Scrapy python开发的一个快速抓取屏幕和web的爬虫框架。关于Scrapy详情请找度娘。
在上一篇文章已经交代了scrapy的安装,这里我们就简单的创建我们的第一个爬虫吧!
1、在我们合适的目录下运行scrapy的创建命令:scrapy startproject obb
obb是我们的爬虫项目名
例如:我在E盘创建我的scrapy,在cmd命令下进入E盘输入创建命令,如下:
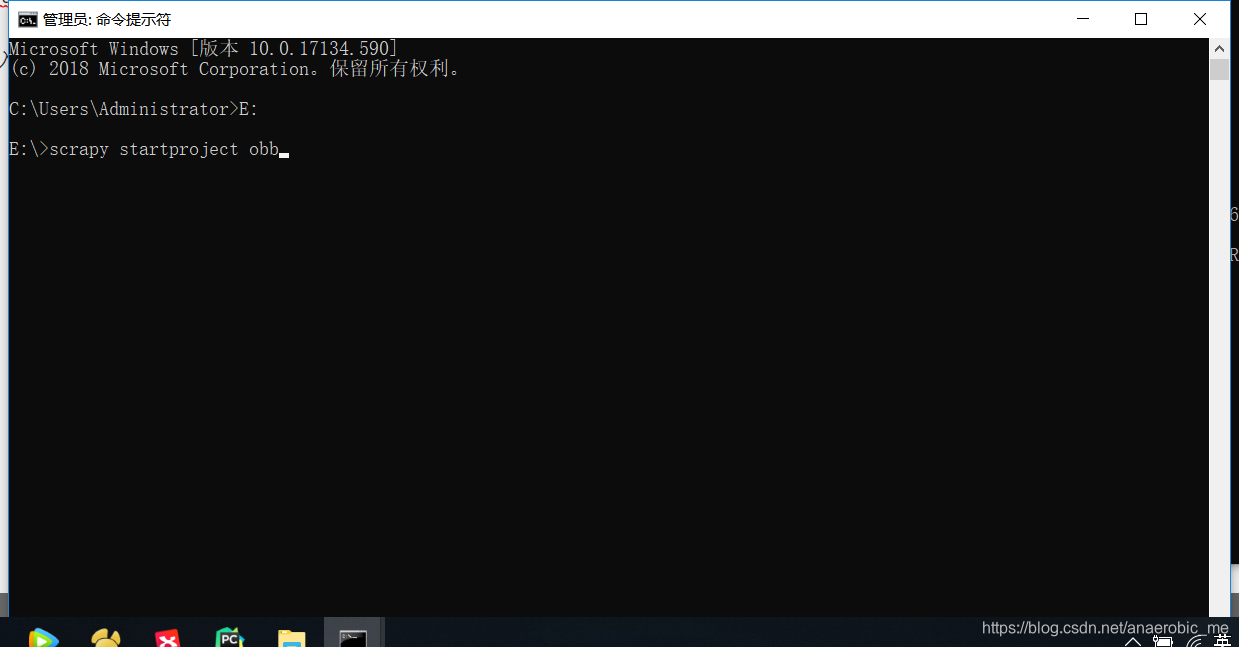
命令执行后将在E盘创建一个obb文件夹,进入文件夹将出现连个文件,进入同项目名相同的文件夹则会有scrapy的文件,如下:
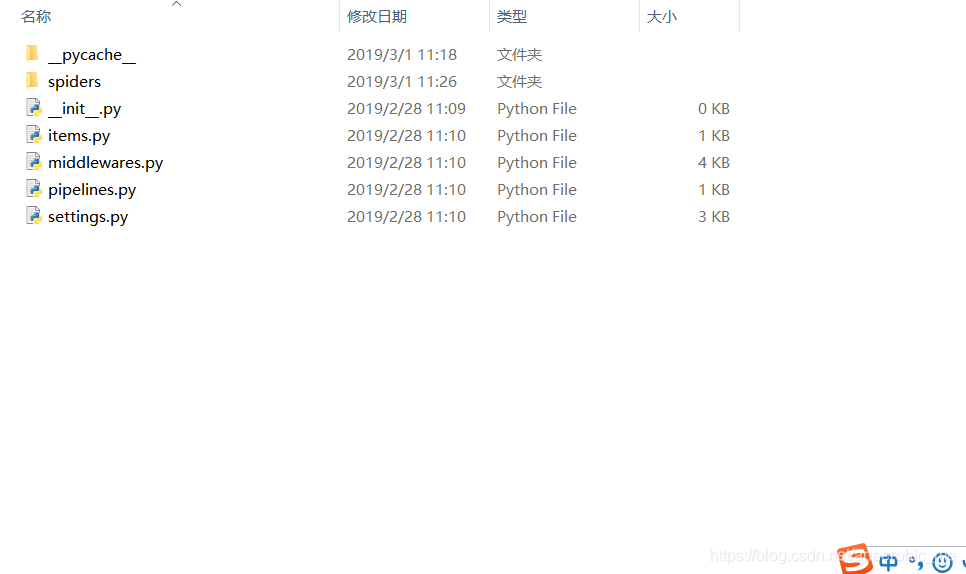
这里包含scrapy的一些基本功能配置文件。
spiders文件夹下是存储我们所要编写的爬虫文件。我们在此创建我们的第一个爬虫文件。
小弟我创建了第一个爬虫叫:taoche.py
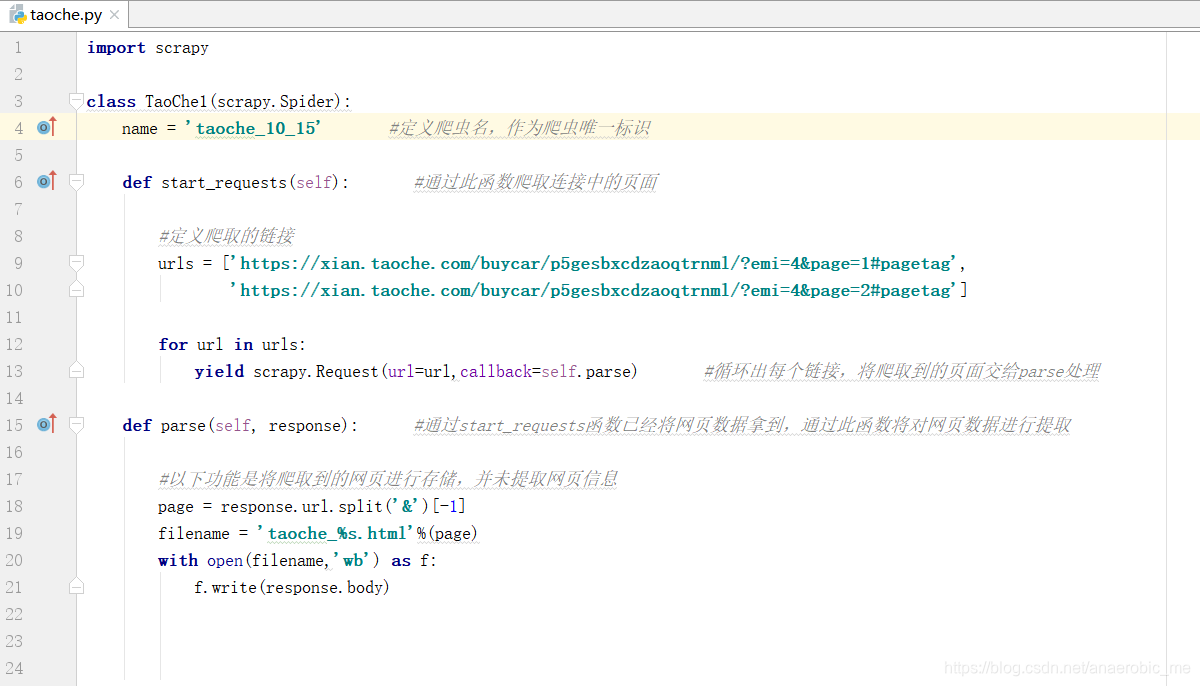
这是我的基本代码。每一行的功能作用都有注释。parse函数现在只是将爬取到的网页进行了基本的存储处理,之后会将其中的所需内容进行抓取,进行存储处理。
这就是我们的第一个简单爬虫。能做到这里我们既是开启了scrapy爬虫之路。