传统验证码识别:传统方法通常是先对验证码图像进行字符分割,再进行特征提取、最后通过分类器得到结果。一些验证码加入噪声或线条,字符位置不固定及粘连时,字符分割效果不好,也会影响后续字符识别。除了只包含字母和数字的验证码,国内还有一些识别汉字的验证码、计算加减乘除的验证码、图像匹配和图像分类的验证码,各种各样。
深度学习验证码识别:深度学习做验证码识别是采用了多任务分类的思路。
多任务学习是针对数据给出多个监督信息(标签)进行学习,例如识别一张图像中的脸是否是人脸、脸部表情、性别、年龄等属于多任务分类。用深度学习做多标签分类,是对整张验证码图片进行多标签学习,来完成多任务分类,端到端的识别出验证码中的所有字符。这种思路同样可以用于车牌识别中。
深度学习方法,不需要进行字符分割,不需要繁杂的预处理,直接端到端识别验证码效果很好。劣势也很明显,对不同手段生成的不同风格的验证码,都需要收集、爬取或模仿其验证码风格自己写代码生成大量样本,以维持较高的识别率。
数据集准备
1、该数据集有训练集64536张,验证集9096张,测试集714张,图片大小为88*28,共有数字0-9和大写字母A-Z共36类,每张验证码图像中包含四个字符,数据集下载:https://pan.baidu.com/s/1ZeujoRrq5J6q8sRBxDD-dQ。

2、这个数据集更复杂,生成验证码图像时使用了6种字体并加入随机线条、字体变形、旋转、随机赋色等处理。每张验证码图像中包含五个字符,其验证码生成程序来源github:https://github.com/Gregwar/Captcha。
数据格式转换
没有使用均值文件,采用了ImageNet数据集的均值作为样本均值,ImageNet数据集的均值具有统计特性,而我们的样本又是随机生成的,所以这是合理的做法。
网络结构文件准备
新建文件夹captcha在以下路径:caffe根目录\examples\captcha
并将caffe根目录\models\bvlc_alexnet下以下3个文件复制过来,重命名并进行修改

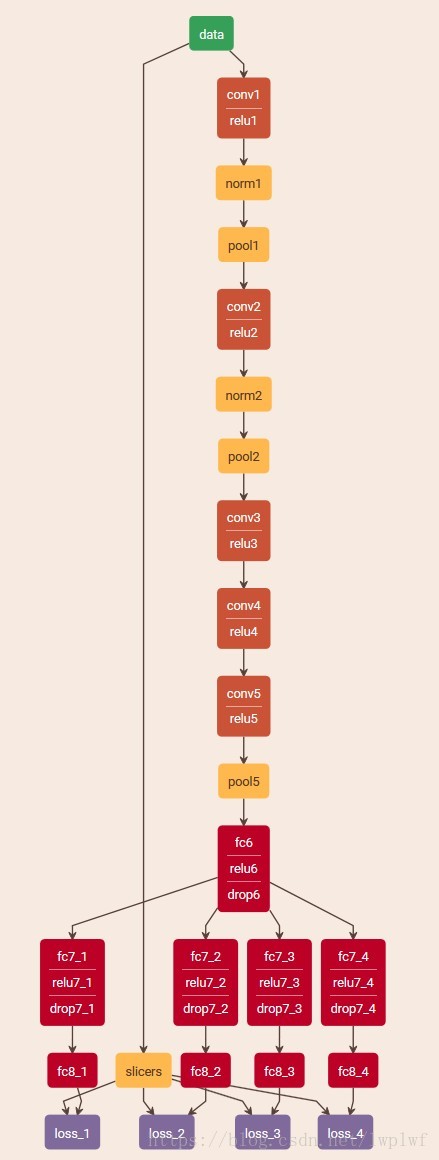
AlexNet是单标签分类网络,而现在进行验证码识别的思路是多标签分类,输入一张验证码图像输出多路分类结果。
修改网络结构文件captcha_train_val.prototxt:
(1)fc6及前面的层保持不变,在fc6后连接5个全连接层fc7_1、fc7_2、fc7_3、fc7_4(原先只有1个全连接层fc7),这些全连接层同样经过relu层和dropout层;
(2)然后分别与全连接层fc8_1、fc8_2、fc8_3、fc8_4相连,节点个数改成36(0-9、A-Z共36类);
(3)再由Slice层分割的多标签label_1、label_2、label_3、label_4分别和fc8_1、fc8_2、fc8_3、fc8_4一起接上各自对应的accuracy层(test模式下)和loss层。
模型文件下载:https://pan.baidu.com/s/1KS1BimYnHtqwMDBbhpt8Vw
训练
制作训练脚本train_captcha.sh
内容如下:
#!/usr/bin/env sh
set -e
./build/tools/caffe train --solver=examples/captcha/captcha_solver.prototxt $@
开始训练
Caffe根目录下执行:
./examples/captcha/train_captcha.sh
Reference
http://note.youdao.com/noteshare?id=788fd42b39d2af33c7022cddc8629f06
https://blog.csdn.net/sinat_14916279/article/details/56489601?locationNum=10&fps=1