原文链接:http://blog.csdn.net/u011771047/article/details/72779221
http://blog.csdn.net/u014451076/article/details/71101850
https://www.cnblogs.com/Jie-Liang/archive/2017/06/29/6902375.html
摘要
图像语义分割越来越受到计算机视觉和机器学习的研究人员的热爱。越来越多新兴的应用领域需要精确地和高效的分割机制:自动驾驶,室内导航,甚至虚拟或增强现实系统等。这种需求几乎与计算机视觉等相关领域或应用目标(包括语义分割)的深度学习方法的兴起保持一致。本文对基于深度学习的语义分割在各个领域的应用做了综述。首先,描述了这个领域术语以及特定的背景概念。紧接着,罗列出主要的数据集和挑战,以便帮助研究人员决定哪些是最适合自己的需求和目标。然后,回顾现有的一些方法,突出的贡献以及在该领域的重要意义,最后,给出所述方法的量化结果和所用的数据集,以及对结果的一些论述,最终,我们指出了一系列有希望的future work,并使用深度学习技巧来得出state of the art关于语义分割的结论。
▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁
1.引言
如今,仍然在二维图像、视频甚至三维或者volumetric data(容积式的数据)上应用甚广的语义分割是计算机视觉领域的至关重要的问题之一。总体上来说,语义分割是一项高水平任务,这将为完成场景理解奠定基础。事实上,场景理解作为核心计算机视觉问题的重要性在于越来越多的应用程序从图像中进行推理。
其中一些应用包括自动驾驶[1] [2] [3],人机交互[4],计算机摄影 [5],图像搜索引擎 [6]和现实增强。过去使用各种传统计算机视觉和机器学习技术已经解决了这样的问题。尽管这样的方法得了普及,但深度学习革命已经扭转了整个形势,包括语义分割的很多计算机视觉问题都利用深层结构[7] [8] [9] [10] [11](通常为CNN)得到了解决,这些结构在精度甚至效率上都远远超过了其他一些方法。然而,深度学习所实现的成熟远不止计算机视觉和机器学习的其他老旧分支所达到的,因此,缺乏统一的作品和艺术评论(review)。不断发生变化现状使得发展难度很大,并且新文学产生量的增加,时刻跟进其演化的速度也是一项令人难以置信的耗时的工作。这使得很难跟踪处理语义分割的结果,并妥善解释他们的提案,修剪次要的方法和验证结果。
尽我们所知,这是第一篇对深度学习在语义分割上的清晰的评论。已经存在的诸多语义分割调查,比如[12][13],都在总结和分类现有的方法,讨论数据集和衡量标准并且对未来研究方向提出了设计选择上做了一项伟大的巨作。但是,他们缺少一些最新的数据集,他们没有分析框架,并且也没有提供深度学习技术的细节。因此,我们的工作是具有新颖有益的且对研究界将会有重大的贡献。

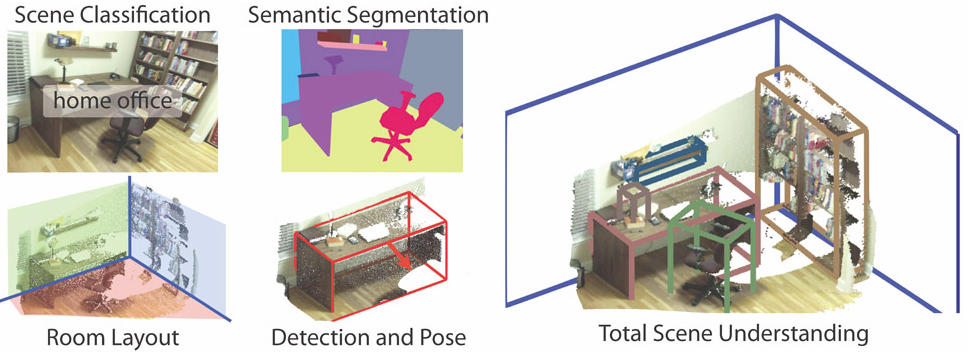
图1.目标识别和场景理解的演化过程,从粗粒度(coarse-grained)到细粒度(fine-grained)推理:分类,检测或者定位,语义分割,实例分割。
我们的工作的主要贡献在以下几点:
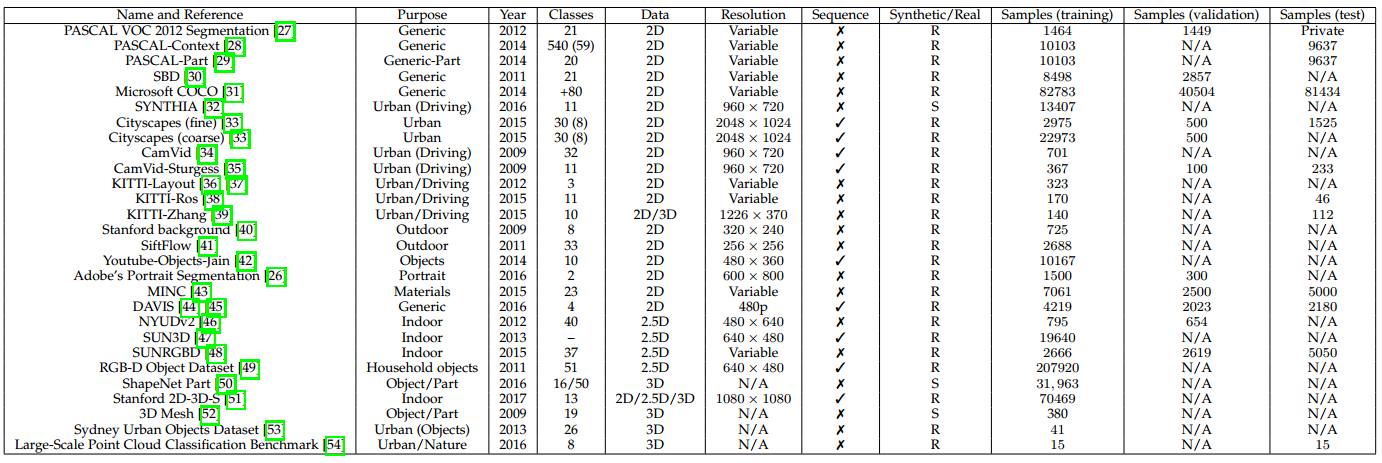
• 我们对现有的数据集进行了广泛的调查,这些数据集将会对深度学习技术的分割项目有益。
• 对那些用深度学习进行语义分割的重要方法进行深度的有组织的评论,包括他们的起源和贡献。
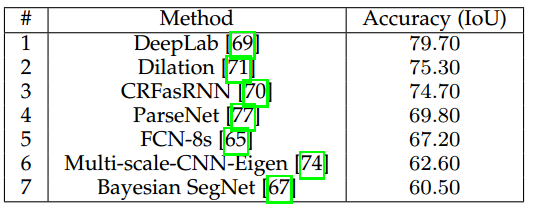
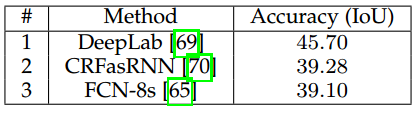
• 全面的性能评估,可以收集诸如准确性,执行时间和内存占用等量化指标。
• 对上述提到的结果进行论述,列出了即将到来的进展的未来可能作品,以及总结目前该领域的最高水平。
文章剩余部分按照以下结构进行组织:
首先,section 2介绍了语义分割的问题以及文学中常用的符号和惯例。对一些常见的深度网络的一些背景概念也进行了综述。然后,section 3详细描述了现有的数据集,挑战和基准。section 4 基于他们的贡献,依照自底向上的复杂性秩序进行了回顾。这一部分主要集中在描述这些方法的理论和突出贡献,而不是进行量化评估。最后,section 5对现有的方法在上述数据集上基于他们的量化结果进行了个简单的讨论,另外,也指出了未来的研究方向。section 6 对本文进行了对该领域最高水平的工作进行了总结并得出结论。
▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁
2 专用术语和背景知识
为了正确的理解语义分割是如何通过近代深度神经结构进行处理的,重要的是知道深度神经网络并不是一个孤立的领域,而是在由粗到细推理过程中一个自然而然的步骤。
最初起源于分类任务,包括对整张输入图片的预测,比如预测一幅图像中包含的物体类别或者甚至提供一个排序列表,如果包含多个物体的话。定位或检测是继续进行fine-grained推理的下一步,不仅提供类别,并且根据这些类别的空间位置提供一些额外的信息,比如中心点或者边框。有了上述的推理,很明显,进行语义分割便是达到fine-grained推理的自然而然的步骤,目标:对每一个像素进行密度预测推理标签,这样的恶化,每一个像素便被标记为它封闭的目标或者区域的类别。可以进一步改进,比如实例分割(对同一类的不同实例物体单独标注)和基于部件的分割(对已经分割的物体进一步分解为他们所包含的部件)
图1 展示了上述提到了演变。本文我们将主要集中关注通常的场景标记,例如,每个像素的分割,但是我们依然会回顾在实例分割和基于部件分割的最重要的方法。
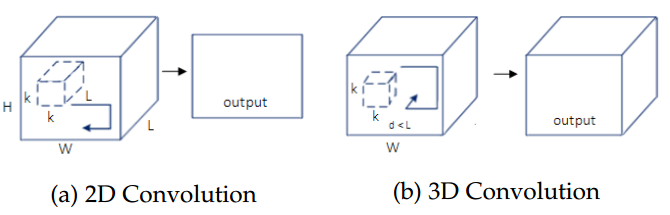
最后,像素标记问题可以简化为下列公式:从标签空间L到随机变量X,找到一种方法进行标记状态。L中每个标签l代表一个不同的类别或者目标,例如飞机,汽车,交通标志,或者背景。这些标签空间包含有k中可能的状态,通常被扩展为k+1种,其中l0作为背景或者空类。通常,X是一个包含WxH=N个像素x的二维图像。当然,这个随机变量序列可以被拓展为任意维度,比如容积数据或者高光谱图像。
除了将问题公式化外,重要的是remark一些背景概念,从而将对读者理解这篇论述文章有所帮助。首先,一些经常用于深度语义分割系统基础的常见的神经网络,方法,设计决策。另外,常用的训练技巧如迁移学习。最后数据预处理和数据增强等方法。
2.1 常见的深度神经网络架构
正如我们之前阐述的那样,一些深度神经网络已经在该领域做出了重要的贡献,并且也成为广为人知的标准。正如ALexNet,VGG-16,GoogleNet ,和ResNet,他们现在被用来作为很多分割系统的建设结构块,这些正是他们的重要性,因此,我们将会用整个部分来回顾他们。
2.1.1 AlexNet
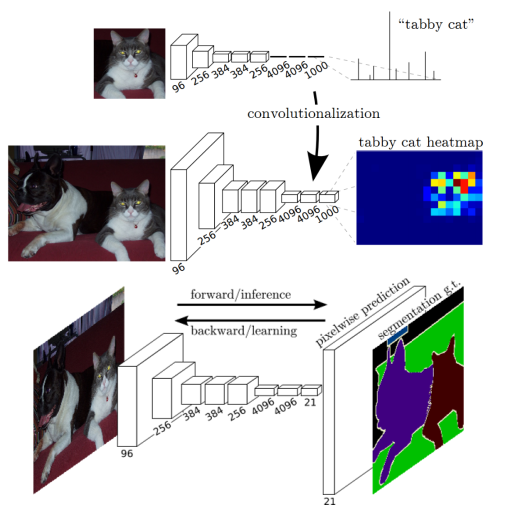
AlexNet是最早的神经卷积神经网络(deep CNN),曾经在ILSVRC-2012比赛中以84.6%的top-5测试准确率取胜,而使用传统技术而不是深层架构的最直接的竞争对手在同样的挑战中的准确率为73.8%。这个Krizhevsky设计的结构是相对简单的,包括5个(卷积层,最大池化层,起非线性作用的ReLus线性修正单元),3个(全连接层,和dropout).图2展现了CNN架构。
2.1.2 VGG
Visual Geometry Group(VGG)是牛津大学VGG实验室推出的CNN模型,他们提出多种深度CNN模型和配置,其中一个提交在ILSVRC-2013上。这个模型,由于是由16个权重层组成的所以被称为VGG-16,以其92.7%的top-5准确率深受人们的欢迎。图3 展示了VGG-16的配置。和之前的主要不同是VGG-16在第一个层次使用了一系列小接受域的卷积层代替拥有较大感受域的较少层(减少感受野的大小,增大卷积层的数量)。这样导致较少的参数数量和更多的非线性,因此,使得决策函数更有区分能力,模型更容易训练。
2.1.3 GoogleNet
GoogleNet是Szegedy设计的一个神经网络,在ILSVRC-2014挑战赛中以93.3%的top-5准确率赢得比赛。这个CNN结构的特征主要是他的复杂性,主要体现在它是由22层和一个新引进的inception(见图4)的建设结构块组成。这种新的方法证实了神经网络网络层是可以以多种方式堆叠的,而不单是一种传统的顺序方式。事实上,这些模型都是由NiN 层,池化操作,大尺度的卷积层,和小尺度的卷积层组成的。全部都是以并行化的方式计算的,并且都是用1x1的卷积操作来减少维度的。由于这些模块,这个网络通过显著减少参数和操作的数量,特别考虑了内存和计算成本。
2.1.4 ResNet
微软发布的ResNet在ILSVRC-2016挑战赛中以96.4%的精确度尤其显著。除了这一事实,这个网络也由于其深度(152层)和引入的残差结构块(residual blocks)而著名,残差结构通过引入一致的跳跃连接从而能够很好的处理在真正深层结构训练时候的问题,这些跳跃的连接能够使这些层将输入直接拷贝到下一个层。
2.1.5 ReNet
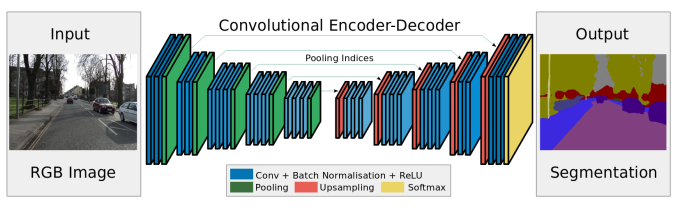
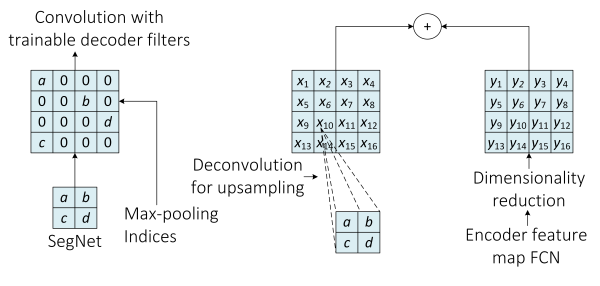
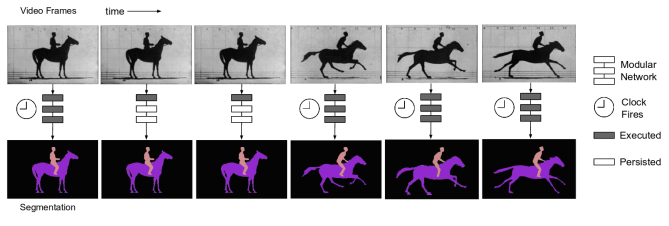
为了将循环神经网络结构(RNNs)扩展到多维任务,Graves提出了多维循环神经网络(MDRNN)架构,该网络将标准的RNNs中的每一个单独的循环连接替换成了d连接,其中d是时空数据的维度数。在这个最初的方法的基础上,Visin等人提出了ReNet结构,该网络中,他们利用常见的序列RNNs来替代多维RNNs。这样一来,每一层中RNNs的数量根据输入二维图像的维度数d进行线性扩增。按照这种方法,在图像中横向和纵向的扫描每一个维度,然后将每一个卷积层(卷积+池化)用4个RNNs替换.正如我们在图6中看到的那样。
2.2 迁移学习
从零开始训练一个深度神经网络不是容易的,其中会有各种各样的原因:需要一个数量足够大的数据集,达到收敛需要消耗很长时间。即使上述问题满足的情况下,使用一个预训练过的权重来代替随机初始化,也是对网络训练很有帮助的。通过继续训练过程来微调一个预训练过的网络权重,是一个主要的迁移学习方案。
Yosinski等人证实了,即使从远距离的任务迁移特征也是比随机初始化效果好的,已将考虑到随着预训练任务和目标任务之间的差异性增加,特征的迁移能力就会降低。
但是,使用这一迁移学习技术也不完全是简答的。一方面,结构约束上必须满足使用一个预训练的神经网络。然而,既然不是随意就能想出一个完整的全新架构的,但重用已经存在的网络结构(或者组件)还是很常见的,从而实现迁移学习。另一方面,从零开始训练的过程和微调的也只有一点点的不同。因此选择哪些层需要微调(通常是网络的一些high-level部分,因为低层部分往往包含更多普通的特征)并且选择合适策略来调整学习速率也是很重要的,学习速率通常是很斯奥的,因为预训练权重预计是相对好的,所以没有必要大幅度的改变他们。
由于收集和制作标签数据集固有难度,使得分割的数据库不像分类数据库(ImageNet)规模那么大,当处理的数据是RGB-D或者是三维图像的时候,这个问题会更加严重,数据库将会更小。由于这个原因,实际上从一个预训练过的分类网络上微调进行分割也是常见的趋势,而且已成功的应用在下列我们即将阐述的一些方法上。
2.3 数据预处理和数据增强
数据增强是一个常见的技术,而且已经被证明有利于机器模型和深度结构的学习。不管是在加速收敛或者作为一个正则化项,以此避免过拟合并且增加泛华能力。
通常包括一组在数据或者特征空间进行转换的应用。最常见的数据增强是在数据空间进行实现的。这种类型的增强产生通过对现有的数据进行转换产生新的样本,有很多转换功能可以应用:translation,旋转,扭曲变形 ,缩放,色彩空间转换,裁剪等等。这些转换的目标是产生更多的样本以制造一个更大的数据集、防止过拟合和规范化模型,平衡在该数据集内的类别,甚至综合产生更能代表手头工作的新样本。
数据增强对小数据集特别有用,并且很多成功的案例已经证实了其效率。例如,在[26]中,1500张人像的数据集通过数据增强综合处理4种新尺度,(0.6; 0.8; 1.2; 1.5),4种旋转角度(−45; −22; 22; 45)和4种伽马变量(0.6; 0.8; 1.2; 1.5)来产生一个包含19000张训练图像。这种扩增处理使得人像分割系统的在IoU上的指标从73.09上升到94.20。


























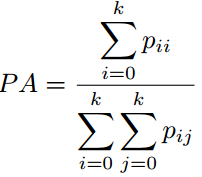
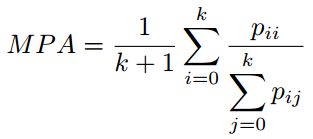
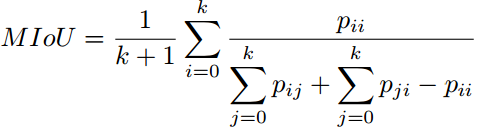
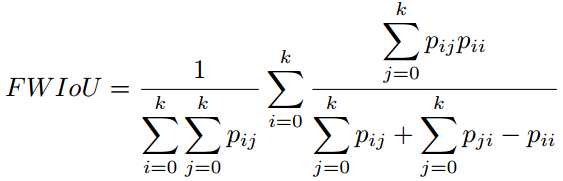

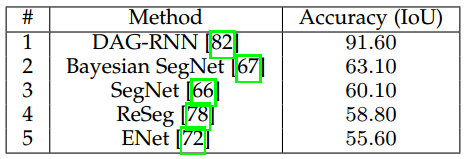
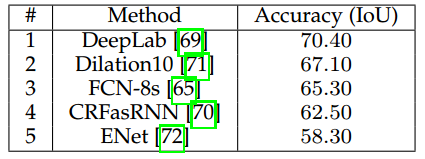
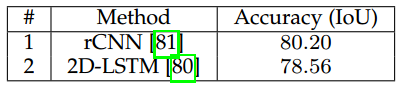
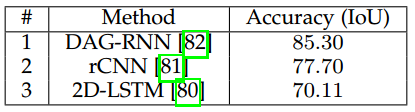







原文链接:http://blog.csdn.net/u011771047/article/details/72779221
http://blog.csdn.net/u014451076/article/details/71101850
https://www.cnblogs.com/Jie-Liang/archive/2017/06/29/6902375.html
摘要
图像语义分割越来越受到计算机视觉和机器学习的研究人员的热爱。越来越多新兴的应用领域需要精确地和高效的分割机制:自动驾驶,室内导航,甚至虚拟或增强现实系统等。这种需求几乎与计算机视觉等相关领域或应用目标(包括语义分割)的深度学习方法的兴起保持一致。本文对基于深度学习的语义分割在各个领域的应用做了综述。首先,描述了这个领域术语以及特定的背景概念。紧接着,罗列出主要的数据集和挑战,以便帮助研究人员决定哪些是最适合自己的需求和目标。然后,回顾现有的一些方法,突出的贡献以及在该领域的重要意义,最后,给出所述方法的量化结果和所用的数据集,以及对结果的一些论述,最终,我们指出了一系列有希望的future work,并使用深度学习技巧来得出state of the art关于语义分割的结论。
▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁
1.引言
如今,仍然在二维图像、视频甚至三维或者volumetric data(容积式的数据)上应用甚广的语义分割是计算机视觉领域的至关重要的问题之一。总体上来说,语义分割是一项高水平任务,这将为完成场景理解奠定基础。事实上,场景理解作为核心计算机视觉问题的重要性在于越来越多的应用程序从图像中进行推理。
其中一些应用包括自动驾驶[1] [2] [3],人机交互[4],计算机摄影 [5],图像搜索引擎 [6]和现实增强。过去使用各种传统计算机视觉和机器学习技术已经解决了这样的问题。尽管这样的方法得了普及,但深度学习革命已经扭转了整个形势,包括语义分割的很多计算机视觉问题都利用深层结构[7] [8] [9] [10] [11](通常为CNN)得到了解决,这些结构在精度甚至效率上都远远超过了其他一些方法。然而,深度学习所实现的成熟远不止计算机视觉和机器学习的其他老旧分支所达到的,因此,缺乏统一的作品和艺术评论(review)。不断发生变化现状使得发展难度很大,并且新文学产生量的增加,时刻跟进其演化的速度也是一项令人难以置信的耗时的工作。这使得很难跟踪处理语义分割的结果,并妥善解释他们的提案,修剪次要的方法和验证结果。
尽我们所知,这是第一篇对深度学习在语义分割上的清晰的评论。已经存在的诸多语义分割调查,比如[12][13],都在总结和分类现有的方法,讨论数据集和衡量标准并且对未来研究方向提出了设计选择上做了一项伟大的巨作。但是,他们缺少一些最新的数据集,他们没有分析框架,并且也没有提供深度学习技术的细节。因此,我们的工作是具有新颖有益的且对研究界将会有重大的贡献。
图1.目标识别和场景理解的演化过程,从粗粒度(coarse-grained)到细粒度(fine-grained)推理:分类,检测或者定位,语义分割,实例分割。
我们的工作的主要贡献在以下几点:
• 我们对现有的数据集进行了广泛的调查,这些数据集将会对深度学习技术的分割项目有益。
• 对那些用深度学习进行语义分割的重要方法进行深度的有组织的评论,包括他们的起源和贡献。
• 全面的性能评估,可以收集诸如准确性,执行时间和内存占用等量化指标。
• 对上述提到的结果进行论述,列出了即将到来的进展的未来可能作品,以及总结目前该领域的最高水平。
文章剩余部分按照以下结构进行组织:
首先,section 2介绍了语义分割的问题以及文学中常用的符号和惯例。对一些常见的深度网络的一些背景概念也进行了综述。然后,section 3详细描述了现有的数据集,挑战和基准。section 4 基于他们的贡献,依照自底向上的复杂性秩序进行了回顾。这一部分主要集中在描述这些方法的理论和突出贡献,而不是进行量化评估。最后,section 5对现有的方法在上述数据集上基于他们的量化结果进行了个简单的讨论,另外,也指出了未来的研究方向。section 6 对本文进行了对该领域最高水平的工作进行了总结并得出结论。
▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▇▆▅▃▂▁▁▂▃▅▆▇▆▅▃▂▁
2 专用术语和背景知识
为了正确的理解语义分割是如何通过近代深度神经结构进行处理的,重要的是知道深度神经网络并不是一个孤立的领域,而是在由粗到细推理过程中一个自然而然的步骤。
最初起源于分类任务,包括对整张输入图片的预测,比如预测一幅图像中包含的物体类别或者甚至提供一个排序列表,如果包含多个物体的话。定位或检测是继续进行fine-grained推理的下一步,不仅提供类别,并且根据这些类别的空间位置提供一些额外的信息,比如中心点或者边框。有了上述的推理,很明显,进行语义分割便是达到fine-grained推理的自然而然的步骤,目标:对每一个像素进行密度预测推理标签,这样的恶化,每一个像素便被标记为它封闭的目标或者区域的类别。可以进一步改进,比如实例分割(对同一类的不同实例物体单独标注)和基于部件的分割(对已经分割的物体进一步分解为他们所包含的部件)
图1 展示了上述提到了演变。本文我们将主要集中关注通常的场景标记,例如,每个像素的分割,但是我们依然会回顾在实例分割和基于部件分割的最重要的方法。
最后,像素标记问题可以简化为下列公式:从标签空间L到随机变量X,找到一种方法进行标记状态。L中每个标签l代表一个不同的类别或者目标,例如飞机,汽车,交通标志,或者背景。这些标签空间包含有k中可能的状态,通常被扩展为k+1种,其中l0作为背景或者空类。通常,X是一个包含WxH=N个像素x的二维图像。当然,这个随机变量序列可以被拓展为任意维度,比如容积数据或者高光谱图像。
除了将问题公式化外,重要的是remark一些背景概念,从而将对读者理解这篇论述文章有所帮助。首先,一些经常用于深度语义分割系统基础的常见的神经网络,方法,设计决策。另外,常用的训练技巧如迁移学习。最后数据预处理和数据增强等方法。
2.1 常见的深度神经网络架构
正如我们之前阐述的那样,一些深度神经网络已经在该领域做出了重要的贡献,并且也成为广为人知的标准。正如ALexNet,VGG-16,GoogleNet ,和ResNet,他们现在被用来作为很多分割系统的建设结构块,这些正是他们的重要性,因此,我们将会用整个部分来回顾他们。
2.1.1 AlexNet
AlexNet是最早的神经卷积神经网络(deep CNN),曾经在ILSVRC-2012比赛中以84.6%的top-5测试准确率取胜,而使用传统技术而不是深层架构的最直接的竞争对手在同样的挑战中的准确率为73.8%。这个Krizhevsky设计的结构是相对简单的,包括5个(卷积层,最大池化层,起非线性作用的ReLus线性修正单元),3个(全连接层,和dropout).图2展现了CNN架构。
2.1.2 VGG
Visual Geometry Group(VGG)是牛津大学VGG实验室推出的CNN模型,他们提出多种深度CNN模型和配置,其中一个提交在ILSVRC-2013上。这个模型,由于是由16个权重层组成的所以被称为VGG-16,以其92.7%的top-5准确率深受人们的欢迎。图3 展示了VGG-16的配置。和之前的主要不同是VGG-16在第一个层次使用了一系列小接受域的卷积层代替拥有较大感受域的较少层(减少感受野的大小,增大卷积层的数量)。这样导致较少的参数数量和更多的非线性,因此,使得决策函数更有区分能力,模型更容易训练。
2.1.3 GoogleNet
GoogleNet是Szegedy设计的一个神经网络,在ILSVRC-2014挑战赛中以93.3%的top-5准确率赢得比赛。这个CNN结构的特征主要是他的复杂性,主要体现在它是由22层和一个新引进的inception(见图4)的建设结构块组成。这种新的方法证实了神经网络网络层是可以以多种方式堆叠的,而不单是一种传统的顺序方式。事实上,这些模型都是由NiN 层,池化操作,大尺度的卷积层,和小尺度的卷积层组成的。全部都是以并行化的方式计算的,并且都是用1x1的卷积操作来减少维度的。由于这些模块,这个网络通过显著减少参数和操作的数量,特别考虑了内存和计算成本。
2.1.4 ResNet
微软发布的ResNet在ILSVRC-2016挑战赛中以96.4%的精确度尤其显著。除了这一事实,这个网络也由于其深度(152层)和引入的残差结构块(residual blocks)而著名,残差结构通过引入一致的跳跃连接从而能够很好的处理在真正深层结构训练时候的问题,这些跳跃的连接能够使这些层将输入直接拷贝到下一个层。
2.1.5 ReNet
为了将循环神经网络结构(RNNs)扩展到多维任务,Graves提出了多维循环神经网络(MDRNN)架构,该网络将标准的RNNs中的每一个单独的循环连接替换成了d连接,其中d是时空数据的维度数。在这个最初的方法的基础上,Visin等人提出了ReNet结构,该网络中,他们利用常见的序列RNNs来替代多维RNNs。这样一来,每一层中RNNs的数量根据输入二维图像的维度数d进行线性扩增。按照这种方法,在图像中横向和纵向的扫描每一个维度,然后将每一个卷积层(卷积+池化)用4个RNNs替换.正如我们在图6中看到的那样。
2.2 迁移学习
从零开始训练一个深度神经网络不是容易的,其中会有各种各样的原因:需要一个数量足够大的数据集,达到收敛需要消耗很长时间。即使上述问题满足的情况下,使用一个预训练过的权重来代替随机初始化,也是对网络训练很有帮助的。通过继续训练过程来微调一个预训练过的网络权重,是一个主要的迁移学习方案。
Yosinski等人证实了,即使从远距离的任务迁移特征也是比随机初始化效果好的,已将考虑到随着预训练任务和目标任务之间的差异性增加,特征的迁移能力就会降低。
但是,使用这一迁移学习技术也不完全是简答的。一方面,结构约束上必须满足使用一个预训练的神经网络。然而,既然不是随意就能想出一个完整的全新架构的,但重用已经存在的网络结构(或者组件)还是很常见的,从而实现迁移学习。另一方面,从零开始训练的过程和微调的也只有一点点的不同。因此选择哪些层需要微调(通常是网络的一些high-level部分,因为低层部分往往包含更多普通的特征)并且选择合适策略来调整学习速率也是很重要的,学习速率通常是很斯奥的,因为预训练权重预计是相对好的,所以没有必要大幅度的改变他们。
由于收集和制作标签数据集固有难度,使得分割的数据库不像分类数据库(ImageNet)规模那么大,当处理的数据是RGB-D或者是三维图像的时候,这个问题会更加严重,数据库将会更小。由于这个原因,实际上从一个预训练过的分类网络上微调进行分割也是常见的趋势,而且已成功的应用在下列我们即将阐述的一些方法上。
2.3 数据预处理和数据增强
数据增强是一个常见的技术,而且已经被证明有利于机器模型和深度结构的学习。不管是在加速收敛或者作为一个正则化项,以此避免过拟合并且增加泛华能力。
通常包括一组在数据或者特征空间进行转换的应用。最常见的数据增强是在数据空间进行实现的。这种类型的增强产生通过对现有的数据进行转换产生新的样本,有很多转换功能可以应用:translation,旋转,扭曲变形 ,缩放,色彩空间转换,裁剪等等。这些转换的目标是产生更多的样本以制造一个更大的数据集、防止过拟合和规范化模型,平衡在该数据集内的类别,甚至综合产生更能代表手头工作的新样本。
数据增强对小数据集特别有用,并且很多成功的案例已经证实了其效率。例如,在[26]中,1500张人像的数据集通过数据增强综合处理4种新尺度,(0.6; 0.8; 1.2; 1.5),4种旋转角度(−45; −22; 22; 45)和4种伽马变量(0.6; 0.8; 1.2; 1.5)来产生一个包含19000张训练图像。这种扩增处理使得人像分割系统的在IoU上的指标从73.09上升到94.20。