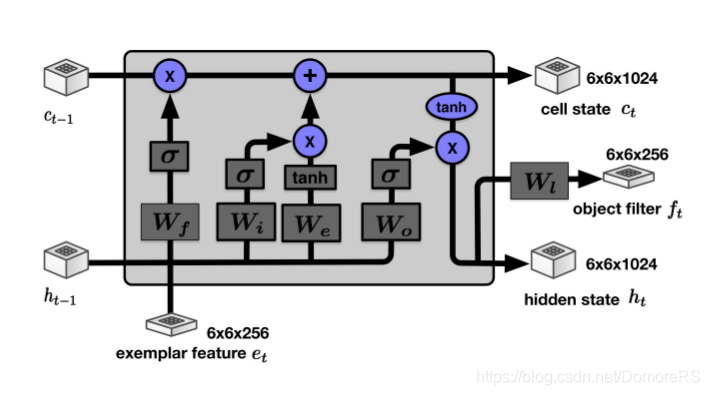
结构与原始的LSTM结构相似,只不过sigmod前面加了卷积层(3 * 3 filter),保存图像的空间结构
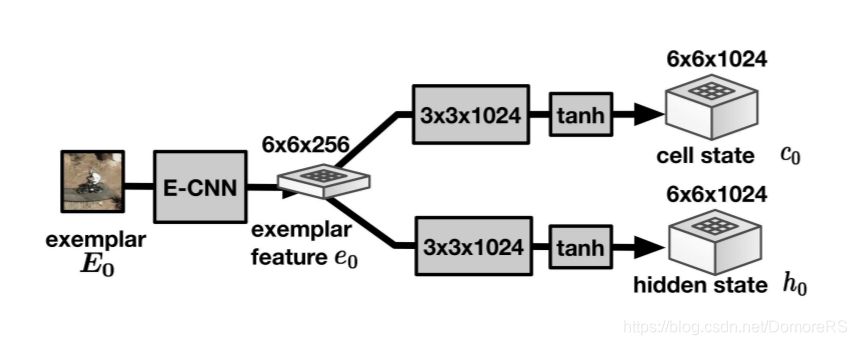
初始化cell state \(c_{0}\),hidden state \(h_{0}\)第一帧的exemplar 用E-CNN提取\(e_{0}\)再用(3* 3 *1024)conv filter 进行的卷积在经过tanh 初始化完成。
loss fuction
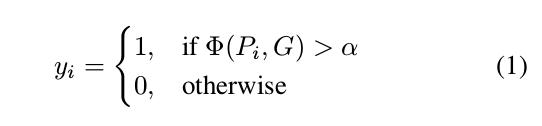
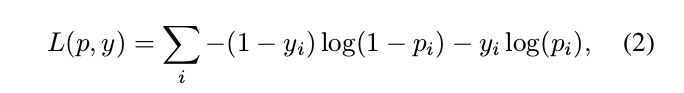
Training Details
mini-batchSize是长度为10的10个视频剪辑, 数据增广,随机干扰色,图片镜像变换,拉伸等,
Online tracking
我们没有用BBox regression,而是用bicubic 插值做,选择最大值位置作为目标位置,并构建尺度金子塔
\(R^{m}(f_{t},s_{t+1}) = f_{t}*s_{t+1}^m\)
\(v^m\)是 response map \(R^m\)在尺度m上的最大值.
找到\(v^m\)最大的那个尺度
在尺度m 上求出前k个score的平均位置,
\(p^{*}=\frac{1}{K}\sum\limits_{k}^{K}{p_{k}}\)