软件版本:
IDE:Intellij IDEA 14,Java:1.7,Tomcat:7,CDH:5.8.0; Spark:1.6.0-cdh5.8.0-hadoop2.6.0-cdh5.8.0 ; Hadoop:hadoop2.6.0-cdh5.8.0;
部署环境:
1. 在Windows10 上启动IDEA ,并启动Tomcat,在Tomcat中使用Spark On YARN的方式调用封装好的Spark算法;
2. 调用的集群使用CDH集群(使用的是Cloudera官网下载的虚拟机,所以是单节点,由于这个是单机版的所以把YARN的配置文件改了下,改为使用YARN,而且虚拟机还配置了静态ip);
工程参考:
1. Web工程调用Spark集群算法,使用Spark On YARN的方式调用,参考基于Spark ALS在线推荐系统 ,不过这个使用的是原生Spark及Hadoop安装包进行集群部署及工程配置的;(说白了就是不适合CDH集群,如果适合的话,还写这篇文章干啥);
2. Spark算法封装参考:https://github.com/fansy1990/Spark_MLlib_Algorithm_1.6.0 ,这个工程install即可得到对应的封装好的算法Jar包;
3. 本文章使用的工程参考:https://github.com/fansy1990/Spark_MLlib_1.6.0_,其部署参考:https://github.com/fansy1990/Spark_MLlib_1.6.0_/blob/master/README ;
问题描述:
1.Classpath问题
1. 参考基于Spark ALS在线推荐系统 中的配置进行调用CDH集群运行任务,发现其ClassPath有问题;
具体表现为org.apache.hadoop.conf.Configuration类找不到,如下:

2. 使用Spark-submit的方式提交任务可以正常运行:
1) 其AM Launch Context如下:

2) 但是使用Web提交的时候对比发现,其AM Launch Context中的CLASSPATH对应不到,缺少了一些本地的jar包;如下:
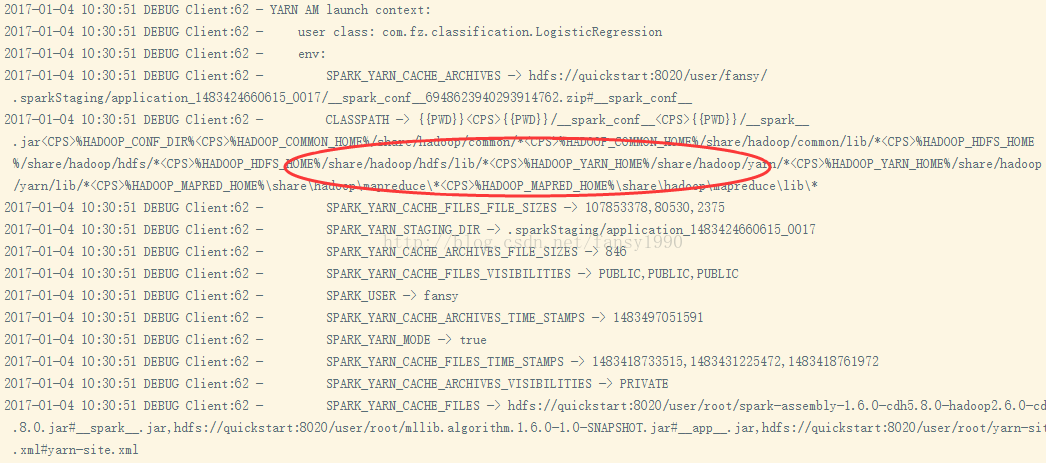
发现后面跟的参数不一样,也就是Classpath的问题了,怎么添加呢?在生成Configuration的时候添加yarn.application.classpath即可,如下:
conf.set("yarn.application.classpath","/usr/lib/spark/lib/spark-assembly.jar:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/*:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/*:/usr/lib/hive/lib/*:/usr/lib/flume-ng/lib/*:/usr/lib/paquet/lib/*:/usr/lib/avro/lib/*");2. Windows & LInux问题
1. 参考上节修改完成后,使用Windows再次提交发现下面的问题:
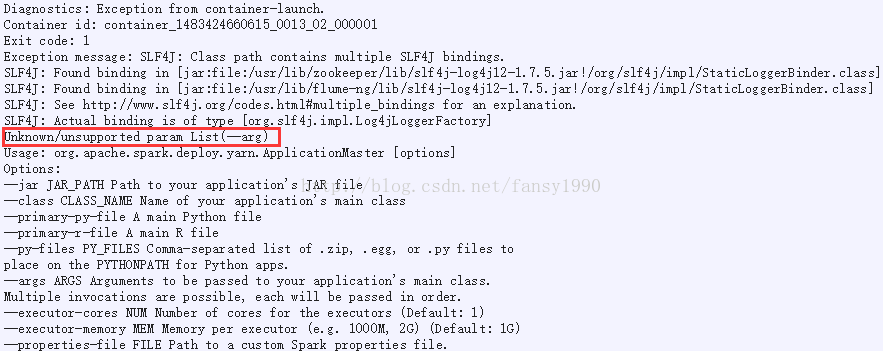
2. 但是使用Linux部署TOmcat,却是可以运行的;通过对比提交命令,如下:
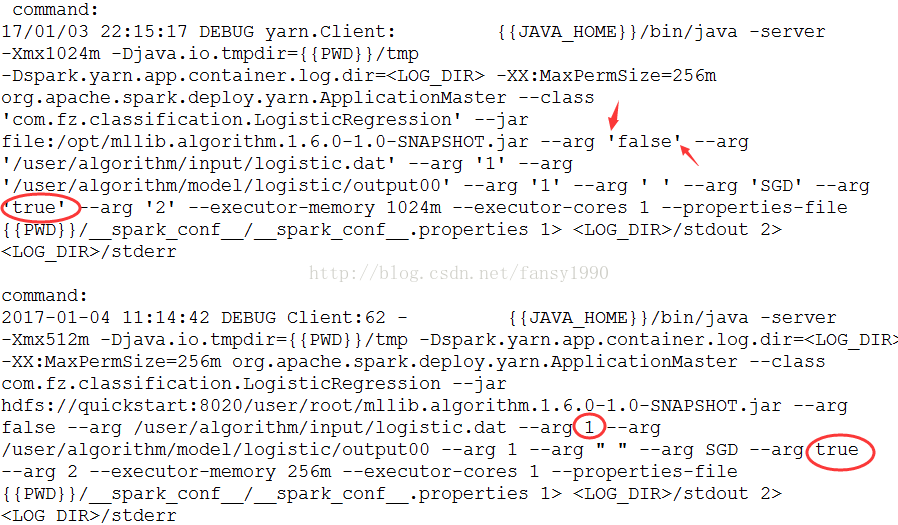
上面是Linux提交的,下面是Windows提交的;
这就奇怪了,查看其源码;
3. 查看ApplicationMaster源码,查看其args与arg的区别:
首先了解下Spark On YARN提交流程:Client –> ApplicationMaster ,所以也就是说是Client构造的参数,然后提交给ApplicationMaster。那看看其源码(org.apache.spark.deploy.yarn.Client):

发现Client 中构造的是确实是—arg,也就是说ApplicationMaster应该处理的也是arg参数,而非args参数,查看ApplicationMaster(org.apache.spark.deploy.yarn.ApplicationMaster)源码:
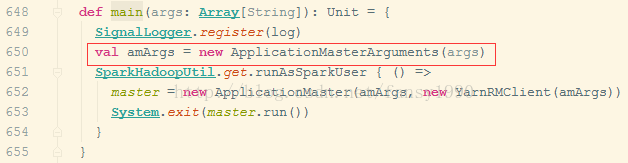
其处理参数使用的是ApplicationMasterArguments,看ApplicationMasterArguments是怎么处理参数的呢?

所以也就是说其是使用--args和--arg都是可以的,那为什么单单Windows提交不行呢?
4. Windows --arg问题解决
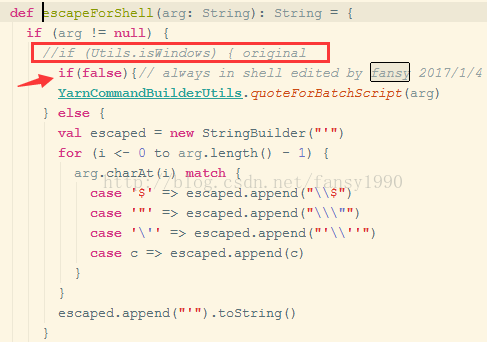
通过对比Linux和Windows提交的Command参数,发现在--arg参数后面,如果使用Linux提交,那么其后的参数被单引号引起来了,但是Windows提交的时候就没有,这也就是说在Client构造--arg参数的时候,Windows和Linux是不一样的,在Client源码843行中有这样一句:
Seq("--arg", YarnSparkHadoopUtil.escapeForShell(arg))
通过上面的修改,那么Windows提交任务到YARN上就不会出现--arg参数notsupport的提示了;
5. 未知问题
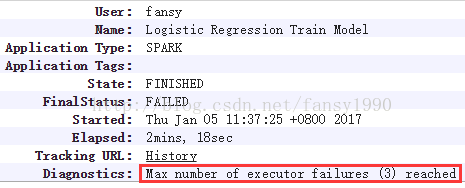
表现,在主监控表现:
在日志表现:

这就很奇怪了,启动了3个executor,但是3个都不知道什么原因失败了,然后达到了3次最大失败次数,然后就失败了;
6. 怎么解决未知问题:
这个还需要通过日志来,首先说明有两个Context,其一是AM Launch Context,其二是Executor Launch COntext,对比发现,Web提交的和Submit提交的,这两个还是不一样:

所以这里还是要解决SPARK_DIST_CLASSPATH的问题,其实这个问题说简单就很简单,只需要在sparkConf里面加个设置即可:
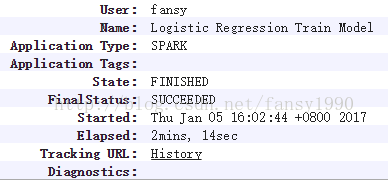
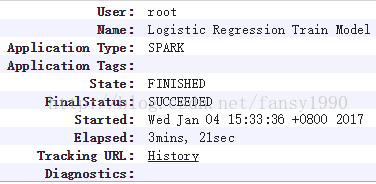
sparkConf.set("spark.yarn.appMasterEnv.SPARK_DIST_CLASSPATH","/usr/lib/spark/lib/spark-assembly.jar:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/*:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/*:/usr/lib/hive/lib/*:/usr/lib/flume-ng/lib/*:/usr/lib/paquet/lib/*:/usr/lib/avro/lib/*");System.setProperty("spark.yarn.appMasterEnv.SPARK_DIST_CLASSPATH","/usr/lib/spark/lib/spark-assembly.jar:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/*:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/*:/usr/lib/hive/lib/*:/usr/lib/flume-ng/lib/*:/usr/lib/paquet/lib/*:/usr/lib/avro/lib/*");再次提交任务,发现任务运行成功:
解决方案
1. 使用原生Spark Assembly jar包
2. 设置SPARK_DIST_CLASSPATH参数
总结:
1. Spark On YARN ,不能直接套用,针对CDH集群或HDP集群其一些表现和开源版本还是有不一样的地方的;
2. 针对出现的问题,要思路清晰,需要了解其整体流程,这样就可以去排查错误了;
3. 针对出现的问题,还可以通过对比验证的方式来解决,比如Spark On YARN,可以试试Spark-submit的方式是否可以提交任务?如果可以提交任务,那么使用Web提交和Spark-submit提交有什么异同呢?把不一样的地方给它整一样了,是否问题就解决了呢?
分享,成长,快乐
脚踏实地,专注
转载请注明blog地址:http://blog.csdn.net/fansy1990