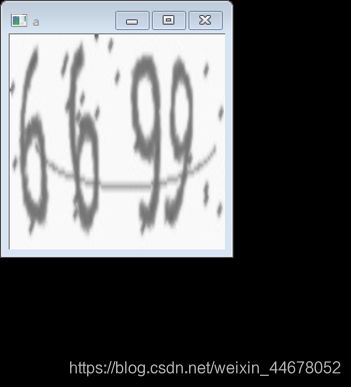
验证码识别与之前的几个任务不同,这是一个多标签的分类的任务,也就是是一个数据对应着几个标签,只有所用的标签都预测对时,才算真正的预测成功了。
一. 数据的准备工作
- 与以往不同,这次的数据,我们是利用python的第三方库来生成验证码图片,下面进行代码演示,非常简单。
a = ['1','2','3','4']
img = ImageCaptcha()
captcha=img.generate(a) #生成图片,根据a中的内容
captcha_image = PIL.Image.open(captcha) #读取图片
captcha_image.show() #显示图片
2. 基于上面的代码我们可以很轻松装备几万张数据,然后用一个Excel保存图片以及图片对应的标签,这里就不作代码展示了,展示一下Excel文件。

3. 下面开始读取我们的Excel文件,来构造我们的数据集,标签有4个,这里我们需要one-hot编码一下,弄成长度为40的向量,这也是一个需要特别需要注意的地方。
- . 读取csv文件
def read_data():
data = pd.read_csv("qwe.csv")
img_path = data["ID"].values
label = data.iloc[:,data.columns!="ID"].values
y = []
for x in label:
t = one_hot(x)
y.append(np.array(t))
return img_path,np.array(y)
- 进行one-hot编码
def one_hot(x):
tmp = [0 for i in range(40)]
for step,i in enumerate(x):
tmp[i+10*step] = 1
return tmp
- 最后构造DataLoader,与显示最后的标签形式,到这里数据的准备工作就基本上完成了。
class DataSet(Dataset):
def __init__(self):
self.img_path,self.label = read_data()
def __getitem__(self, index):
img_path = self.img_path[index]
img = cv2.imread(img_path,0)
img = img/255.
img = torch.from_numpy(img).float()
img = torch.unsqueeze(img,0)
label = torch.from_numpy(self.label[index]).float()
return img,label
def __len__(self):
return len(self.img_path)
data = DataSet()
data_loader = DataLoader(data,shuffle=True,batch_size=64,drop_last=True)

二. 网络的构建与优化、损失函数的选取以及训练
- 网络的构建和优化函数在这里就不做多的说明了,直接看代码。
class CNN_Network(nn.Module):
def __init__(self):
super(CNN_Network, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, stride=1, kernel_size=3, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, stride=1, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(stride=2, kernel_size=2), # 30 80
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, stride=1, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2), # 15 40
)
self.fc = nn.Sequential(
nn.Linear(128 * 15 * 40, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 40)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
model = CNN_Network()
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
- 损失函数我们这里使用的是多标签分类的损失函数,和交叉熵损失函数的公式比较相像, l o s s ( x , y ) = − ∑ i y [ i ] ∗ l o g ( 11 + e x p ( − x [ i ] ) + ( 1 − y [ i ] ) ∗ l o g ( e x p ( − x [ i ] ) 1 + e x p ( − x [ i ] ) ) loss(x,y)=−∑iy[i]∗log(11+exp(−x[i])+(1−y[i])∗log(exp(−x[i])1+exp(−x[i])) loss(x,y)=−∑iy[i]∗log(11+exp(−x[i])+(1−y[i])∗log(exp(−x[i])1+exp(−x[i])),上面是公式,有兴趣的可以自己研究一下。
error = nn.MultiLabelSoftMarginLoss() #注意输入的数据要是float32类型的,否则会出错。
- 所有的准备工作都完成了,下面就开始训练吧。
for i in range(2):
for x_index,y in data_loader:
pass
x = Variable(x_index)
optimizer.zero_grad()
label = Variable(y)
out = model(x)
loss = error(out,label)
print(loss)
loss.backward()
optimizer.step()
torch.save(model.state_dict(),"验证码识别.pth")
三. 测试模型
- 训练完成后,来测试一下我们的模型吧.
cnn = CNN_Network()
cnn.load_state_dict(torch.load("验证码识别.pth"))
a = cv2.imread("./data/9354.jpg",0)
b = cv2.resize(a,(200,200))
cv2.imshow('a',b)
cv2.waitKey(0)
a = a/255.
a = torch.from_numpy(a).float()
a = torch.unsqueeze(a,0)
a = torch.unsqueeze(a,0)
pred = cnn(a)
print(pred.size())
a1 = torch.argmax(pred[0,:10],dim=0) #第一个标签
a2 = torch.argmax(pred[0,10:20],dim=0) #第二个标签
a3 = torch.argmax(pred[0,20:30],dim=0) #第三个标签
a4 = torch.argmax(pred[0,30:],dim=0) #第四的标签
pred = [a1,a2,a3,a4]
print(pred)