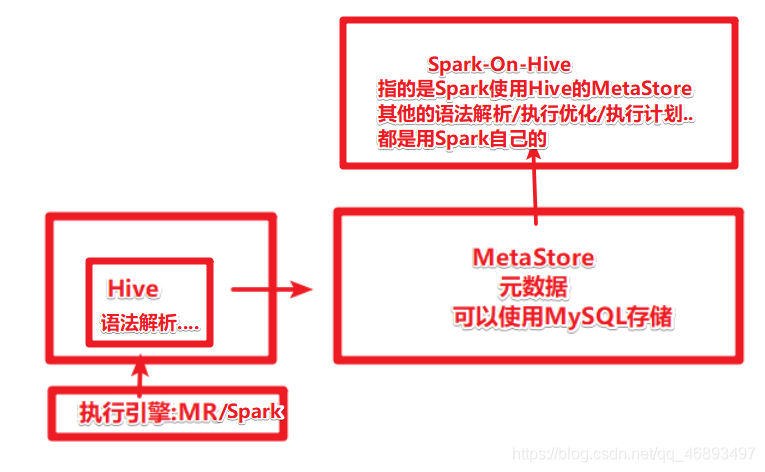
Spark-On-Hive-★★★★★
引入
- 之前学习的Hive可以用来构建数据仓库/使用sql用来替代mr代码来进行数据分析
- 也就是说之前的Hive有两个功能:
- 1.构建数仓,管理元数据(表,字段,类型…)
- 2.使用sql分析数据
注意
- 注意1:
- HiveSQL底层执行的还是MR,效率很低,所以出现了很多替代技术,如使用Tez作为HiveSQL的底层执行引擎
- CDH推出的Impala… (Tez现在在国内用的不多 新版Hive中默认用的Tez不用mr了)
- MR这辈子都不会写了, 除非你做教育,教别人入个门
- 注意2:
- Spark诞生之后,因为Spark执行速度快,所以就有人开发了一个Shark项目,用来将Hive的执行引擎换成Spark执行引擎,也就是Hive-On-Spark
- 但是该项目维护较为困难, 因为考虑Hive本身的很多东西,如语法解析/执行计划…
- 也就是和Hive太耦合了, 所以逐渐也就没人用了
- 注意3:
- 那么Spark-On-Hive又是啥?
- 在Spark1.0的时候,Spark官方就不再考虑Shark了,而是自己独立开发一一套SparkSQL, 有自己的语法解析/执行计划/执行引擎…甚至包括有自己的元数据管理
- 也就是说SparkSQL的野心很大,想占领SQL分析市场,干掉Hive–全栈处理…
- 注意4:
- Hive本身发展很成熟, 公司中很多项目都是使用Hive来构建的,特别是元数据管理这块,之前都是用Hive
- 而执行引擎经历了从MR–>Tez–>Impala…Spark…
- 也就是说Hive虽然原本的执行慢但是换执行引擎啊!,所以Hive的元数据管理功能一直都在被使用,特别是数据仓库项目中
Spark-On-Hive的原理到底是什么?
整合步骤
准备配置文件
-
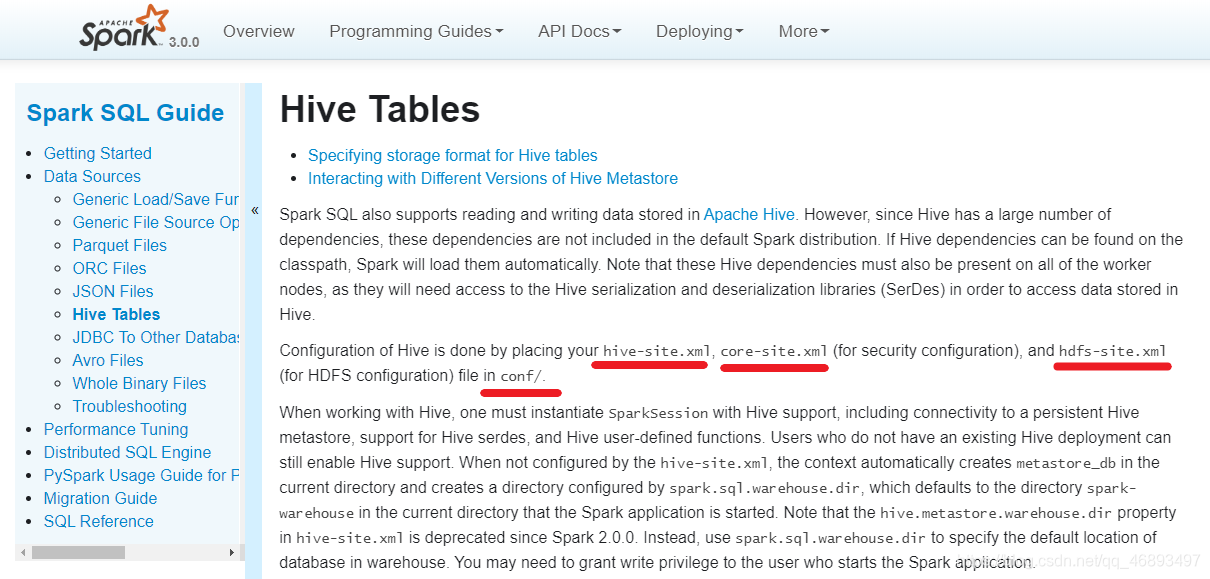
Spark-On-Hive需要知道HDFS和Hive的一些配置文件,所以需要把这些配置文件给Spark,也就是复制到Spark的conf中
-
Hive的MetaStore还需依赖MySQL,所以最好也把MySQL驱动给Spark/jars目录
-
那么这样的话就可以使用spark/bin目录下的 spark-sql命令行并执行HiveSQL了
-
http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
-
后续如果需要使用l命令行执行HiveSQL就可以按照这样做!
-
那么如果要在idea中写代码使用HiveSQL呢?
-
那么得在代码中提供这些配置文件即可

开启MetaStore服务
1.得保证自己的hive-site.xml中有如下配置
vim /export/servers/hive/conf/hive-site.xml
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node-01:9083</value>
</property>
2.后台启动hive的MetaStore服务
nohup /export/servers/hive-1.1.0-cdh5.14.0/bin/hive --service metastore 2>&1 >> /var/log.log &
3.过一会jps查看进程
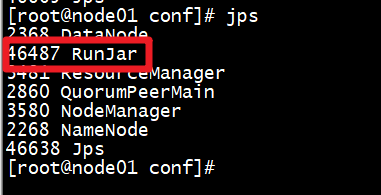
- 看到上图说明Hive的MetaStore服务就启动成功
- 这样后就可以使用SparkSQL来访问
代码实现
package cn.hanjiaxiaozhi.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
/**
* Author hanjiaxiaozhi
* Date 2020/7/25 11:49
* Desc 演示Spark-On-Hive
* 本质就是Spark访问Hive的MetaStore元数据
* 然后执行HiveSQL,并使用Spark的语法解析和执行引擎
* 也就是Spark-On-Hive仅仅使用Hive的MetaStore元数据和HDFS
* 剩下的语法解析和执行引擎都是用Spark自己的
*/
object HiveSupport {
def main(args: Array[String]): Unit = {
//1.创建Spark-On-Hive执行环境
val spark: SparkSession = SparkSession.builder()
.appName("sql")
.master("local[*]")
//.config("spark.sql.warehouse.dir", "hdfs://node01:8020/user/hive/warehouse")
//.config("hive.metastore.uris", "thrift://node01:9083")
//上面两个配置可以不用,因为resources下的配置文件会被自动加载,都有了
.enableHiveSupport()//表示开启HiveSQL的语法兼容/支持
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//注意:如果hdfs权限不足添加如下代码,并在node01上执行 hadoop fs -chmod 777 /
//System.setProperty("HADOOP_USER_NAME", "root")
//2.编写HiveSQL,以前怎么写,现在就怎么写
spark.sql("show tables").show()
spark.sql("CREATE TABLE person6 (id int, name string, age int) row format delimited fields terminated by ' '")
spark.sql("LOAD DATA LOCAL INPATH 'file:///D:/data/spark/person.txt' INTO TABLE person6")
spark.sql("show tables").show()
spark.sql("select * from person6").show()
}
}