写代码爽 一直写代码一直爽…
终于觉得写代码不是多么阔怕又头疼的事情了…
因为臣妾记不住呀
#课程来自x马



如何建立全连接层输出
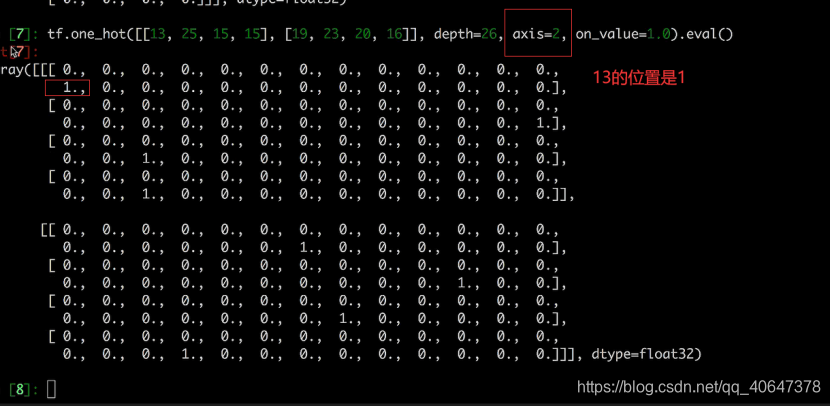
转换成二维计算损失

再转换成3维梯度下降



app.flags.DEFINE_string("tfrecords_dir","./tfrecords/captcha.tfrecords",
app.flags.DEFINE_string("captcha_dir","../data/Genpics/","验证码路径")
app.flags.DEFINE_string("letter","ABCDEFGHIJKLMNOPQRSTUVWXYZ","验证码字符的种类")
def dealwithlabel(label_str):
#构建字符索引{0:“A",1:"B”....}
num_letter=dict(enumerate(list(FLAGS.letter)))#enumerate就是给序列
#键值对反转{0:“A",1:"B”....}
letter_num=dict(zip(num_letter.values(),num_letter.keys()))
#zip是给它合成元祖一样的东西
print(letter_num)
#构建标签的列表
array=[]
#给标签数据进行处理
for string in label_str:
letter_list=[] #[13,25,15,15]
#修改编码,b"FVQJ"到字符串,并且循环找到每张验证码的字符对应的数字标记
for letter in string.decode("utf-8")
letter_list.append(letter_num[letter])
array.append(letter_list)
#[[13,25,15,15],[22,10,7,10],[22,15,18,9],[16,6,13,10]]
print(array)
#将array转换成tensor类型,先不转成 one-hot 浪费空间
label=tf.constant(array)
return label
def get_captcha_image():
#获取验证码图片数据
filename=[]
for i in range(6000):
string=str(i)+".jpg"
filename.append(string)
#构造路径+文件
file_list=[os.path.join(FLAGS.captcha_dir,file) for file in filename]
#构造文件队列
file_queue=tf.train.string_input_producer(file_list,shuffle=False)
#构造阅读器
reader=tf.WholeFileReader()
#读取图片数据内容
key,value=reader.read(file_queue)
#解码图片数据
image=tf.image.decode_jpeg(value)
image.set_shape([20,80,3])#h80 w 20 彩色
#批处理数据
image_batch=tf.train.batch([image],batch_size=6000,num_threads=1,capacaity=6000]
return image_batch
def get_captcha_label():
file_queue=tf.train.string_input_producer(["../data/Genpics/labels.csv",shuffle=False]
#不指定shuffle 就会是乱序的
reader=tf.TextLineReader()
key,value=reader.read(file_queue)
records=[[1],["None"]] #第一列是int类型 第二列是string类型
number,label=tf.decode_csv(value,record_defaults=records)
#验证码的目标值 [["NZPP"],["WKHK"],["ASDY"]]
label_batch=tf.train.batch([label],batch_size=6000,num_threads=1,capacaity=6000]
return label_batch
def write_to_tfrecords(label_batch,image_batch):
#转换类型
label_batch=tf.cast(label_batch,tf.uint8)
print(label_batch)
#建立tfrecor存储器
writer=tf.python_io.TFRecordWriter(FLAGS.tf.records_dir)
#循环将每一图片上的数据构造example协议块,序列化后写入
for i in range(6000):
#取出第i个图片数据,转换成相应的类型,图片的特征要换转成字符串形式
image_string=image_batch[i].eval().tostring()
#标签值,转换成整形 它不是一个
label_string=label_batch[i].eval().tostring()
#构造协议块
example=tf.train.Example(features=tf.train.Features(feature={
"image":tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_string]))
"label":tf.train.Feature(bytes_list=tf.train.BytesList(value=[label_string]))
}))
writer.write(example.SerializeToString())#循环一下
#关闭文件
writer.close()
return None
if __name__=="__main__":
#获取验证码文件当中的图片
image_batch=get_captcha_image()
#获取验证码文件当中的标签数值
label=get_captcha_label()
print(image_batch,label)
with tf.Session() as sess:
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(sess=sess,coord=coord)
#[b"NZPP" b“WKHK" b"WPSJ"...]
label_str=sess.run(label)
print(label_batch)
#处理字符串标签到数字张量
label_batch=dealwithlabel(label_str)
print(label_batch)
#将图片数据和内容写到tfrecords文件当中
write_to_tfrecords(image_batch,label_batch)
coord.request_stop()
coord.join(threads)
训练识别5000个图片验证码
import tensorflow as tf
FLAGS=tf.app.flags.FLAGS
tf.app.flags.DEFINE_string(“captcha_dir","./tfrecords/captcha.tfrecords","验证码数据的路径")
tf.app.flags.DEFINE_integer("batch_size",100,"每批次读取的样本数“)
tf.app.flags.DEFINE_integer("letter_num",26,"每个目标值取的字母的可能性个数“)
tf.app.flags.DEFINE_integer("label_num",4,"每个目标值取的字母的目标值的数量“)
#这样你以后换了对象可以直接在这改
#定义一个初始化权重的函数
def weight_variables(shape):
w=tf.Variable(tf.random.normal(shape=shape,mean=0.0,stddev=1.0))
return w
#定义一个初始化的权重函数
def weight_variables(Shape):
b=tf.Variable(tf.constant(0.0,shape=shape))
return b
def read_and_decode():
"读取验证码数据API return:image_batch,label_batch"
#1.构建文件队列
file_queue=tf.train.string_input_producer([FLAGS.captcha_dir])
#2.构建阅读器,读取文件内容,默认一个样本
reader=tf.TFRecordReader()
#读取内容
key,value=reader.read(file_queue)
#tfrecords格式 example,需要解析
#存进去什么类型,出来什么类型 string
features=tf.parse_single_example(value,feature={
"image":tf.train.Feature([],tf.string),
"label":tf.train.Feature([],tf.string),
})
#解码内容,字符串内容
#解析图片的特征值,目标值
image=tf.decode_raw(features["images"],tf.unit8)
label=tf.decode_raw(features["label"],tf.unit8)
#改变形状
image_reshape=tf.reshape(image,[20,80,3])
label_reshape=tf.reshape(label,[4])
print(image_reshape,label_reshape)
#进行批处理,每批次读取的样本数
image_batch,label_batch=tf.train.batch([image_reshape,label_reshape],batch_size=FLAGS.batch_size,num_threads=1,capacity=FLAGS.batch_size)
print(image_batch,label_batch)
return image_batch,label_batch
def fc_model(image):
with tf.Variable_scope("model"):
#将图片数据形状转换成2维
image_reshape=tf.reshape(image,[-1,20*80*3])#-1写成100也可以
#1.随机初始化权重偏置
#matrix [100,20*80*3] *[20*80*3,4*26]+[104]=[100,104]
weights=weight_variables([20*80*3,4*26])
bias=bias_variable([4*26])
#进行全连接层计算[100,4*26] 要求数据是float类型
y_predict=tf.matmul(tf.cast(image_reshape,float32),weights)+bias
return y_predict
def predict_to_onehot(label):
label_onehot=tf.one_hot(label,depth=FLAGS.letter_num,on_value=1.0,axis=2)
print(label_onehot)
return label_onehot
def captcharec():
#1.读取验证码的数据文件
read_and_decode()
#2.用过特征建立模型,得出结果
#1层全连接神经网络
#matrix [100,20*80*] *[20*80*3,4*26]+[104]=[100,104]
#把数据格式改成2维的
y_predict=fc_model(image_batch)
print(y_predict)
#3. 要进行交叉熵损失计算 要先转换成one_hot编码
y_true=predict_to_onehot(label_batch)
#4.softmax计算 交叉熵损失计算 [100,4,26]--->[100,4*26]
with tf.variable_scope("soft_cross"):
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=tf.reshape(y_true,[FLAGS.batch_size,FLAGS.label_num*FLAGS.letter_num]
logits=y_predict))
#5.梯度下降优化损失
with tf.variable_scope("optimizer"): #老师说是所有的都放到一个api里面了统一一下
train_op=tf.train.GradientDescentOptimizer(0.01).minimize(loss)
#6.求一个准确率
with tf.variable_scope("acc"):
#比较预测值和目标值 第二个位置的目最大值 [[][]]两层 [100,4*26]--->[100,4,26]
equal_list=tf.equal(tf.argmax(y_true,2),tf.argmax(
tf.reshape(y_predict,[FLAGS_batch_size,FLAGS.label_num,FLAGS.letter_num],2))
#euqal_list None个样本 [1,0,1,0,0,1....]
accuracy=tf.reduce_mean(tf.cast(equal_list,tf.float32))
#定义一个初始化变量的op
init_op=tf.global_variables_initializer()
#开启会话训练
with tf.Session() as sess:
sess.run(init_op)
#定义线程协调器开启线程(有数据在文件当中读取提供给模型)
coord=tf.train.Coordinator()
#开启线程去运行读取文件操作
threads=tf.train.start_queue_runners(sess,coord=coord)
#训练识别程序
for i in range(5000):
sess.run(train_op)
print("第%d批次的准确率为:%f" %(i,accuracy.eval()))
#回收线程 ,套路写法
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
captcharec()
