背景:
对于一些处于Hadoop向Spark迁移的过程中,可能一些老的应用还是在Yarn来资源调度的,那么此时用Spark如何来触发Yarn调度呢
步骤:
1、将原Spark集群的node01集点的配置改成如下
export JAVA_HOME=/usr/java/jdk1.8.0_162
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.4/etc/hadoop2、启动yarn
start-yarn.sh3、计算Pi值
./bin/spark-submit --class org.apache.spark.examples.SparkPi
--master yarn
--deploy-mode cluster
--driver-memory 1g
--executor-memory 1g
--executor-cores 2
--queue default lib/spark-examples*.jar 104、运行完成后如下图所示
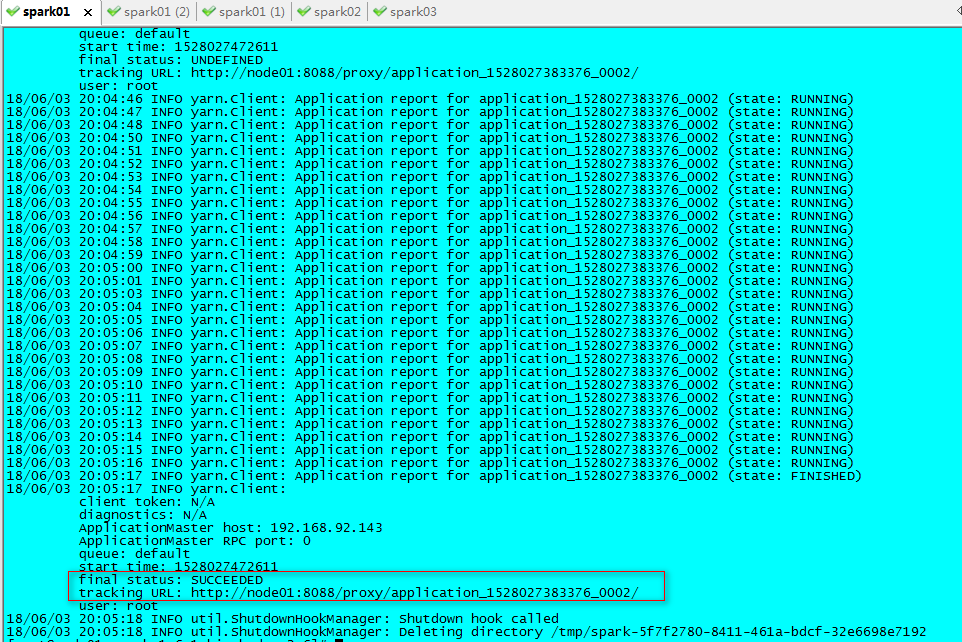
5、在控制台中观察结果:node01:8088的logs
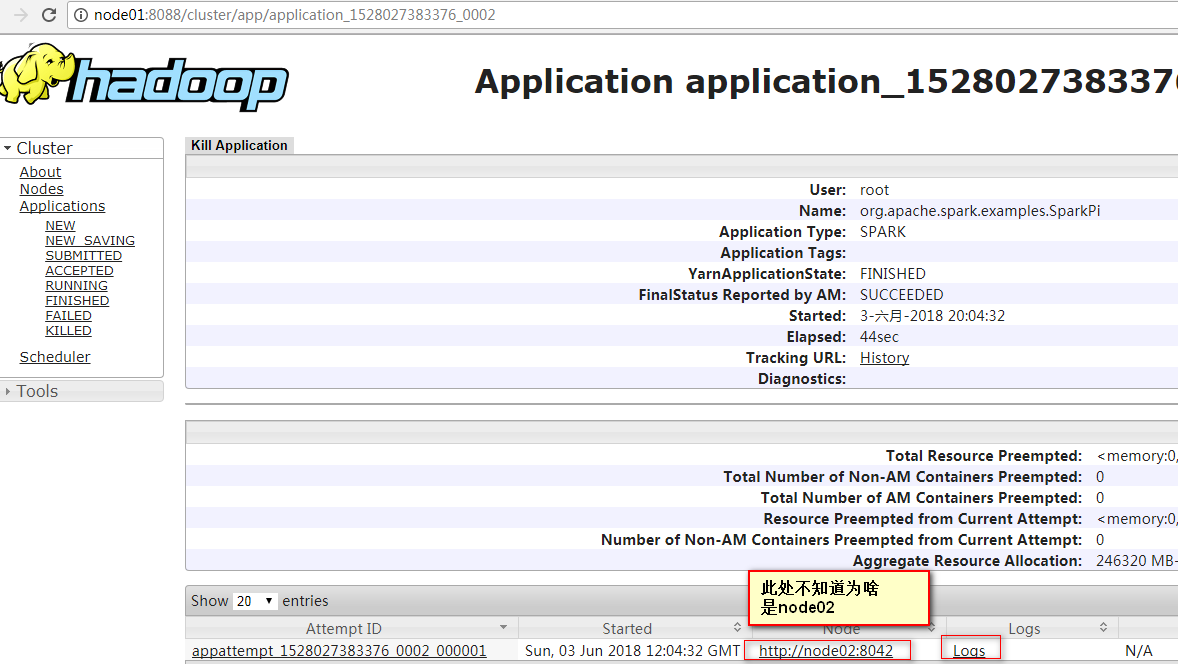
注意:但这个地方,不知道为什么Node节点显示的是node02,从Logs链接点进去后,即使强行将域名改成node01,也显示无日志,真是蛋疼