1 摘要
-
There are two key observations on user behavior data: i) diversity. Users are interested in di↵erent kinds of goods when visiting e-commerce site. ii) local activation. Whether users click or not click a good depends only on part of their related historical behavior.
关于用户行为数据有两个主要观察结果:i)多样性。用户在访问电子商务网站时会对各种商品感兴趣。 ii)本地激活。用户是否点击商品仅取决于其相关历史行为的一部分。 -
DIN represents users’ diverse interests with an interest distribution and designs an attention-like network structure to locally activate the related interests according to the candidate ad
DIN 通过兴趣分布来表示用户的各种兴趣,并设计一种类似于注意力的网络结构,根据候选广告在本地激活相关兴趣 -
propose a useful adaptive regularization technique.
提出一种有用的自适应正则化技术。
2 介绍
-
Diversity. Users are interested in di↵erent kinds of goods when visiting e-commerce site. For example, a young mother may be interested in T-shits, leather handbag, shoes, earrings, children’s coat, etc at the same time.
多样性:用户在访问电子商务网站时对不同种类的商品感兴趣。例如,年轻的母亲可能会同时对 T恤、皮包、鞋子、耳环、儿童外套等感兴趣。 -
Local activation. Due to the diversity of users’ interests, only a part of users’ historical behavior contribute to each click. For example, a swimmer will click a recommended goggle mostly due to the bought of bathing suit while not the books in her last week’s shopping list
局部激活:由于用户兴趣的多样性,每次点击只有一部分用户的历史行为起作用。例如,游泳运动员会点击推荐的护目镜,这主要是因为她买了泳衣,而不是上周购物清单上的书 -
Experimentally we show with addition of fine-grained user behavior feature (e.g., good id), the deep network models easily fall into the overfitting trap and cause the model performance to drop rapidly
实验表明,通过添加细粒度的用户行为特征(例如,良好的ID),深度网络模型很容易掉入过度拟合陷阱,并导致模型性能迅速下降
3 相关工作
-
it’s worth mentioning that for CTR prediction tasks with user behavior data, features are ofter contained with multi-hot sparse
值得一提的是,对于具有用户行为数据的点击率预测任务,功能通常包含在多键稀疏中 -
These models often add a pooling layer after embedding layer, with operations like sum or average, to get a fixed size embedding vector. This will cause loss of information and can’t take full advantage of inner structure of user rich behavior data.
这些模型通常在嵌入层之后添加一个池化层,并使用求和或平均等操作来获得固定大小的嵌入向量。 这将导致信息丢失,并且无法充分利用用户丰富的行为数据的内部结构。
4 MODEL ARCHITECTURE
4.1 基本模型
- the input contains user behavior sequence ids, of which the length can be various. we add a pooling layer (e.g. sum operation) to summarize the sequence and get a fixed size vector. However, going deep into the pooling operation, we will find that much information is lost, that is, it destroys the inner structure of user behavior data. This observation inspires us to design a better model.
输入内容包含用户行为序列ID,其长度可以不同。我们添加一个池化层(例如求和运算)以总结序列并获得固定大小的向量。但是,深入到池化操作中,我们会发现很多信息丢失了,也就是说,它破坏了用户行为数据的内部结构。 这种观察启发我们设计出更好的模型。
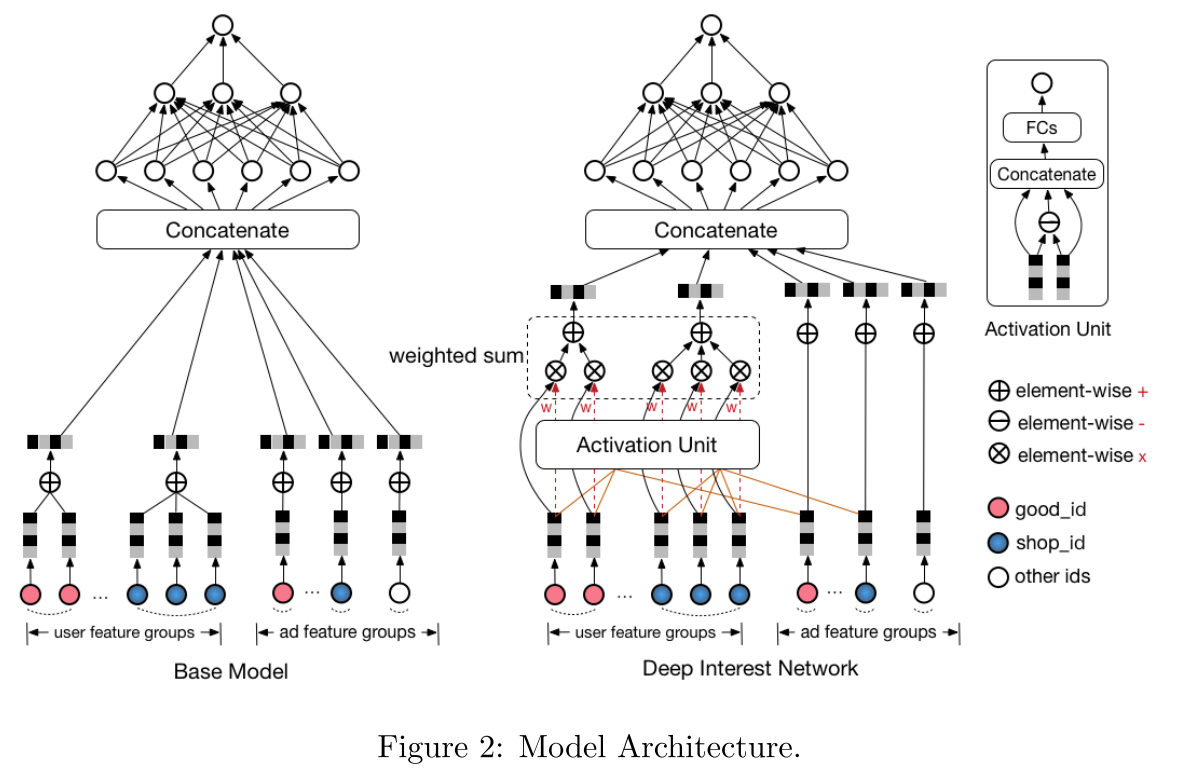
4.2 Deep Interest Network Design
-
User click of ad often originates from just part of user’s interests. We find it is similar to the attention mechanism
-
w i w_i wi is the attention score that the behavior id i i i contributes to the overall user interest embedding vector V u V_u Vu with respect to the candidate ad A. In our implementation, w i w_i wi is the output of activation unit.
-
a novel data dependent activation function, which we name it Dice:
y i = a i ( 1 − p i ) y i + p i y i p i = 1 1 + e − y i − E [ y i ] V a r [ y i ] + ϵ (1) \begin{aligned} y_{i} &=a_{i}\left(1-p_{i}\right) y_{i}+p_{i} y_{i} \\ p_{i} &=\frac{1}{1+e^{-\frac{y_{i}-E\left[y_{i}\right]}{\sqrt{V a r\left[y_{i}\right]+\epsilon}}}} \end{aligned} \tag{1} yipi=ai(1−pi)yi+piyi=1+e−Var[yi]+ϵyi−E[yi]1(1) The key idea of Dice is to adaptively adjust the rectifier point according to data
5 结果
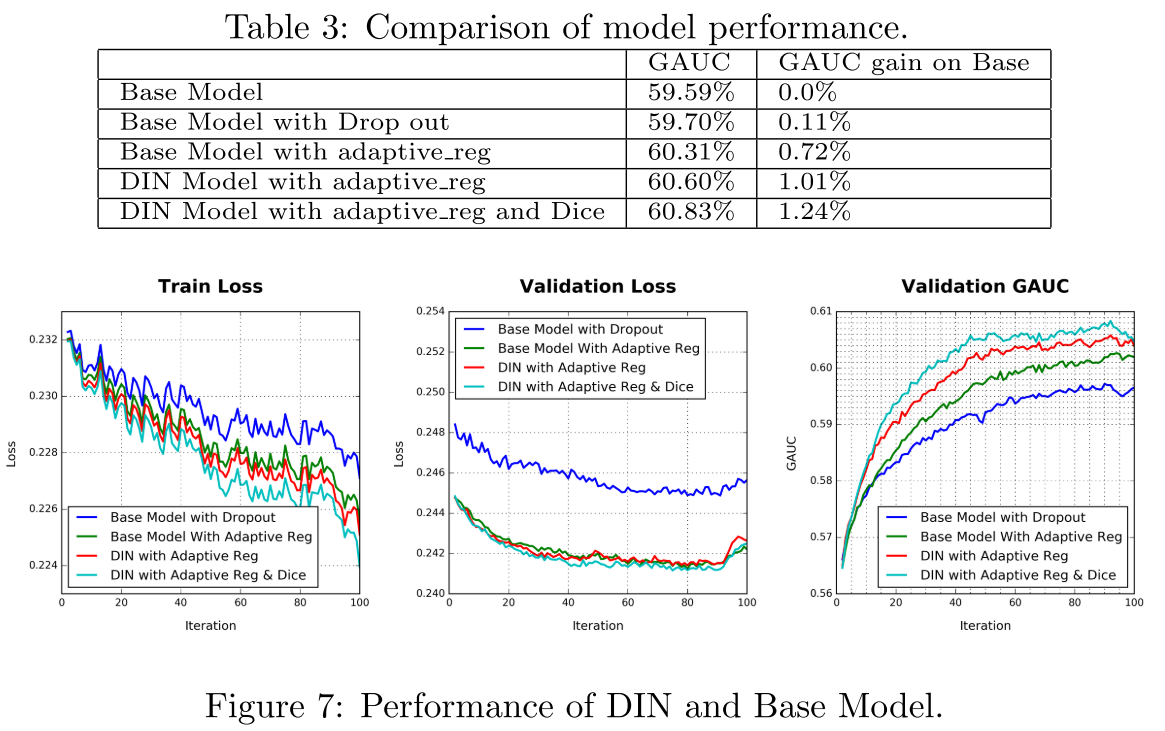
6 总结
- We reveal and summarize the two key structures of data: diversity and local activation and design a novel model named DIN with better exploitation of data structures.
我们揭示并总结了数据的两个关键结构:多样性和局部激活,并设计了一种名为DIN的新型模型,可以更好地利用数据结构。