目录
- scrapy简介
- Scrapy架构
- 常用命令
- Scrapy运作流程
- 反反爬虫策略
- 错误状态码处理
- 代码示例
- 参考文献
Scrapy简介
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy架构
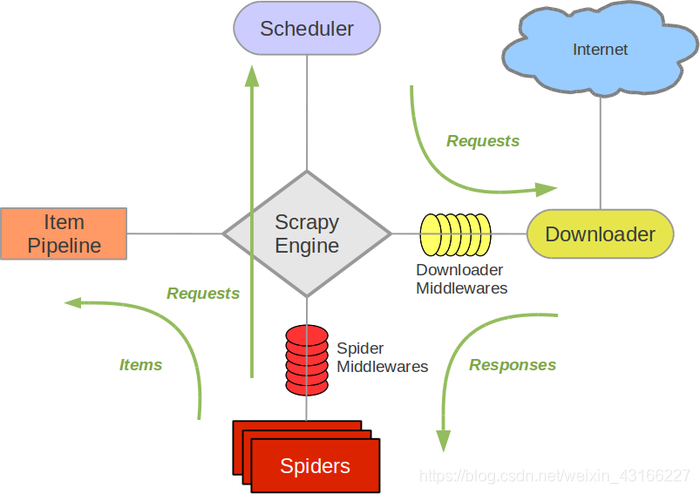
- Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 - Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载ScrapyEngine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给ScrapyEngine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
cmd常用命令
-
windows安装scrapy:
pip install --upgrade pip #升级版本 pip install scrapy -
创建项目:scrapy startproject botname
scrapy.cfg: 项目的配置文件 projectname/: 该项目的python模块。之后您将在此加入代码。 projectname/items.py: 项目中的item文件. projectname/pipelines.py: 项目中的pipelines文件. projectname/settings.py: 项目的设置文件. projectname/spiders/: 放置spider代码的目录. -
生成爬虫文件:scrapy genspider spidername 域名
-
调式命令:scrapy shell 网址
-
启动爬虫,观察日志:scrapy crawl spidername
scrapy crawl douban -s LOG_LEVEL=INFO 或 scrapy crawl douban -s LOG_LEVEL=DEBUG
Scrapy运作流程
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该Spider请求第一个要爬取的URL(s)
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载器中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response))发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送 给Spider处理。
- Spider处理Response并返回爬取到的item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的item给item Pipeline,将(Spider返回的)Request给调度器
- (从第二步)重复直到调度器中没有更多地Request,引擎关闭该网站。
反反爬虫策略
- 设置延迟下载
download_delay参数,在settings.py文件中设置 - 禁止Cookie
在settings.py中设置COOKIES_ENABLES=False。也就是不启用cookies middleware,不想web server发送cookies。 - 使用user agent池
修改settings.py配置USER_AGENTS和PROXIES
所谓的user agent,是指包含浏览器信息、操作系统信息等的一个字符串,也称之为一种特殊的网络协议。服务器通过它判断当前访问对象是浏览器、邮件客户端还是网络爬虫。USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", ] - 使用IP池
web server应对爬虫的策略之一就是直接将你的IP或者是整个IP段都封掉禁止访问,这时候,当IP封掉后,转换 到其他的IP继续访问即可。
添加代理IP设置PROXIES
代理IP可以网上搜索一下,上面的代理IP获取自:http://www.xici.net.co/。PROXIES = [ {'ip_port': '111.11.228.75:80', 'user_pass': ''}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] - 如果可行,使用 Google cache 来爬取数据,而不是直接访问站点。
- 使用高度分布式的下载器(downloader)来绕过禁止(ban),您就只需要专注分析处理页面。这样的例子有: Crawlera
- 增加并发 CONCURRENT_REQUESTS = 100
- 禁止重试:RETRY_ENABLED = False
- 禁止重定向:REDIRECT_ENABLED = False
- 启用 “Ajax Crawlable Pages” 爬取:AJAXCRAWL_ENABLED = True
- 减小下载超时:DOWNLOAD_TIMEOUT = 15
- 分布式爬取
鉴于篇幅,在以后的章节中会就分布式爬取做详细研究和介绍。
错误状态码处理
-
解决URL被重定向无法抓取到数据问题301. 302
什么是状态码301,302 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将 来任何对此资源的引用都应该使用本响应返回的若干个URI之一。
解决(一)
1.在Request中将scrapy的dont_filter=True,因为scrapy是默认过滤掉重复的请求URL,添加上参数之后即使被重定向了也能请求到正常的数据了 # example Request(url, callback=self.next_parse, dont_filter=True)
解决(二) 在scrapy框架中的 settings.py文件里添加HTTPERROR_ALLOWED_CODES =[301,302]解决(三) 使用requests模块遇到301和302问题时 def website():
'url' headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, sdch, br', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Host': 'pan.baidu.com', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} url = 'https://www.baidu.com/' html = requests.get(url, headers=headers, allow_redirects=False) return html.headers['Location']allow_redirects=False的意义为拒绝默认的301/302重定向从而可以通过html.headers[‘Location’]拿到重定向的 URL。
解决(四):def start_requests(self): for i in self.start_urls: yield Request(i, meta={ 'dont_redirect': True, 'handle_httpstatus_list': [302] }, callback=self.parse) -
403错误状态码的解决方法
在setting.py文件中增加USER_AGENT配置。
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
-
404错误状态码处理
解决方法(一):
https://stackoverflow.com/questions/16909106/scrapyin-a-request-fails-eg-404-500-how-to-ask-for-another-alternative-requefrom scrapy.http import Request from scrapy.spider import BaseSpider class MySpider(BaseSpider): handle_httpstatus_list = [404, 500] # name = "my_crawler" start_urls = ["http://github.com/illegal_username"] def parse(self, response): if response.status in self.handle_httpstatus_list: return Request(url="https://github.com/kennethreitz/", callback=self.after_404) def after_404(self, response): print response.url # parse the page and extract items解决方法(二):
https://stackoverflow.com/questions/13724730/how-to-get-the-scrapy-failure-urlsfrom scrapy.spider import BaseSpider from scrapy.xlib.pydispatch import dispatcher from scrapy import signals class MySpider(BaseSpider): handle_httpstatus_list = [404] name = "myspider" allowed_domains = ["example.com"] start_urls = [ 'http://www.example.com/thisurlexists.html', 'http://www.example.com/thisurldoesnotexist.html', 'http://www.example.com/neitherdoesthisone.html' ] def __init__(self, category=None): self.failed_urls = [] def parse(self, response): if response.status == 404: self.crawler.stats.inc_value('failed_url_count') self.failed_urls.append(response.url) def handle_spider_closed(spider, reason): self.crawler.stats.set_value('failed_urls', ','.join(spider.failed_urls)) def process_exception(self, response, exception, spider): ex_class = "%s.%s" % (exception.__class__.__module__, exception.__class__.__name__) self.crawler.stats.inc_value('downloader/exception_count', spider=spider) self.crawler.stats.inc_value('downloader/exception_type_count/%s' % ex_class, spider=spider) dispatcher.connect(handle_spider_closed, signals.spider_closed) -
HTTP状态码未经任何处理(HTTP status code is not handled or not allowed)
在项目设置setting.py增加HTTPERROR_ALLOWED_CODES = [NNN]
代码示例
pipelines.py文件中代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
import pymongo
from scrapy.conf import settings
from vuls360.items import Vuls360Item
class Vuls360Pipeline(object):
'''
def __init__(self):
self.file = codecs.open('vul.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item
'''
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME'] # 数据库名
client = pymongo.MongoClient(host=host, port=port)
tdb = client[dbname]
self.port = tdb[settings['MONGODB_DOCNAME']] # 表名
def process_item(self, item, spider):
vul_info = dict(item)
self.port.insert(vul_info)
return item
settings.py文件中代码
# -*- coding: utf-8 -*-
BOT_NAME = 'vuls360'
SPIDER_MODULES = ['vuls360.spiders']
NEWSPIDER_MODULE = 'vuls360.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'vuls360 (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'vuls360.middlewares.Vuls360SpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'vuls360.middlewares.RandomUserAgent': 543,
}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'vuls360.pipelines.Vuls360Pipeline': 30,
}
#save to mongdodb
# MONGO_URI = 'mongodb://127.0.0.1:27017'
MONGODB_HOST = '127.0.0.1:'
MONGODB_PORT = 27017
MONGODB_DBNAME = 'vuls360'
MONGODB_DOCNAME = 'vuls360_info'
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
from flightHistory.resources import Aircragt
class FlightSpider(scrapy.Spider):
name='flightspider'
start_urls = []
for plane in Aircragt:
start_urls.append('https://******/'+str(plane))
def parse(self, response):
subSelector=response.xpath('//div[@id="cnt-aircraft-info"]')
oneSelector=subSelector.xpath('./div[@class="col-xs-5 n-p"]').xpath('./div[@class="row h-30 p-l-20 p-t-5"]')
towSelector=subSelector.xpath('./div[@class="col-xs-7"]').xpath('./div[@class="row"]').xpath('./div[@class="col-sm-5 n-p"]').xpath('./div[@class="row h-30 p-l-20 p-t-5"]')
threeSelector=subSelector.xpath('./div[@class="col-xs-7"]').xpath('./div[@class="row"]').xpath('./div[@class="col-sm-7 n-p"]').xpath('./div[@class="row h-30 p-l-20 p-t-5"]')
item = FlighthistoryItem()
item['AC_AIRCRAFT']=response.url.split('/')[-1].strip().lower()
item['AIRCRAFT'] = oneSelector[0].xpath('span/text()').extract()[0].strip()
if len(oneSelector[1].xpath('span/*'))==0:
item['AIRLINE'] =oneSelector[1].xpath('span/text()').extract()[0].strip()
else:
item['AIRLINE'] =oneSelector[1].xpath('span/a/text()').extract()[0].strip()
item['OPERATOR'] = oneSelector[2].xpath('span/text()').extract()[0].strip()
item['TYPECODE'] = towSelector[0].xpath('span/text()').extract()[0].strip()
item['TCode'] =towSelector[1].xpath('span/text()').extract()[0].strip()
item['UCode'] =towSelector[2].xpath('span/text()').extract()[0].strip()
item['MODES']=threeSelector[0].xpath('span/text()').extract()[0].strip()
return item
MongoDB使用
#删除数据库操作
> use vuls360
switched to db vuls360
> db.dropDatabase()
{ "dropped" : "vuls360", "ok" : 1 }
#查看爬虫数据
> use vuls360
switched to db vuls360
> show collections
system.indexes
vuls360_info
> db.vuls360_info.find()
Scrapy默认情况下深度优先顺序,也可以设置广度优先
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
参考文献
反反爬虫
http://www.tuicool.com/articles/VRfQR3U
https://www.jianshu.com/p/ba1bba6670a6
http://www.cnblogs.com/wzjbg/p/6507581.html
Scrapy指南
http://www.runoob.com/w3cnote/scrapy-detail.html
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
http://www.cnblogs.com/cutd/p/6208861.html
http://wiki.jikexueyuan.com/project/scrapy
定义user-agent池&****Scrapy HTTP代理
http://www.2cto.com/os/201406/312688.html
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=scrapy agent&oq=scrapy%E6%89%A9%E5%B1%95&rsv_pq=fee1578b0000ca7a&rsv_t=6a10nCV%2Fwr3THCK7rFn%2FH8Pmru%2F%2FcsmS%2BBr8Y%2FeWNzi9dBSZjm5ZvNZOYqY&rqlang=cn&rsv_enter=1&rsv_sug3=9&rsv_sug1=6&rsv_sug7=100&rsv_sug2=0&inputT=5409&rsv_sug4=5722
https://github.com/jackgitgz/CnblogsSpider
Scrapy存储
http://blog.csdn.net/u012150179?viewmode=contents
xpath和selector选择器的资料
http://www.cnblogs.com/lonenysky/p/4649455.html
http://www.cnblogs.com/sufei-duoduo/p/5868027.html
xpath和lxml的相关资料
http://cuiqingcai.com/2621.html
其他
http://wenda.jikexueyuan.com/question/34376/
https://www.figotan.org/2016/08/10/pyspider-as-a-web-crawler-system/