故事背景
文章:Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
代码:https://github.com/itijyou/ademxapp
这是adelaide沈春华老师组的一篇文章,一作是zifeng wu

在Pascal上得到了很好的结果,最终仅比商汤的低一点,之前笔者曾经涉及过此文,http://mp.weixin.qq.com/s/L_e4cUUyLQulXv9QUgjxGA
网络的加深一般来说会提高网络的表现能力,可是随着网络越来越深,每增加一层的增益也会越来越低,而且会带来显存及训练上的额外花费,本文提出了更浅也wider的网络
一句话总结
本文在保持可以end2end的深度(17 residual units)的情况下增加宽度,得到了更有表现力的模型,同时发现同一模型在分类和分割两方面表现不一定 一致。
1 ResNet
首先,作者认为ResNets可以看为多个sub-networks的融合网络,而且融合的数量与sub-networks的数量呈线性关系,如下图:
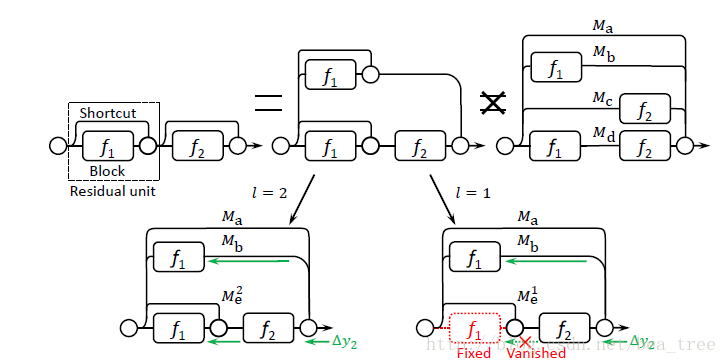
原因是作者因为f2是非线性的,不可以将f1单独视为f2的一个输入。
其次,作者认为ResNet的特性决定因素之一是effective depth,超过effective depth之后,梯度就会消失,如上图中右下角的地方,当effective depth L等于1时,Delta y2通过f2之后就会消失,因此Delta w1 不会通过Me1更新,但是如果L=2那么可以看出w1的更新速度要比w2更快。
再次,作者认为,ResNet的这种形式,内在的起到了regularization的效果,可以减少wide layers的过拟合效果。
另外,作者认为,一个residual unit 需要1)好收敛 2)尽量浅 所以作者选用了两个wide layers每个unit
还有,作者认为,当深度超过一定值之后,再次增加深度相当于得到了一个不完全end2end的更wide的网络,但是不确定这样的效果会不会变好,所以本文只讨论在可以end2end的前提下,增加wide。本文最好的模型有17个residual unit。
关于梯度弥散与ResNet的梯度变化:
Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Trans.
Neural Netw., 5(2):157–166, Mar. 1994
Residual networks behave like ensembles of relatively shallow networks arXiv:1605.06431
2 分类模型
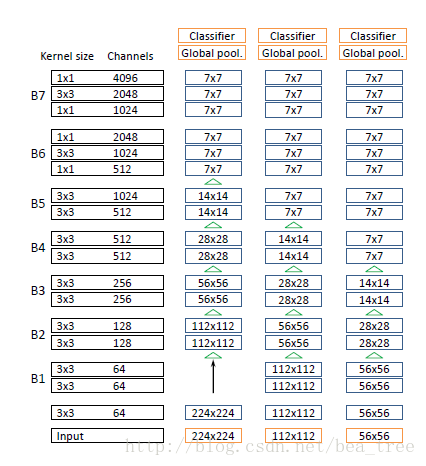
如上图,为了不让channel数变化太突然,B6 B7依然采用bottleneck structures,所有的下采样都是pooling layers。
模型使用mxnet,4个12g卡,线性 learning rate策略。
试验结果如下:
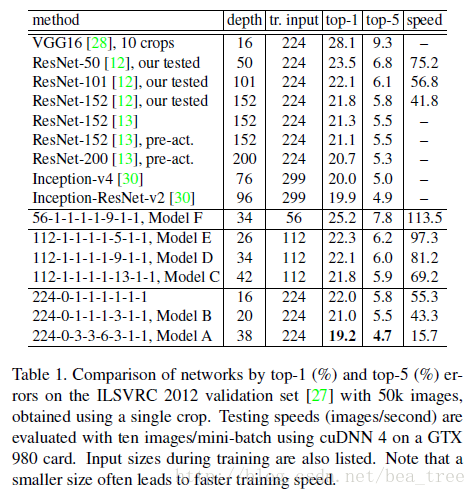
可以发现,A模型最好,小的输入有利于提速,虽然c有更深的网络及更多的参数可是效果与d,e相似。
3 分割模型
这里采用了DeepLab v1中的方法,没有引入
multiscale structuresar :Xiv:1603.03183,
deep supervision signals或者 global context feature: H. Zhao, J. Shi, X. Qi, X. Wang, T. Xiao, and J. Jia. Understanding scene in the wild. http://image-net.org/challenges/talks/2016/SenseCUSceneParsing.pdf, 2016。
使用pooling layer 来下采样发现对于分割无利,于是在最顶端的几个下采样中将pooling除掉,然后改变卷积的stride。然后tune了几万iterations。
另外根据不同的channel数的层使用了不同的dropout策略。
训练时随机将图片resize【0.7-1.3】倍,然后crop 500x500。
训练数据使用semantic boundaries dataset扩充
B. Hariharan, P. Arbel′aez, L. Bourdev, S. Maji, and J. Malik. Semantic contours from inverse detectors. In Proc. IEEE Int. Conf. Comp. Vis., 2011
实验结果:
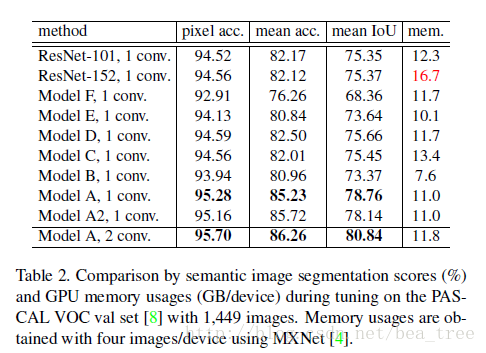
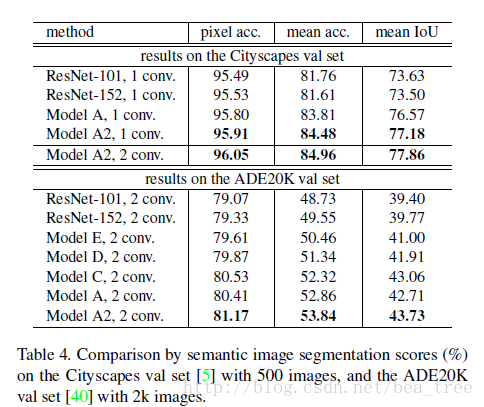
其中A2是在places 365上tune的。2conv是在分类前面加了512channel的3x3卷积隐含层
可以看出b模型在分类上效果好,但是在分割上却不如ResNet101。