前言
最近有 CVTE 的面试但是一直没有到我,昨天下午牛客网上 CVTE 前端的面经突然多了起来,大致看了一下,和自己之前整理的知识点差的不多,但是基本都问了 nodejs 的问题。正好之前的爬虫都没有做过词云,借着这个机会爬一下牛客网的前端面经,顺便生成词云,看看面试中哪些比较重要
准备工作
基本的步骤前面几篇爬虫都有了,不过还是重写写一下吧。
- 创建一个文件夹,我这里叫 spider
- 右键点击这个文件夹,有个 CMD 快速通道,点击打开 CMD
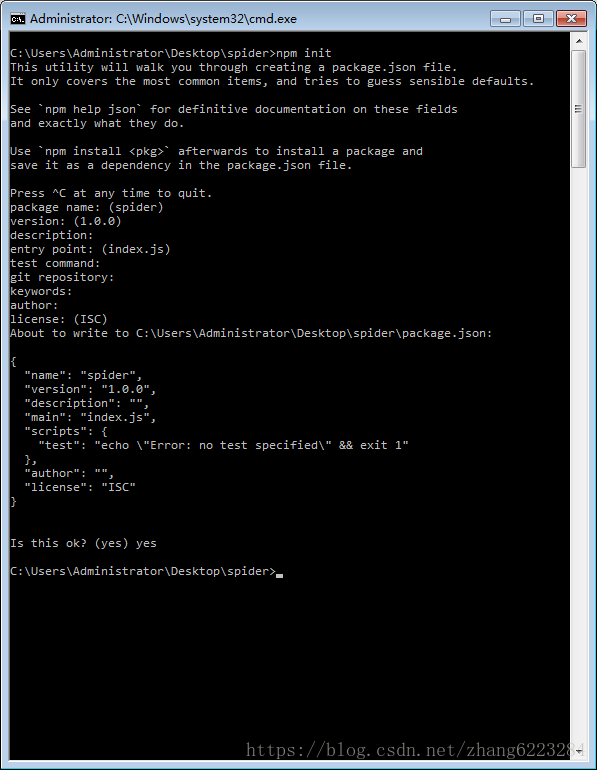
- 执行
npm init命令,一路回车,最后 yes
运行完以后,会多出一个 package.json 的文件夹,里面放的是一些项目的信息 - 在 spider 文件夹下新建一个 index.js 文件用来写我们的代码。
- 创建一个 data 文件夹用于放我们所需要的数据
- 安装项目所需要的依赖包
npm istall cheerio --save这个是用来提取 html 页面内容的
npm istall async --save这个是用来异步并发爬虫的
npm istall node-gyp --save这个用于编译原生C++扩展模块
npm istall nodejieba --save这个是用来分词的
其中安装的时候有点小坑,需要有VC++库、python库,可以参考这篇文章 nodejieba安装记(Windows)
网页结构分析
基本的准备工作做完了,下面开始分析牛客网的网页,其实没什么难的,很容易分析出来我们需要的网页在这
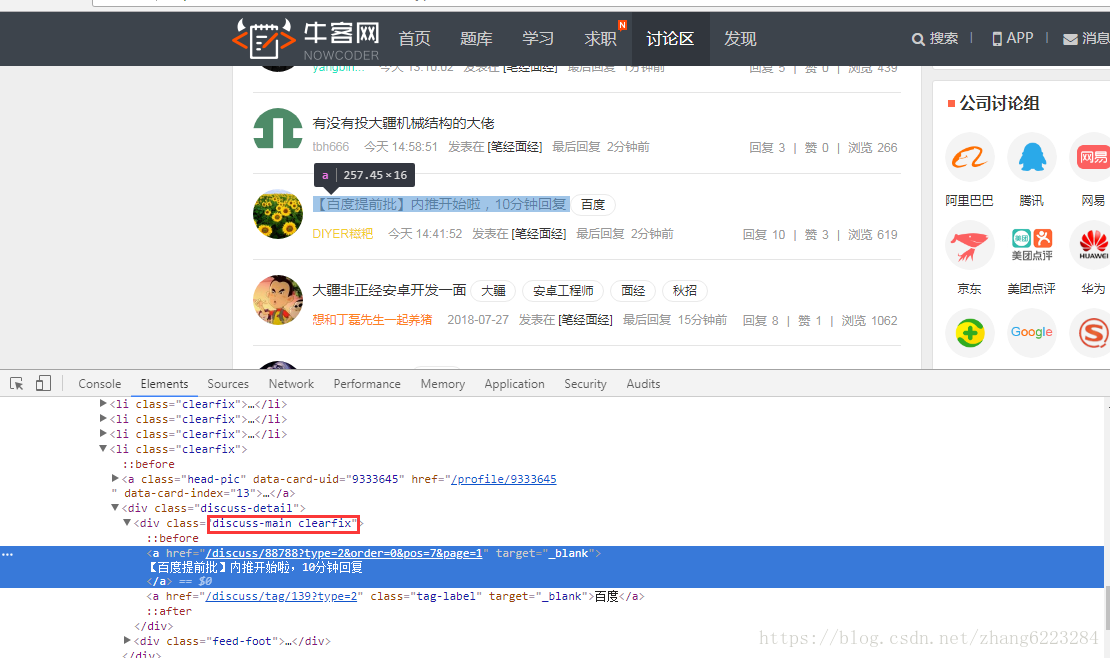
即类名为 discuss-main 和 clearfix 下面的第一个 <a> 元素。代码如下
$('li .discuss-main.clearfix').each(function(){
var title=$(this).children().first().text();
// 这里是为了根据关键词查询,如果标题有我们设置的关键词,再把链接放到数组中
if(title.indexOf(keyWord)>=0){
var search=$(this).children().first().attr('href');
let nextLink = "https://www.nowcoder.com" + search;
urlList.push(nextLink);
}
})接下来就是页面里面的实际内容,也很容易分析
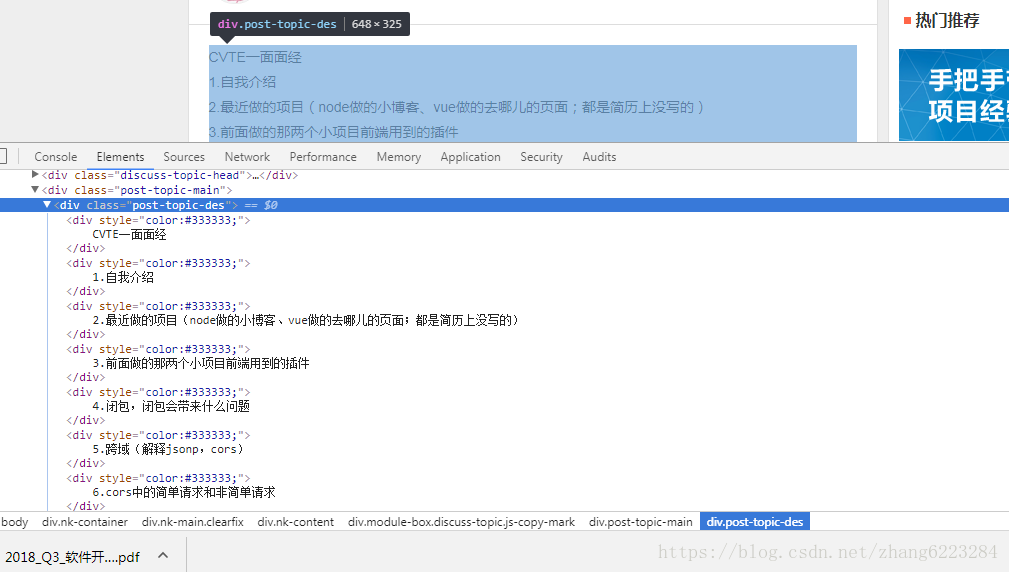
即类名为 post-topic-des 下的文本
至此页面分析工作做完,接下来就是使用 nodejieba 模块来分词
分词生成词云
关于 nodejieba 的用法可以参考这篇文章 使用 Node.js 对文本内容分词和关键词抽取
由于 const result = nodejieba.extract(data, 40); 得到的结果是对象,所以写入文件之前需要将其转换为 JSON 字符串,用 JSON.stringify(result)。然后对字符串进行处理
代码如下
function wordCluod(){
fs.readFile('./data/word.txt', 'utf8', function(err, data){
nodejieba.load({
userDict: './user.utf8',
});
const result = nodejieba.extract(data, 20);
let text = "";
for(let i in result){
text += text[i].word + " " + Math.ceil(text[i].weight) + "\n";
}
fs.writeFile('./data/'+'wordCloud'+'.txt',text, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
});
}但是这样有一个问题,因为他是根据词频选取的,所以有一些没用的词比如面试官,一面等词语就会混入到我们的词中,所以我们需要将有用的信息过滤出来
const tagList = ['原型', '闭包', 'HTTP', 'CORP', 'TCP', 'https','跨域','XSS','安全','事件','VUE','CSS','算法','线程','NODE'];
let textNo = JSON.stringify(result.filter(item => tagList.indexOf(item.word.toUpperCase()) >= 0)); 生成数据如下
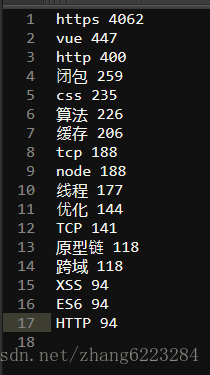
和我想象的还是有些差距的,可能程序并不是太完善,然后就可以把数据导入到任何一个在线词云里面了
完整代码
const https=require('https');
const fs=require('fs');
const request=require('request');
const async=require('async');
const cheerio = require('cheerio');
const nodejieba = require('nodejieba');
const startPage =0;//开始页
const endPage = 4;//结束页
const keyWord = "";//关键词
const keyWord2 = "前端";
let page=startPage;
let i=0;
//初始url
const url={
hostname: 'www.nowcoder.com',
path: '/discuss?type=2&order=' + startPage,
headers: {
'Content-Type': 'text/html',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',
}
}
let urlList=[];//存储图片页面地址
//获取图片所在页面
function getUrl(url){
//采用http模块向服务器发起一次get请求
https.get(url,function(res){
var html='';
//res.setEncoding('binary');
//监听data事件,每次取一块数据
res.on('data',function(chunk){
html+=chunk;
});
res.on('end',function(){
var $ = cheerio.load(html); //采用cheerio模块解析html
$('li .discuss-main.clearfix').each(function(){
var title=$(this).children().first().text();
if(title.indexOf(keyWord2)>=0){
var search=$(this).children().first().attr('href');
//console.log(search);
let nextLink = "https://www.nowcoder.com" + search;
urlList.push(nextLink);
}
})
page++;
if(page<=endPage){
let tempUrl='https://www.nowcoder.com/discuss?type=2&order=' + page;
getUrl(tempUrl);
}else{
fetchPage();
}
})
}).on('err',function(err){
console.log(err);
})
}
function fetchPage(){
//异步控制并发
async.mapLimit(urlList,5,function(url,callback){
https.get(url,function(res){
//console.log(url);
let html='';
//res.setEncoding('binary');
res.on('data',function(chunk){
html+=chunk;
})
res.on('end',function(){
//console.log(html);
var $ = cheerio.load(html); //采用cheerio模块解析html
var content = $('.post-topic-des').text().trim();
//console.log(content);
appendText(content);
})
}).on('err',function(err){
console.log(err);
});
callback(null,'成功');
},
function(err,result){
if (err){
console.log(err)
}
else{
console.log('结束');
wordCluod();
}
})
}
function appendText(text){
fs.appendFile('./data/word.txt', text, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
}
// 生成词云数据
function wordCluod(){
fs.readFile('./data/word.txt', 'utf8', function(err, data){
nodejieba.load({
userDict: './user.utf8',
});
const result = nodejieba.extract(data, 120);
const tagList = ['原型', '闭包', 'HTTP', 'CORP', 'TCP', 'HTTPS','跨域','XSS','安全','事件循环','VUE','CSS','算法','线程','NODE','','缓存','内存','作用域链','垂直居中','布局','状态码','原型链','ES6','箭头函数',"PROMISE",'垃圾回收','优化'];
let textNo = JSON.stringify(result.filter(item => tagList.indexOf(item.word.toUpperCase()) >= 0));
let text = JSON.parse(textNo);
let temp = "";
for(let i in text){
temp += text[i].word + " " + Math.ceil(text[i].weight) + "\n";
}
fs.writeFile('./data/'+'wordCloud'+'.txt',temp, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
});
}
getUrl(url);//主程序开始运行效果图
最终效果如图所示
