Resnet
这篇博客主要介绍了提出Resnet的两篇论文,我分析了两篇论文的核心内容,欢迎大家阅读!
相关论文
2016CVPR Deep Residual Learning for Image Recognition
2016ECCV Identity Mapping in Deep Residual Networks
论文简介
CVPR论文
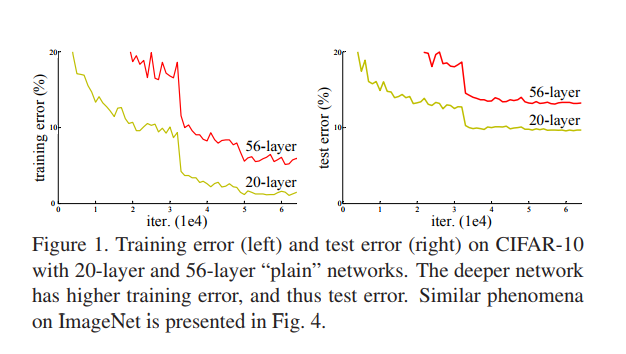
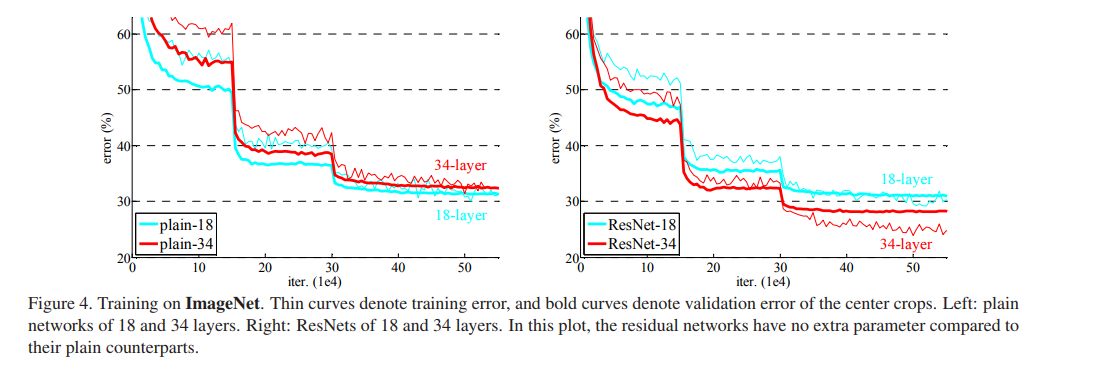
1.极深的深度网络会导致train error 和test error都增加, 这并不是由于overfitting导致的,因为训练集的error也增加。说明不是所有的系统都可以被同样简单地优化。作者全文以一种简单的堆叠(plain)神经网络来于深度残差网络作对比,下图所示即为刚刚所说的简单堆叠引起的误差增加。
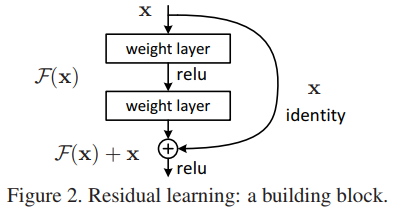
2. 在CVPR这篇论文中最重要的一幅图就是下图,一个更深的残差网络可以由下面的残差单元所组成。在以前的深度学习中我们通常拟合的是
中的
函数,其中
是网络的输入,
是网络的输出,一大串的网络可以抽象为一个非线性
函数(因为使用了非线性激活函数…)。我们现在将原先的函数重新记为
,我们这篇论文网络学习的函数为
,它是原来网络输出和网络输入的差,即为残差。当我们将一大串网络的学习目标改为残差后,那么网络的输出即为
。为了实现和原有输入的相加,我们需要将正常的前向网络添加一个”shortcut connections”。这个”shortcut connections”在这篇论文中就是一个”Identity mapping”(恒等映射),显而易见,恒等映射在原有网络基础上,并不需要参加额外的参数,它仍然可以使用现有神经网络框架的SGD(随机梯度下降)等求解器求解训练。
3. 作者接下来简单介绍了深度残差网络和简单堆叠神经网络在ImageNet和CIFAR-10两个数据集对比结果,发现深度残差网络不仅非常容易优化,而且随着深度的增加残差网络的分类准确率也增加。同时残差网络在其他数据集和其他图像分割检测等任务中表现也十分优秀。拥有极好的扩展性。
4. 作者下一部分Related Work中对残差表示和shortcut connections的相关工作进行了介绍。
5. 作者之后介绍了使用残差这种形式的灵感来源,degradation这个问题暗示了原来的优化网络损失的算法在经过传统很多层非线性网络层后无法近似模拟恒等映射,而通过残差单元中的shortcut connections将x直接送过去,会解决这个问题。
6. 作者下面用这个公式来说明恒等变换的细节。
, 在相加时我们需要保证经过若干神经网络层后即
处理后与
维度相同,所以公式变为
,
仅仅用于匹配维度。作者推荐在残差单元中添加两层或者三层卷积神经网络, 当然更多层也可以尝试,但是一层作者没有观察到残差单元的优势。
7. 作者之后用三种网络结构处理Imagenet, 并进行对比,三种网络结构如下图所示。
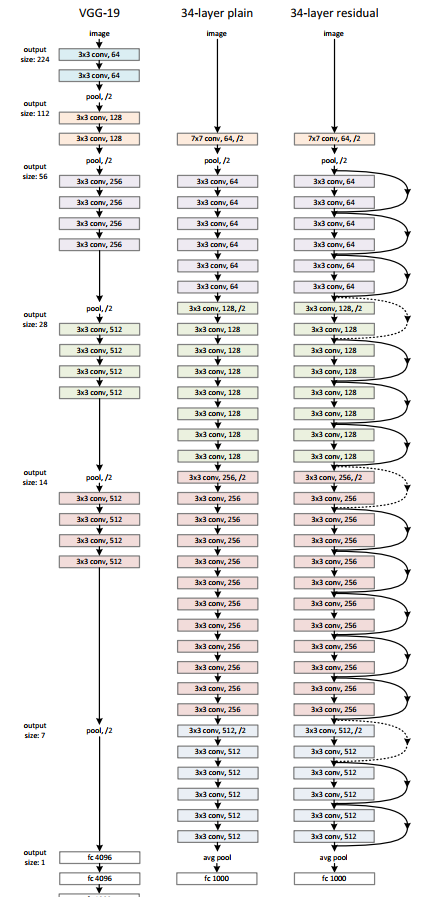
8. 注意到在残差网络虚线处feature map的维度增加了,作者提出了两种选择:
- shortcut仍然是恒等映射,但是额外的0元素进行填充来实现维度增加,这种方法不会增加额外的参数。
- 第二种方法是使用刚刚的有 这个参数的公式来进行一个1*1的卷积操作实现。
9.接下来作者介绍了自己在处理ImageNet数据集使用的一些trick:- 首先将图片resize到[256, 480],之后从中随机裁剪224*224大小,并进行水平翻转,然后进行图像标准化。作者在每次卷积操作后激活前使用BN(Batch Normalization批标准化)操作。使用随机梯度下降的batch_size为256, 学习率初始设置为0.1之后不断的除以10。模型总共训练了 轮, 同时权重衰减为0.0001,动量为0.9,没有使用dropout。
10.下面是具体不同层数的Resnet网络的结构
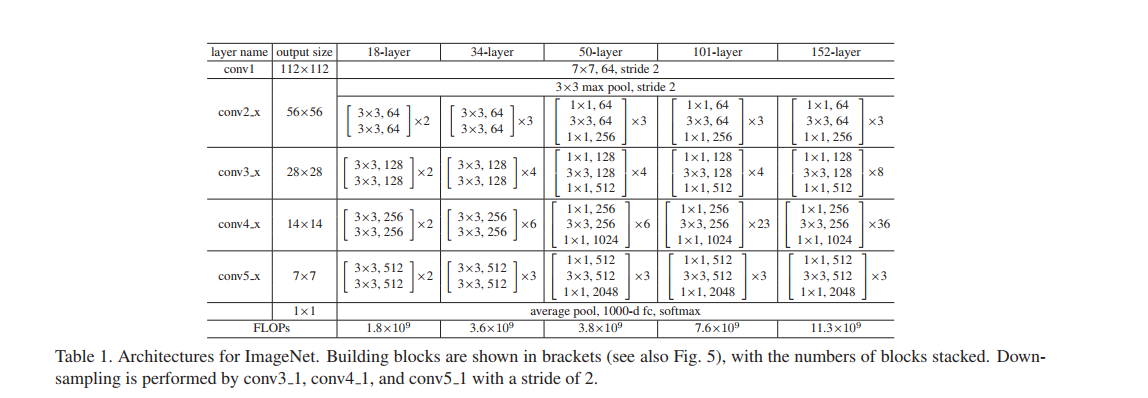
11.下面作者通过图表来比较简单堆叠的神经网络和Resnet的训练误差,进一步看出Resnet层数增加训练误差减小。
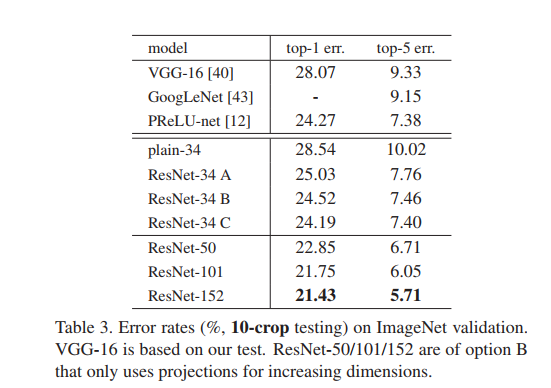
12.之后作者对比了一系列以往模型在ImageNet数据集下的错误率,分为单一模型和集成模型进行比较,可以看出只是单一模型的Resnet就超过了以往所有模型集成的效果,体现出了残差网络的强大。

13.作者之后探讨了3种不同的shortcut方法:- A.当需要增加维度时,使用0来增加维度,其他时候直接传入x,这样便不用增加额外的参数
- B.在增加时使用投影即上面所说的 来增加维度,其他时候直接传入x
- C.在所有shortcut使用投影。
经过对比可以看出其区别并不是很大,而且它对前面提到的最重要的Degradation问题没有重要的影响,所以接下来都采取最简单的A或者B来减小模型的复杂度、内存消耗等。
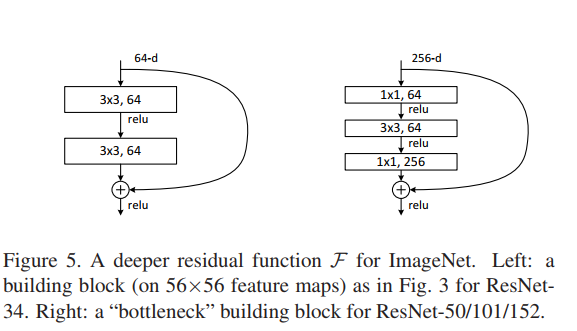
14.之后作者对之前的残差单元(building block)进行了修改,原来的是两个3x3的卷积层,修改后是两个1x1一个3x3的卷积层,这个设计称为bottleneck。1x1的层用来减小然后增加维度,使得3x3的卷积层有着更小的输入和输出维度。这种实现减少了模型的大小。同时作者强调了这样的设计最好使用零填充,不然模型的大小会翻倍。
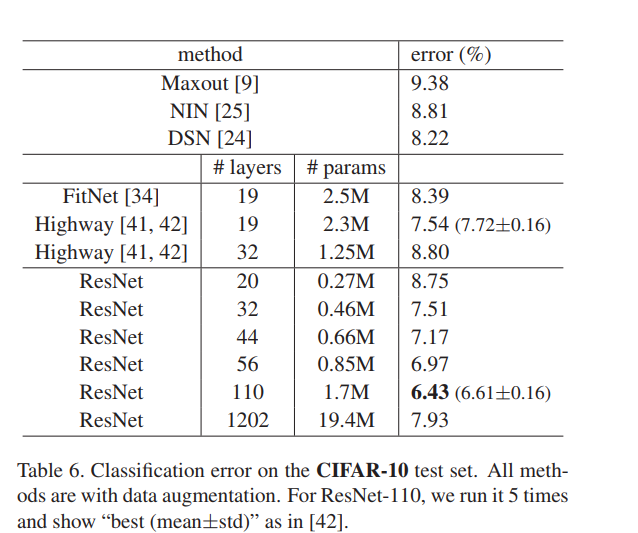
15.然后作者又在CIFAR-10数据集下对比了不同模型的实验结果,同时介绍了一些网络细节。这里有一个十分需要注意的地方就是在1202层的设计中Resnet的错误率并没有下降,因此作者在ECCV发表了第二篇来解决这个问题。
16.最后作者说他们并没有使用maxout、dropout等trick,这些值得研究。同时介绍了残差网络在其他任务的优良表现。
ECCV论文
1.深度残差网络由很多的堆叠的残差单元(Residual Units)组成,每个残差单元都可以用下面的公式表示:
其中
分别为第l个单元的输入和输出,
是残差函数,在之前的论文中
,
是一个ReLU函数。这篇论文主要结论是当
时,信号可以直接从一个单元传入另外一个单元,无论是在前向传播过程中还是后向传播过程中。
2.作者首先为了了解skip connections, 对比了不同类型的
,发现当
时,拥有最快的错误下降率同时有着最小的训练误差。其他方法如scaling、gating以及1x1convolutions都会导致高的错误率和高的训练误差。下面是作者提供的便于对比的图:作者告诉我们传播原始输入的这一条路越“干净”越好。同时注意到右侧proposed作者将BN、ReLU两个操作提前到卷积操作前(称为预激活),预激活相比original的post-activation效果更好,这个解决了上篇论文中在网络更深到1000多层出现的训练误差增大的问题。
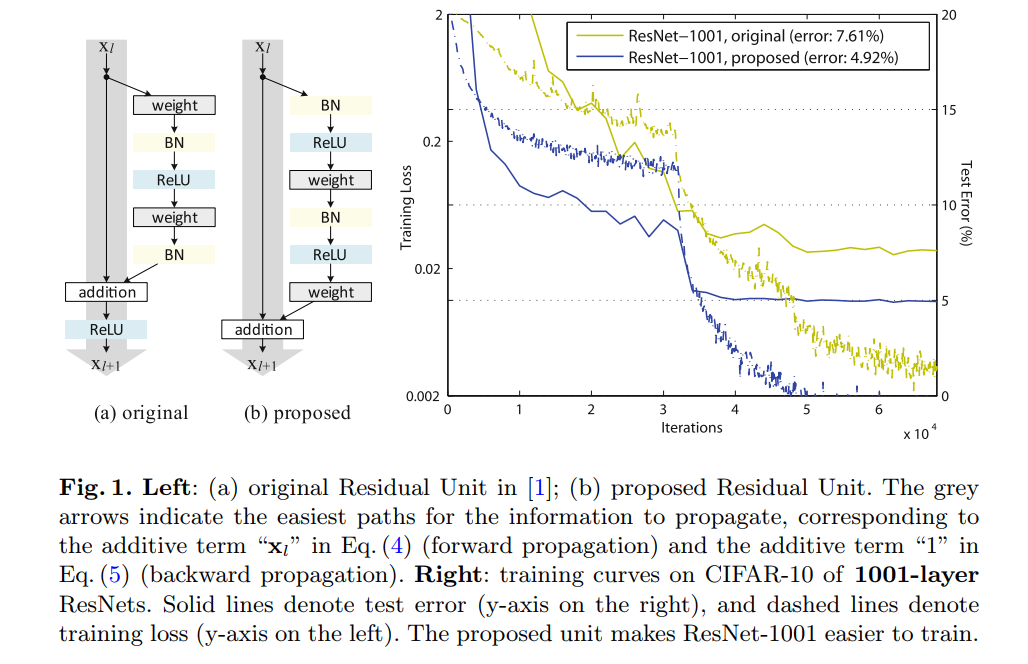
3.作者接下来用公式分析了残差网络,在上面的公式中如果
,那么
当我们对每一个残差单元进行递归计算后可以得到:
。这与简单的堆叠神经网络得到的输出不同,简单的堆叠将会进行一系列的矩阵乘法即
。可以看出如果是连乘的形式很容易出现梯度消失,而残差中的连加,通过求偏导,可以得到:
其中
不可能一直为-1,因此即使权重是任意很小的数,也不会出现梯度消失这种情况。
4.作者接下来分析了Skip Connections的重要性,令
,那么在求梯度时,会出现梯度消失。作者在ResNet-110的结构上比较了不同的Skip Connetions结构。几种机构对比的细节大家可以查看原始论文。
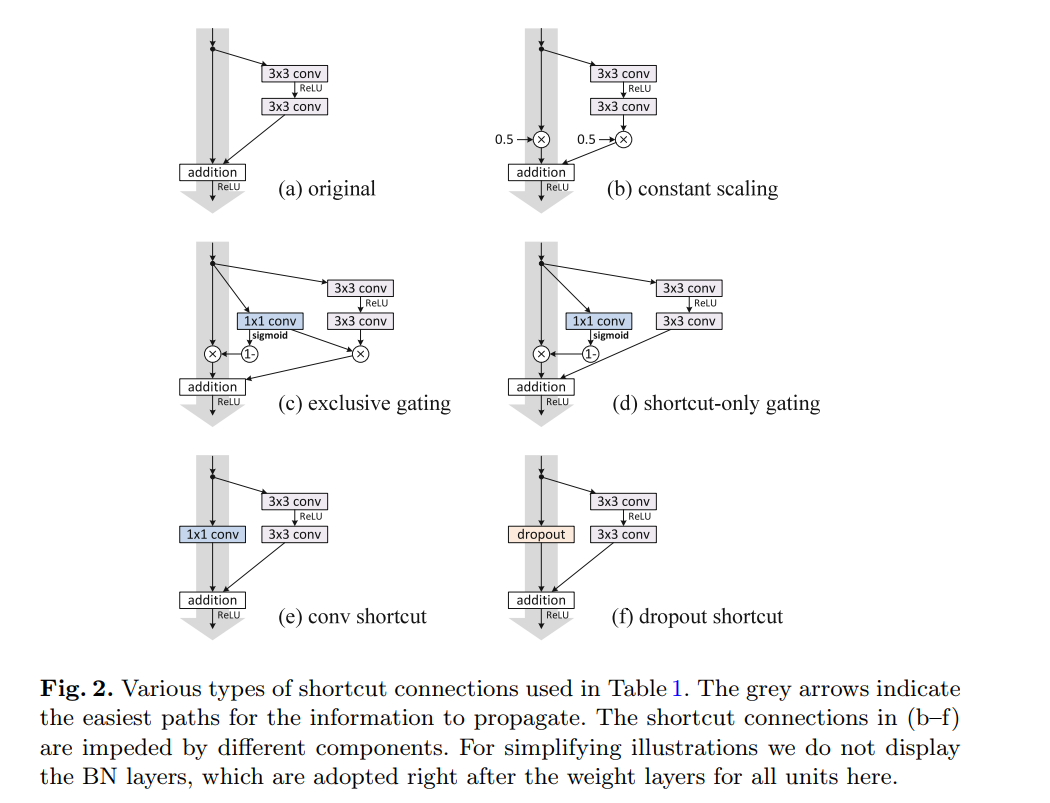
最后对在CIFAR-10上的分类误差进行比较。可以看出原始的干净的SkipConnecttions分类错误率最低。

5.作者下面探索了不同的激活使用方法,并且比较了其导致的分类错误率:具体的细节不在赘述,最后发现BN和ReLU都被用在卷积操作前时,对模型的结果提升最大。预激活有两个好处一个是由于
是恒等映射,优化简单不会在1000层以上出现之前论文的不好结果,然后是BN用于预激活可以提高模型的正则性避免过拟合。

6.最后论文介绍了自己的网络在CIFAR10以及ImageNet上的结果以及一些模型参数细节,这些可以在原文最后找到答案。