简介:
接上一篇中文验证码的分割,这一篇继续说一下中文验证码的识别,关于中文验证码的分割详细请看上一篇,但这里也会做一下说明。尝试识别的验证码样式如下:

思路:
中文的数量是英文数字不可比拟的,就拿中文汉字的数量是英文字母不可比的,就拿本文所使用的常用3500个汉字来说,就上图四个汉字验证码来说,如果不对验证码分割直接使用神经网络进行端到端识别的话,学习成本会非常大,其次,网络输出层需要3500的4次方个类别,这样的计算量是相当庞大的。
所以本文的思路是学习训练两个神经网络模型。
第一个模型为全卷积神经网络,作用是检测验证码中汉字的位置,方便将汉字分割为20x20像素的图片。网络总共为7层(画图偷懒了,只画了5层),前三层为卷积➕ 池化层,后三层为图片resize放大➕ 卷积层,输入和输出如下图所示,数据是本人生成的,代码以及网络详细结构在上一篇中。
第二个模型为普通卷积神经分类网络,作用是对分割出的汉字进行识别。网络前半部分为卷积+池化层,后半部分为全连接层,输出为softmax层,输出为对3500个常用字的预测。

当两个模型训练完之后,程序将按照如下如下流程图对中文验证码进行汉字识别(也就是本文最后一段代码的流程图):

数据的生成:
第一个模型数据的生成请看上一篇文章。
第二个模型数据的生成:
1、首先从3500.txt文件中读取最常用的3500个汉字,随机挑选出四个汉字,并记录每个汉字在这3500个汉字的位置作为标签。
2、将挑选出的汉字画在一张30x100像素的图片上,汉字位置在一定范围内存在随机性,并随机画上一些噪音杂线干扰识别。
from PIL import Image,ImageFont,ImageDraw
import random
import os
import numpy as np
import cv2
class ImageChar():
"""
1、读取3500.txt 这是最常用3500汉字 并随机挑选出汉字
2、在./fonts/ 文件夹下存放 字体格式 随机挑选格式 然后依据格式随机生成汉字
3、随机画指定数目的干扰线
4、环境:Mac python3.5
"""
def __init__(self, color=(0,0,0),size=(100,30),
fontlist=['./fonts/'+i for i in os.listdir('./fonts/') if not i =='.DS_Store'],
fontsize=20,
num_word=4):#生成多少个字的验证码(图片宽度会随之增加)
self.num_word=num_word
self.color=color
self.fontlist=fontlist
if self.num_word==4:
self.size=size
else:
self.size=((self.fontsize+5)*self.num_word,40)
#随机挑选一个字体 randint(0,2)会取0,1,2 所以减去 1
self.fontpath=self.fontlist[random.randint(0,len(self.fontlist)-1)]
self.fontsize=fontsize
self.chinese=open('3500.txt','r').read()
self.font=ImageFont.truetype(self.fontpath, self.fontsize)
#随机生成四个汉字的字符串
def rand_chinese(self):
chinese_str=''
chinese_num=[]
for i in range(self.num_word):
temp=random.randint(0,3499)
chinese_str=chinese_str+self.chinese[temp]
chinese_num.append(temp)
return chinese_str,chinese_num
#随机生成杂线的坐标
def rand_line_points(self,mode=0):
width,height=self.size
if mode==0:
return (random.randint(0, width), random.randint(0, height))
elif mode==1:
return (random.randint(0,6),random.randint(0, height))
elif mode==2:
return (random.randint(width-6,width),random.randint(0, height))
#随机生成一张 输入 图片 和 一张 标签图片(模型一:检测汉字区域)
def rand_draw(self,num_lines=4):
width,height=self.size
gap=5
start=0
#第一张,带噪音的验证码
self.img1 = Image.new('RGB',self.size,(255,255,255))
self.draw1=ImageDraw.Draw(self.img1)
self.img2 = Image.new('RGB',self.size,(255,255,255))
self.draw2=ImageDraw.Draw(self.img2)
#把线画上去
for i in range(num_lines//2):
self.draw1.line([self.rand_line_points(),self.rand_line_points()],(0,0,0))
for i in range(num_lines//2):
self.draw1.line([self.rand_line_points(1),self.rand_line_points(2)],(0,0,0))
i=0
words,chinese_num=self.rand_chinese()
# img1_crops=[]
for word in words:
x=start+(self.fontsize+gap)*i+random.randint(0,gap)
y=random.randint(0,height-self.fontsize-gap)
i+=1
self.draw1.text((x,y),word,fill=(0,0,0),font=self.font)
# img1_crop=self.img1.crop((x,y+4,x+20,y+24))
# img1_crops.append(img1_crop)
self.draw2.rectangle([(x,y+4),(x+20,y+24)],fill=(0,0,0))
return self.img1,self.img2
#随机生成一张图片 和对应的汉字标签(模型二使用)
def rand_img_label(self,num_lines=4):
width,height=self.size
gap=5
start=0
#第一张,带噪音的验证码
self.img1 = Image.new('RGB',self.size,(255,255,255))
self.draw1=ImageDraw.Draw(self.img1)
#把线画上去
for i in range(num_lines//2):
self.draw1.line([self.rand_line_points(),self.rand_line_points()],(0,0,0))
for i in range(num_lines//2):
self.draw1.line([self.rand_line_points(1),self.rand_line_points(2)],(0,0,0))
i=0
words,chinese_num=self.rand_chinese()
#将汉字画上去
for word in words:
x=start+(self.fontsize+gap)*i+random.randint(0,gap)
y=random.randint(0,height-self.fontsize-gap)
i+=1
self.draw1.text((x,y),word,fill=(0,0,0),font=self.font)
#生成标签
# label_list=[0]*4*3500
# for j in chinese_num:
# label_list[j]=1
return self.img1,chinese_num#生成数据的时候用3、通过第一个模型已经检测出汉字的位置,很容易通过opencv的查找矩形的方式,找到汉字位置,从验证码中分割出汉字
4、将汉字位置的数字转化为one-hot矩阵,作为标签数据。
import cv2
import numpy as np
import tensorflow as tf
# import pre_net
import cut_words
#img=cv2.resize(img,(20,20),cv2.INTER_NEAREST)
#输入一张图片返回的是四张图片的列表
def single_crop(data,img_pre):
cv2.imwrite('2_predict.jpg',img_pre)
img=cv2.imread('2_predict.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
pointers=cut_words.get_pointers(img)
croped_imgs=[]
for i in pointers:
itemp=data[i[0][1]:i[1][1],i[0][0]:i[1][0]]
itemp=cv2.resize(itemp,(20,20),cv2.INTER_NEAREST)#resize 会使图片二值化失效,所以再次二值化
ret,itemp = cv2.threshold(itemp,127,255,cv2.THRESH_BINARY)
itemp=itemp/255
itemp=itemp.reshape(400,)
itemp=itemp.tolist()
croped_imgs.append(itemp)
return croped_imgs
def main():
#加载模型
model_saver=tf.train.import_meta_graph("./model/mymodel.ckpt.meta")
sess=tf.Session()
model_saver.restore(sess,'model/mymodel.ckpt')
y_conv=tf.get_collection('pre_img')[0]
graph = tf.get_default_graph()
x=graph.get_operation_by_name('in_image').outputs[0]
if_is_training=graph.get_operation_by_name('if_is_training').outputs[0]
#加载输入数据
imgs=np.load("imgs.npy")
# rows,cols=imgs.shape
rows=100000
croped_imgs=[]
for row in range(800,rows//100):
if row%50==0:
print(row)
img=imgs[row*100:(row+1)*100,:]
data=tf.reshape(img, shape=[-1,3000])
rel=sess.run(y_conv,feed_dict={x:sess.run(data),if_is_training:False})
# print(rel.shape)
rows_rel,cols_rel=rel.shape
for row_rel in range(rows_rel):
before_crop=rel[row_rel,:].reshape(30,100)
before_crop=np.around(before_crop)
before_crop=before_crop*255
temp_croped=single_crop(img[row_rel,:].reshape(30,100)*255,before_crop)
for i in temp_croped:
croped_imgs.append(i)
np.save('in_ims.npy',np.array(croped_imgs))cut_word.py
import numpy as np
import cv2
import pre_net
#注意,传入的是二维的灰度图,返回四个汉字坐标
def get_pointers(img_bin):
#腐蚀掉边缘缩小黑框,方便findCoutour函数剪裁
kernel = np.ones((5,5),np.uint8)
img_bin = cv2.erode(img_bin,kernel,iterations = 1)
#因为腐蚀掉了,所以剪裁的时候要扩展两个像素
extent=2
#发现黑框边框
img_bin, contours,h= cv2.findContours(img_bin,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
# print(len(contours))
pointers=[]
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
# print("面积:",(w+2*extent)*(h+2*extent)," w:",w+extent*2)
if (w+extent*2)>35:#有些汉字两个字连在一起了,所以要对中间剪裁
if x- extent<0:#往左扩展了两个像素,最左边的字的横坐标有可能小于零无法剪裁,
pointers.append([(0,y- extent),((x-extent)+(w+extent)//2,y+h+ extent)])
else:
pointers.append([(x- extent,y- extent),((x-extent)+(w+extent)//2,y+h+ extent)])
pointers.append([((x-extent)+(w+extent)//2,y- extent),(x+w+ extent,y+h+ extent)])
else:
if x -extent<0:
pointers.append([(0,y- extent),(x+w+ extent,y+h+ extent)])
else:
pointers.append([(x- extent,y- extent),(x+w+ extent,y+h+ extent)])
pointers=sort_point(pointers)
re_pointers=[]
#丢弃面积小于200的区域
for i in pointers:
i_x=i[1][0]-i[0][0]
i_y=i[1][1]-i[0][1]
if i_x*i_y>200:
re_pointers.append(i)
#图片剪裁失败率为16万张错13张,就留下了作为躁点数据了
while len(re_pointers)<4:
re_pointers.append(re_pointers[0])
return re_pointers
#对返回的坐标进行按横坐标大小排序
def sort_point(pointers):
for i in range(len(pointers)-1):
for j in range(i+1,len(pointers)):
if pointers[i][0][0]>pointers[j][0][0]:
temp=pointers[i]
pointers[i]=pointers[j]
pointers[j]=temp
return pointersget_pointer函数经过修修补补有些复杂,因为画一个流程图:
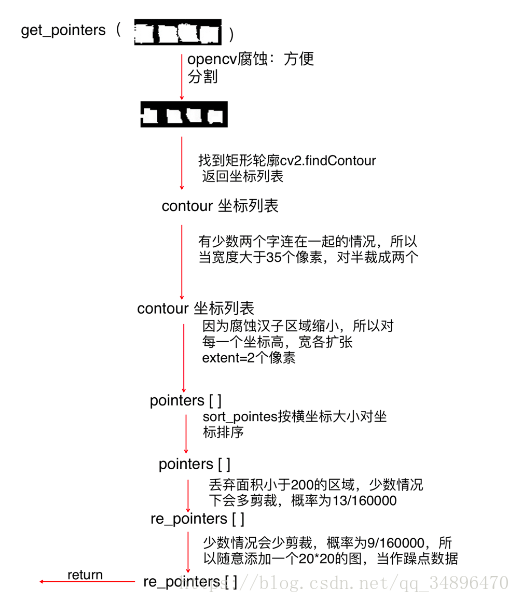
训练代码:
import tensorflow.contrib.slim as slim
import tensorflow as tf
import numpy as np
import random
import time
def cal_loss(y_pre,y_label):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y_pre))
# return -tf.reduce_sum(y_label*tf.log(y_pre))
# return tf.reduce_mean(tf.square(y_label - y_pre))
# return tf.reduce_mean(tf.pow(tf.subtract(y_pre,y_label),2))
def xavier_init(fan_in,fan_out,constant = 1):
low = -constant * np.sqrt(6.0/(fan_in+fan_out))
high = constant * np.sqrt(6.0/(fan_in+fan_out))
return tf.random_uniform((fan_in,fan_out),minval = low,maxval = high,dtype = tf.float32)
def network(in_image,if_is_training):
batch_norm_params={
'is_training':if_is_training,
'zero_debias_moving_mean':True,
'decay':0.99,
'epsilon':0.001,
'scale':True,
'updates_collections':None
}
with slim.arg_scope([slim.conv2d],activation_fn=tf.nn.relu,
padding='SAME',
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
weights_regularizer=slim.l2_regularizer(0.0005)):
out_1=32
out_2=64
out_3=128
net=slim.conv2d(in_image,num_outputs=out_2,kernel_size=[5,5],stride=1,scope='conv1')
print('1_con:\t',net.get_shape())
net=slim.max_pool2d(net,kernel_size=[2,2],stride=2,scope='pool1')
print('1_pool:\t',net.get_shape())
net=slim.conv2d(net,num_outputs=out_2,kernel_size=[5,5],stride=1,scope='conv2')
print('2_con:\t',net.get_shape())
net=slim.max_pool2d(net,kernel_size=[2,2],stride=2,scope='pool2')
print('2_pool:\t',net.get_shape())
net=slim.conv2d(net,num_outputs=out_3,kernel_size=[3,3],stride=1,scope='conv3_1')
net=slim.conv2d(net,num_outputs=out_3,kernel_size=[3,3],stride=1,scope='conv3_2')
print('3_con:\t',net.get_shape())
net=slim.max_pool2d(net,kernel_size=[2,2],stride=2,scope='pool3')
print('3_pool:\t',net.get_shape())
# net = tf.reshape(net,shape=[-1,2*2*128])
net=slim.flatten(net,scope='flatten')
with slim.arg_scope([slim.fully_connected],
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
net=slim.fully_connected(net,3000,
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
scope='fc1')
print('fc1:\t',net.get_shape())
net=slim.fully_connected(net,6000,
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
scope='fc2')
print('fc2:\t',net.get_shape())
net=slim.fully_connected(net,3500,
activation_fn=None,
normalizer_fn=None,
# weights_initializer=slim.xavier_initializer(),
# biases_initializer=tf.zeros_initializer(),
scope='fc3')
print('soft:\t',net.get_shape())
return net
def main():
in_image= tf.placeholder(dtype=tf.float32, shape=[None,400], name='in_image')
out_image=tf.placeholder(dtype=tf.float32, shape=[None,3500], name='out_image')
# 和 batch normalization一起使用,在训练时为True,预测时False
if_is_training=tf.placeholder(dtype=tf.bool,name='if_is_training')
x_input = tf.reshape(in_image, shape=[-1,20,20,1], name='x_input')
pre_image=network(x_input,if_is_training)
# l2_loss = tf.add_n(tf.losses.get_regularization_losses())
cost=cal_loss(pre_image,out_image)
corr=tf.equal(tf.argmax(pre_image,1),tf.argmax(out_image,1))
loss=tf.reduce_mean(tf.cast(corr,"float"))
# 和 batch normalization 一起使用
update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
# train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
train_op = tf.train.MomentumOptimizer(learning_rate=0.01,momentum=0.9,use_nesterov=True).minimize(cost)
model_saver=tf.train.Saver()
tf.add_to_collection('pre_img',pre_image)
x_image=np.load('in_imgs.npy')
y_image=np.load('soft_labels.npy')
x_image_1=np.load('in_imgs_1.npy')
y_image_1=np.load('soft_labels_1.npy')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
while True:
#输入训练次数,方便控制和继续训练
command=input('input:\t')
if command=='qq':
break
for i in range(int(command)):
# begin=time.time()
bt=random.randint(0,159899)
way=random.randint(0,1)
if way==0:
min_x_image=x_image[bt:(bt+100),:]
min_y_image=y_image[bt:(bt+100),:]
else:
min_x_image=x_image_1[bt:(bt+100),:]
min_y_image=y_image_1[bt:(bt+100),:]
sess.run(train_op,feed_dict={in_image:min_x_image,out_image:min_y_image,if_is_training:True})
# end=time.time()
# print('count: ',i,' times:',end - begin)
if i%200==0:
print('\n','count:',i)
loss_op=sess.run(cost,feed_dict={in_image:min_x_image,out_image:min_y_image,if_is_training:True})
print(' loss:\t',loss_op,'\n')
model_saver.save(sess,'./model_step2/mymodel.ckpt')
# np.save('loss.npy',np.array(all_loss))
if __name__=='__main__':
main()准确率:
1、第一个模型分割出错率为13/160000 。
2、第二个模型识别出错的概率为201/80000 。
3、将两个模型结合在一起的代码进行中文验证码识别的错误率几次测试分别为11/1000,37/3000,58/6000。识别准确率基本在98%以上。
加载两个模型进行识别的完整代码如下:
import tensorflow as tf
import numpy as np
import cv2
import sys
#注意,传入的是二维的灰度图,返回四个汉字坐标
def get_pointers(img_bin):
#腐蚀掉边缘缩小黑框,方便findCoutour函数剪裁
kernel = np.ones((5,5),np.uint8)
img_bin = cv2.erode(img_bin,kernel,iterations = 1)
#因为腐蚀掉了,所以剪裁的时候要扩展两个像素
extent=2
#发现黑框边框
img_bin, contours,h= cv2.findContours(img_bin,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
# print(len(contours))
pointers=[]
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt)
# print("面积:",(w+2*extent)*(h+2*extent)," w:",w+extent*2)
if (w+extent*2)>35:#有些汉字两个字连在一起了,所以要对中间剪裁
if x- extent<0:#往左扩展了两个像素,最左边的字的横坐标有可能小于零无法剪裁,
pointers.append([(0,y- extent),((x-extent)+(w+extent)//2,y+h+ extent)])
else:
pointers.append([(x- extent,y- extent),((x-extent)+(w+extent)//2,y+h+ extent)])
pointers.append([((x-extent)+(w+extent)//2,y- extent),(x+w+ extent,y+h+ extent)])
else:
if x -extent<0:
pointers.append([(0,y- extent),(x+w+ extent,y+h+ extent)])
else:
pointers.append([(x- extent,y- extent),(x+w+ extent,y+h+ extent)])
pointers=sort_point(pointers)
re_pointers=[]
#丢弃面积小于200的区域
for i in pointers:
i_x=i[1][0]-i[0][0]
i_y=i[1][1]-i[0][1]
if i_x*i_y>200:
re_pointers.append(i)
#图片剪裁失败率为16万张错13张,就留下了作为躁点数据了
while len(re_pointers)<4:
re_pointers.append(re_pointers[0])
return re_pointers
#对返回的坐标进行按横坐标大小排序
def sort_point(pointers):
for i in range(len(pointers)-1):
for j in range(i+1,len(pointers)):
if pointers[i][0][0]>pointers[j][0][0]:
temp=pointers[i]
pointers[i]=pointers[j]
pointers[j]=temp
return pointers
#输入一张图片返回的是四张图片(0~1)的列表,data(0~255)是被剪裁的图片,img_pre(0~255)是中文区域图
def singleCrop(data,img_pre):
cv2.imwrite('z_1FirstStepImg.jpg',img_pre)
img=cv2.imread('z_1FirstStepImg.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
pointers=get_pointers(img)
croped_imgs=[]
for i in pointers:
itemp=data[i[0][1]:i[1][1],i[0][0]:i[1][0]]
itemp=cv2.resize(itemp,(20,20),cv2.INTER_NEAREST)
#resize 会使图片二值化失效,所以再次二值化
ret,itemp = cv2.threshold(itemp,127,255,cv2.THRESH_BINARY)
itemp=itemp/255
itemp=itemp.reshape(400,)
itemp=itemp.tolist()
croped_imgs.append(itemp)
#返回的是0~1的图片,类型List
return croped_imgs
def recognitionFirstStep(data):
#加载模型一
graph_1=tf.Graph()
sess_1=tf.Session(graph=graph_1)
with graph_1.as_default():
model_saver_1=tf.train.import_meta_graph("./model_step1/mymodel.ckpt.meta")
model_saver_1.restore(sess_1,'./model_step1/mymodel.ckpt')
y_conv=tf.get_collection('pre_img')[0]
x=graph_1.get_operation_by_name('in_image').outputs[0]
if_is_training=graph_1.get_operation_by_name('if_is_training').outputs[0]
data=tf.reshape(data, shape=[-1,3000])
rel=sess_1.run(y_conv,feed_dict={x:sess_1.run(data),if_is_training:False})
rel=rel.reshape(30,100)
rel=np.around(rel)
return rel*255#返回一张找到字体区域的二值图
#识别每一个切割出来的中文字,输入依然是(0,1) 的灰度图
def recognitionSecondStep(imgCutList):
w3500=open('3500.txt','r').read()
graph_2=tf.Graph()
sess_2=tf.Session(graph=graph_2)
with graph_2.as_default():
model_saver_2=tf.train.import_meta_graph("./model_step2/mymodel.ckpt.meta")
model_saver_2.restore(sess_2,'./model_step2/mymodel.ckpt')
y_conv=tf.get_collection('pre_img')[0]
x=graph_2.get_operation_by_name('in_image').outputs[0]
if_is_training=graph_2.get_operation_by_name('if_is_training').outputs[0]
chineseCode=""
for imList in imgCutList:
data=np.array(imList)
data=tf.reshape(data, shape=[-1,400])
rel=sess_2.run(y_conv,feed_dict={x:sess_2.run(data),if_is_training:False})
num=np.argmax(rel)
chineseCode+=w3500[num]
# print(w[num])
return chineseCode
def readImage(filename):
img=cv2.imread(filename)
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,data = cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV)
data=data/255
return data
#输入(0~1)的二位灰度shape=(30,100)的图
def chineseCodeRecognition(filename):
data=readImage(filename)
cv2.imwrite('z_0InputImage.jpg',data*255)
firstStepImg=recognitionFirstStep(data)#return (0~255)
imgCutList=singleCrop(data*255,firstStepImg)#return (0~1)
chineseCode=recognitionSecondStep(imgCutList)
return chineseCode
if __name__=='__main__':
chineseCode=chineseCodeRecognition(sys.argv[1])
print(chineseCode)结尾:
因为工作和出差的耽误,这个下篇隔了好久才写。整个程序识别率基本在98%以上。