利用python爬虫抓取B站视频弹幕数据保存到txt,并绘制词云。
视频链接:https://www.bilibili.com/video/BV1zE411Y7JY
1. 网页分析
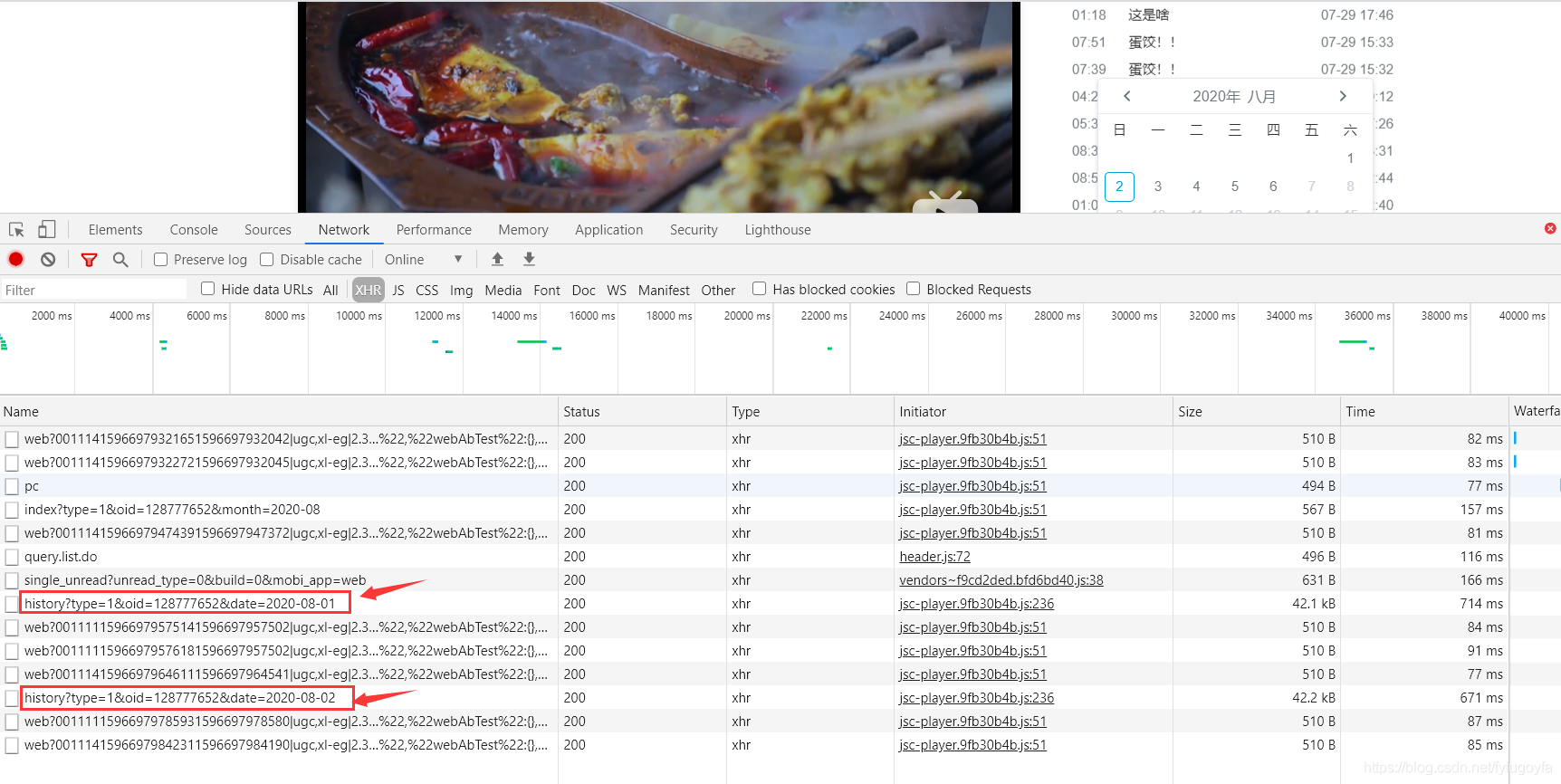
点击弹幕列表,查看历史弹幕,并选择任意一天的历史弹幕,此时就能找到存储该日期弹幕的ajax数据包,所有弹幕数据放在一个i标签里。
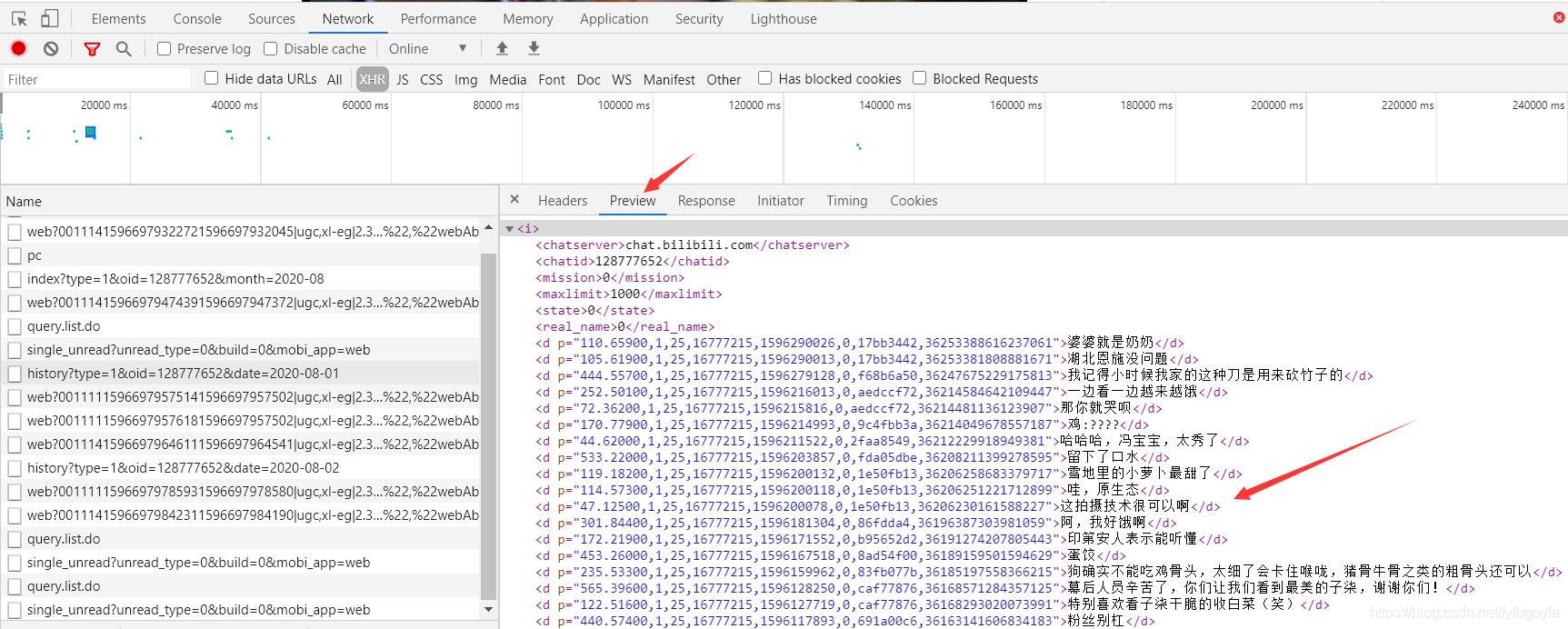
查看请求的相关信息
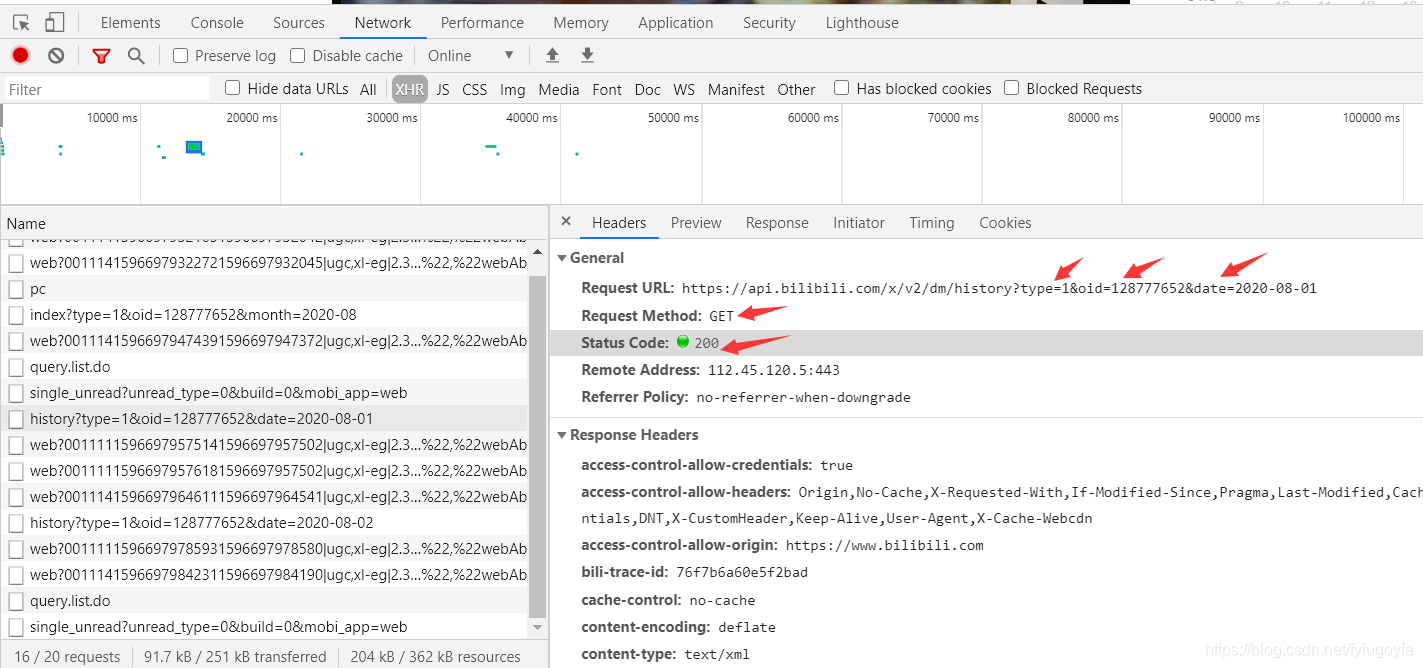
可以发现Request URL关键就是 oid 和 date 两个参数,date很明显是日期,换日期可以实现翻页爬取弹幕,oid应该是视频标识之类的东西,换个oid可以访问其他视频弹幕页面。
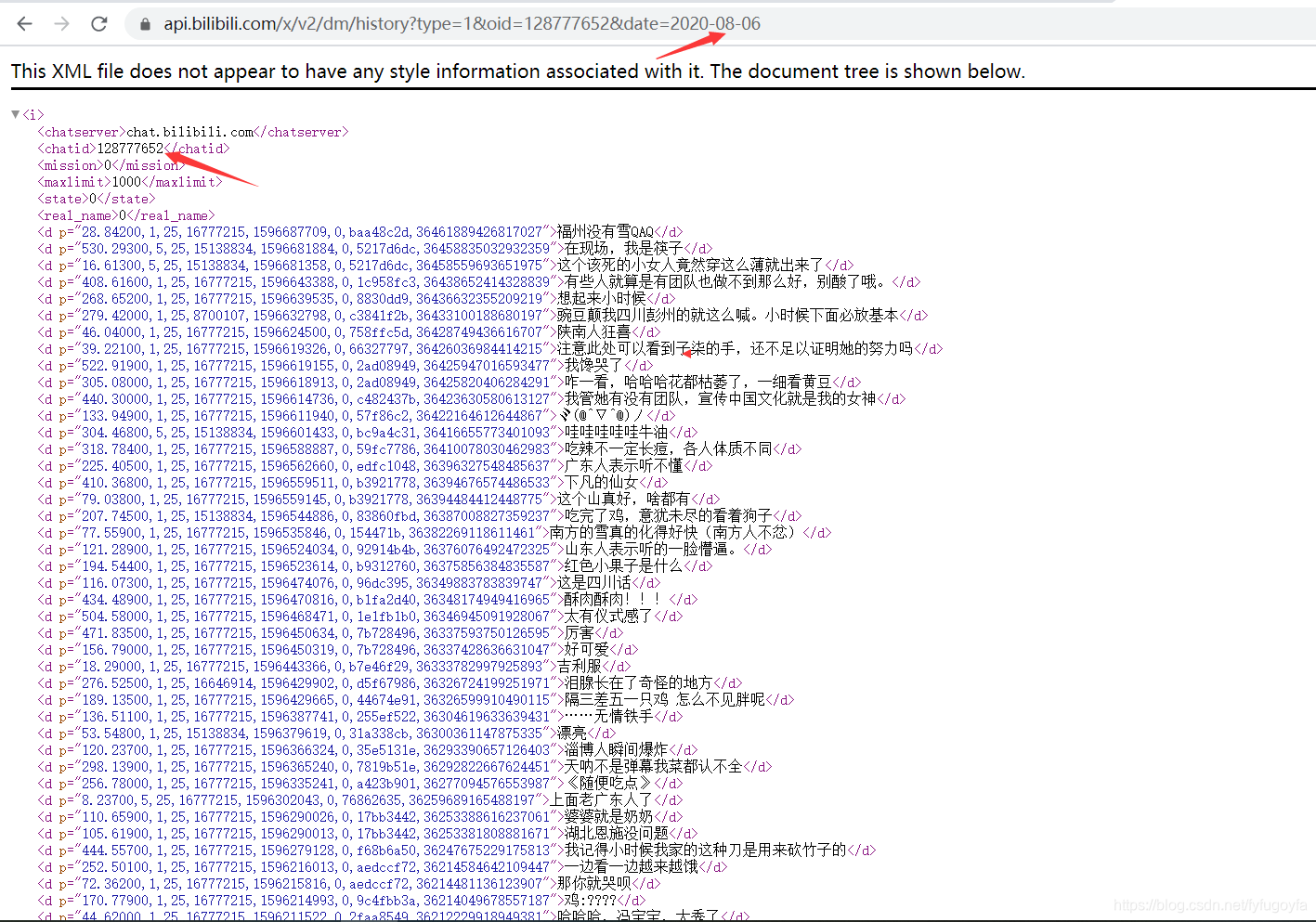
2. 爬取弹幕
本文爬取该视频1月1日到今天8月6日的历史弹幕数据,构造出时间序列:
import pandas as pd
start = '20200101'
end = '20200806'
# 生成时间序列
date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')]
print(date_list)
运行结果如下:
['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05', '2020-01-06', ... '2020-08-06']
Process finished with exit code 0
爬虫代码如下:
import requests
import pandas as pd
import re
import time
import random
from concurrent.futures import ThreadPoolExecutor
import datetime
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
start_time = datetime.datetime.now()
def Grab_barrage(date):
headers = {
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"origin": "https://www.bilibili.com",
"referer": "https://www.bilibili.com/video/BV1Z5411Y7or?from=search&seid=8575656932289970537",
"cookie": "_uuid=0EBFC9C8-19C3-66CC-4C2B-6A5D8003261093748infoc; buvid3=4169BA78-DEBD-44E2-9780-B790212CCE76155837infoc; sid=ae7q4ujj; DedeUserID=501048197; DedeUserID__ckMd5=1d04317f8f8f1021; SESSDATA=e05321c1%2C1607514515%2C52633*61; bili_jct=98edef7bf9e5f2af6fb39b7f5140474a; CURRENT_FNVAL=16; rpdid=|(JJmlY|YukR0J'ulmumY~u~m; LIVE_BUVID=AUTO4315952457375679; CURRENT_QUALITY=80; bp_video_offset_501048197=417696779406748720; bp_t_offset_501048197=417696779406748720; PVID=2",
"user-agent": random.choice(user_agent),
}
params = {
'type': 1,
'oid': '128777652',
'date': date
}
response = requests.get(url, params=params, headers=headers)
# print(response.encoding)
response.encoding = 'utf-8'
# print(response.text)
comment = re.findall('<d p=".*?">(.*?)</d>', response.text)
# print(comment)
with open('barrages.txt', 'a+') as f:
for con in comment:
f.write(con + '\n')
time.sleep(random.randint(1, 3))
def main():
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(Grab_barrage, date_list)
delta = (datetime.datetime.now() - start_time).total_seconds()
print(f'用时:{delta}s')
if __name__ == '__main__':
url = "https://api.bilibili.com/x/v2/dm/history"
start = '20200101'
end = '20200806'
# 生成时间序列
date_list = [x for x in pd.date_range(start, end).strftime('%Y-%m-%d')]
count = 0
main()
程序运行,成功爬取下弹幕数据并保存到txt。
用时:32.040222s
Process finished with exit code 0
3. 绘制词云图
读取txt中弹幕数据
扫描二维码关注公众号,回复:
11577918 查看本文章

with open('barrages.txt') as f:
data = f.readlines()
print(f'弹幕数据:{len(data)}条')
运行结果如下:
弹幕数据:52708条
Process finished with exit code 0
词云展示
import jieba
import collections
import re
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
with open('barrages.txt') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S) # 只要字符串中的中文
new_data = " ".join(new_data)
# 文本分词--精确模式分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# 筛选后统计
word_counts = collections.Counter(result_list)
# 获取前100最高频的词
word_counts_top100 = word_counts.most_common(100)
# 可以打印出来看看统计的词频
print(word_counts_top100)
word1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px', theme=ThemeType.MACARONS))
word1.add('词频', data_pair=word_counts_top100,
word_size_range=[15, 108], textstyle_opts=opts.TextStyleOpts(font_family='cursive'),
shape=SymbolType.DIAMOND)
word1.set_global_opts(title_opts=opts.TitleOpts('弹幕词云图'),
toolbox_opts=opts.ToolboxOpts(is_show=True, orient='vertical'),
tooltip_opts=opts.TooltipOpts(is_show=True, background_color='red', border_color='yellow'))
# 渲染在html页面上
word1.render("弹幕词云图.html")
运行效果如下:
