版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011291159/article/details/68490663
Spark 版本发布很快,CDH集成最新Spark版本需要一定时间,并且CDH 集成的Spark版本不支持Spark-sql。本文档的目的在目前cdh平台集成最新spark,方便测试和使用最新功能。
- spark-env.sh
#HADOOP_CONF_DIR hadoop 配置文件目录 ,cdh 客户端都放在/etc/spark/conf/yarn-conf下面。当重现部署hdfs 和yarn配置文件,该目录下面的配置也会更改。
export HADOOP_CONF_DIR=/etc/spark/conf/yarn-conf
#YARN 配置文件目录
export YARN_CONF_DIR=/etc/spark/conf/yarn-conf
# spark hostory 配置项。设置jvm 参数、日志存放目录和端口。
export SPARK_HISTORY_OPTS="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/historyserver.hprof -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/tmp/historyserver.gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=512M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=19227 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dspark.history.fs.logDirectory=hdfs:///user/yourname/tmp/sparklogs -Dspark.history.ui.port=18179"- spark-default.xml配置
#启用eventlog功能
spark.eventLog.enabled true
#设置 eventlog 目录
spark.eventLog.dir hdfs:///user/yourname/tmp/sparklogs3. keytab 配置
由于目前 cdh 集群 安装了kerberos,spark 访问 hdfs 和yarn 需要生成keytab。下面是生成的keytab的过程:
keyadmin.local
addprinc -randkey wuwei79
xst -norandkey -k wuwei79.keytab wuwei79
上面步骤需要在root下面执行,麻烦联系kerberos管理人员
下面执行kinit
sh-4.2$ kinit -kt wuwei79.keytab wuwei79
sh-4.2$ klist
Ticket cache: FILE:/tmp/krb5cc_2114
Default principal: wuwei79@IDC.WANDA-GROUP.NET
Valid starting Expires Service principal
11/02/2016 08:49:34 11/03/2016 08:49:34 krbtgt/IDC.WANDA-GROUP.NET@IDC.WANDA-GROUP.NET4. 启动
[wuwei79@bjs0-3a5 spark]$ bin/spark-shell --master yarn
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/11/01 16:57:33 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
16/11/01 16:57:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/01 16:57:34 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
16/11/01 16:57:51 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://10.199.192.12:4041
Spark context available as 'sc' (master = yarn, app id = application_1477640792635_0012).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.parallelize(1 to 100,20).map(x=>x*0.078).collect()
res0: Array[Double] = Array(0.078, 0.156, 0.23399999999999999, 0.312, 0.39, 0.46799999999999997, 0.546, 0.624, 0.702, 0.78, 0.858, 0.9359999999999999, 1.014, 1.092, 1.17, 1.248, 1.326, 1.404, 1.482, 1.56, 1.638, 1.716, 1.794, 1.8719999999999999, 1.95, 2.028, 2.106, 2.184, 2.262, 2.34, 2.418, 2.496, 2.574, 2.652, 2.73, 2.808, 2.886, 2.964, 3.042, 3.12, 3.198, 3.276, 3.354, 3.432, 3.51, 3.588, 3.666, 3.7439999999999998, 3.822, 3.9, 3.978, 4.056, 4.134, 4.212, 4.29, 4.368, 4.446, 4.524, 4.602, 4.68, 4.758, 4.836, 4.914, 4.992, 5.07, 5.148, 5.226, 5.304, 5.382, 5.46, 5.538, 5.616, 5.694, 5.772, 5.85, 5.928, 6.006, 6.084, 6.162, 6.24, 6.318, 6.396, 6.474, 6.552, 6.63, 6.708, 6.786, 6.864, 6.942, 7.02, 7.098, 7.176, 7.254, 7.332, 7.41, 7.4879999999999995, 7.566, 7.644, 7.722, 7.8)5. 启动historyServer
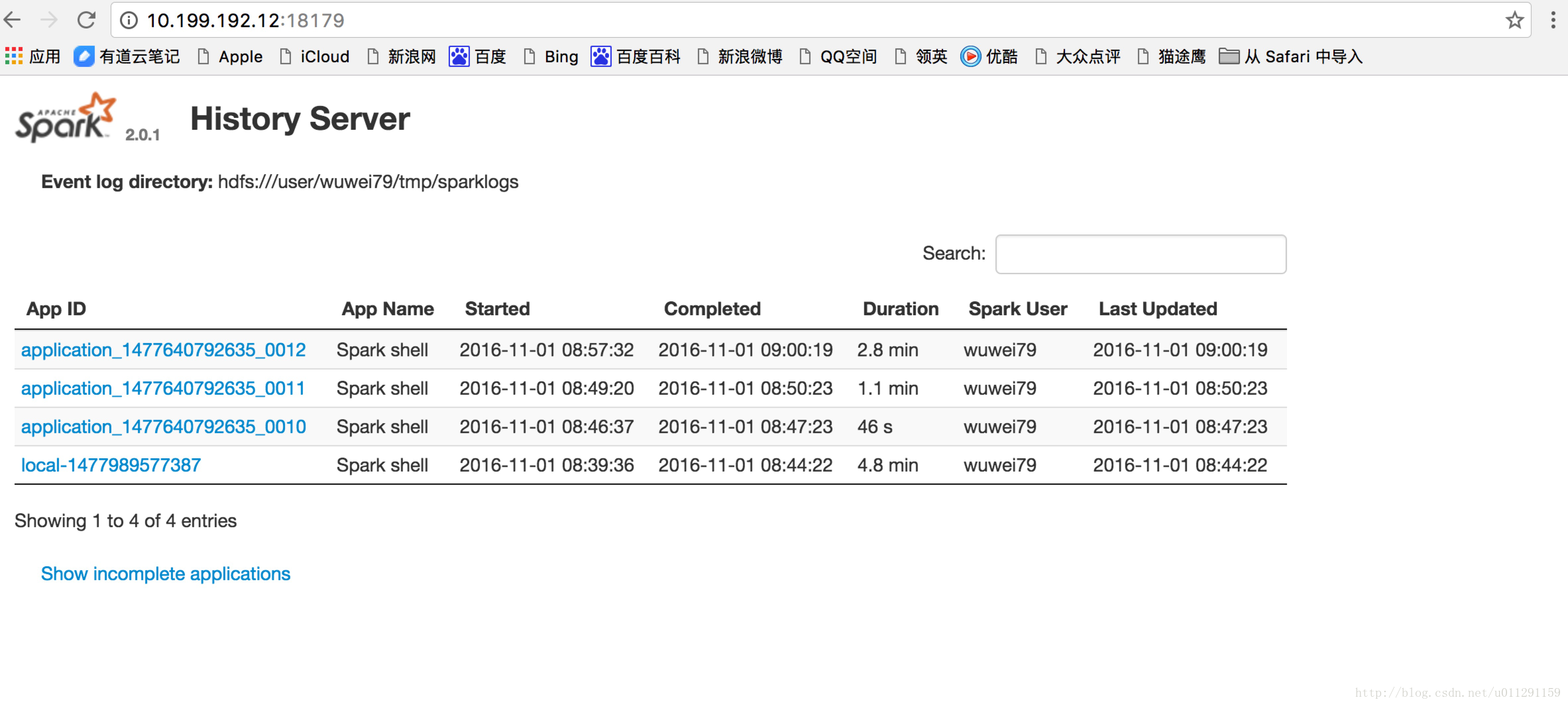
[wuwei79@bjs0-3a5 spark]$ sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/wuwei79/spark/logs/spark-wuwei79-org.apache.spark.deploy.history.HistoryServer-1-bjs0-3a5.big1.lf.wanda.cn.out