总帖:CDH 6系列(CDH 6.0、CHD6.1等)安装和使用
1.电商用户画像环境搭建(SparkSql整合hive)
Hive 的执行任务是将 hql 语句转化为 MapReduce 来计算的,Hive 的整体解决方案很不错,但是从查询提交到结果返回需要相当长的时间,查询耗时太长。
这个主要原因就是由于Hive原生是基于MapReduce的,那么如果我们不生成MapReduceJob,而是生成 Spark Job,就可以充分利用 Spark 的快速执行能力来缩短 HiveHQL 的响应时间。
本项目采用 SparkSql 与 hive 进行整合,通过 SparkSql 读取 hive 中表的元数据,即使用select查询时,把 HiveHQL 底层采用 MapReduce 来处理任务,导致性能慢的特点,
改为更加强大的 Spark 引擎来进行相应的分析处理,快速的为用户打上标签构建用户画像。
在使用select时,会调用spark进行计算:
通过 SparkSql 读取 hive 中表的元数据,即使用select查询时,不生成MapReduceJob,而是生成 Spark Job,
就可以充分利用 Spark 的快速执行能力来缩短 HiveHQL 的响应时间
insert overwrite table 数据库名.表名 partition(分区字段名=分区字段值)
select
字段名1, 字段名2,
from_unixtime(unix_timestamp()) dw_date
from (select * from 数据库名.表名 where 分区字段名=分区字段值) a
join (select * from 数据库名.表名 where 分区字段名=分区字段值) b on a.字段名 = b.字段名;
----------------------------------------------------------------------------------------------------------------
1.环境准备
1.需要搭建一个zk集群,并启动zk集群。每台机器都启动zookeeper(启动zookeeper 都必须执行 时间同步命令:ntpdate ntp6.aliyun.com)
cd /root/zookeeper/bin/
zkServer.sh start
查看集群状态、主从信息:
1.cd /root/zookeeper/bin/
2../zkServer.sh status # 查看状态:一个leader,两个follower
3.“follower跟随者”的打印结果:
JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: follower
4.“leader领导者”的打印结果:
JMX enabled by default
Using config: /root/zookeeper/bin/../conf/zoo.cfg
Mode: leader
5.jps命令:QuorumPeerMain
2.搭建 hadoop 集群:脚本一键启动(推荐)
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有 Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
1.启动 hdfs 集群:
cd /root/hadoop/sbin
./start-dfs.sh
2.停止 hdfs 集群:
cd /root/hadoop/sbin
./stop-dfs.sh
3.搭建 hive 构建数据仓库
创建数据库 实际是在hdfs文件系统中 /user/hive/warehouse目录下 创建一个文件夹“数据库名.db”
1.连接 Hive:
cd /root/hive/bin
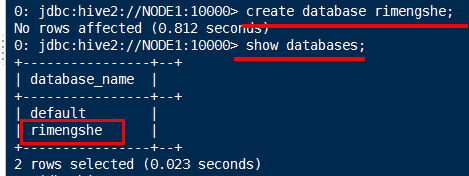
./hive 或 ./beeline -u jdbc:hive2://NODE1:10000 -n root
2.执行 show databases; 默认只有一个 数据库: default
3.创建新的数据库:create database [if not exists] 数据库名;
4.进入 http://192.168.25.100:50070 或 http://node1:50070
如果点击 user目录显示以下信息表示当前用户没有权限访问该目录,修改权限:hadoop fs -chmod -R 777 /user

5.进入 /user/hive/warehouse,即能看到所创建的 数据库(文件夹):

6.数据库相关操作
1.创建数据库:create database [if not exists] 数据库名;
2.显示所有数据库:show databases;
3.删除数据库:(drop database 数据库名)
drop database [if exists] 数据库名 [restrict|cascade];
默认情况下,hive不允许删除含有表的数据库,要先将数据库中的表清空才能drop,否则会报错
restrict:默认是restrict,表示有限制的
cascade:加入cascade关键字,可以强制删除一个数据库
强制删除一个数据库:drop database if exists users cascade;
4.切换数据库:use 数据库名;
4.搭建 spark 集群:此处使用spark HA集群
1.在NODE1主节点上启动 start-all.sh 命令 启动 spark集群
cd /root/spark/sbin
./start-all.sh
2.然后在NODE2节点上 启动多一个 master节点(那么此时NODE1和NODE2都有master节点,并交由zookeeper来进行选举)
cd /root/spark/sbin
./start-master.sh
3.停止spark集群
在 上执行:cd /root/spark/sbin
./stop-all.sh
2.sparksql 整合 hive
Spark SQL 主要目的是使得用户可以在 Spark 上使用 SQL,其数据源既可以是 RDD,也可以是外部的数据源 (比如文本、 Hive、 Json 等)。
Spark SQL 的其中一个分支就是 Spark on Hive, 也就是使用 Hive 中 HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,
可以近似认为仅将物理执行计划从 MR 作业替换成了 Spark 作业。SparkSql 整合 hive就是获取 hive 表中的元数据信息,然后通过 SparkSql 来操作数据。
1.整合步骤:
1.需要将 /root/hive/conf/hive-site.xml 文件拷贝到 /root/spark/conf/ 目录下,这样就可以通过这个配置文件找到 Hive 的元数据以及数据存放位置。
hive-site.xml中:配置了hive的元数据对应存储的数据库
cp /root/hive/conf/hive-site.xml /root/spark/conf
scp /root/hive/conf/hive-site.xml NODE2:/root/spark/conf
scp /root/hive/conf/hive-site.xml NODE3:/root/spark/conf
2.如果 Hive 的元数据存放在 Mysql 中,我们还需要准备好 Mysql相关驱动,比如:mysql-connector-java-5.1.32.jar
因为spark和hive整合之后,任务都运行在spark引擎中,因此spark引擎需要MySQL建立连接来读取hive表的元数据信息,所以需要MySQL驱动
cp /root/hive/lib/mysql-connector-java-5.1.32.jar /root/spark/jars
scp /root/hive/lib/mysql-connector-java-5.1.32.jar NODE2:/root/spark/jars
scp /root/hive/lib/mysql-connector-java-5.1.32.jar NODE3:/root/spark/jars
2.进入 spark-sql 客户端命令行界面出现的日志太多的话,可以修改 spark 的日志输出级别:配置为WARN级别的话,则可以把info信息都屏蔽掉不显示了
cd /root/spark/conf/
mv log4j.properties.template log4j.properties
vim log4j.properties
把 log4j.rootCategory=INFO, console 修改为 log4j.rootCategory=WARN, console
3.测试 sparksql 整合 hive 是否成功
1.先启动 hadoop 集群,再启动 spark 集群,确保启动成功之后执行命令。
1.如果使用的是 spark 2.0 之前的版本,启动命令是:指明 master 地址、每一个 executor 的内存大小、一共所需要的核数、mysql 数据库连接驱动
/root/spark/bin/spark-sql \
--master spark://NODE1:7077 \
--executor-memory 1g \
--total-executor-cores 4 \
--driver-class-path /root/hive/lib/mysql-connector-java-5.1.35.jar
2.如果使用的是 spark 2.0 之后的版本,启动命令是:需要指定表数据的hdfs存储路径,才能把spark-sql命令操作的数据库也存储到hdfs文件系统中
/root/spark/bin/spark-sql \
--master spark://NODE1:7077 \
--executor-memory 1g \
--total-executor-cores 4 \
--conf spark.sql.warehouse.dir=hdfs://NODE1:9000/user/hive/warehouse
2.执行成功后的界面:进入到 spark-sql 客户端命令行界面
3.接下来就可以通过 sql 语句来操作 MySQL数据库中的 hive 表的元数据信息。
查看当前 hive 有哪些数据库:show databases;
创建新的数据库:create database t_db;
使用该数据库:use t_db;

4.使用 /root/spark/bin/spark-sql 命令操作 hive数据库表 之后,便会在同样的当前 /root/spark/bin 目录下生成 spark-warehouse文件夹,
该文件夹用于存储“使用该命令所创建的”表和表数据的信息。
虽然此时 使用spark-sql命令存储数据的目录 和 使用hive命令存储数据的目录 并不是同一个目录,
但是均可以使用spark-sql命令和hive命令操作访问同一个hive数据库表数据,因为此时hive和spark共用同一份元数据库。
5.hive命令操作的数据库则在hdfs文件系统中,这是利于提交数据到spark集群中运行的。
而目前spark-sql命令操作的数据库仍然在本地文件系统下的 /root/spark/bin/spark-warehouse/数据库名/表名,
这是不利于提交数据到spark集群中运行的,此时仍然没有整合成功。
解决:要把spark-sql命令操作的数据库也存储到hdfs文件系统中。
