前言: 因为一些项目需要使用到yolov3,为了能深刻的理解yolov3算法,因而翻译了yolo系列论文。
You Only Look Once:Unified, Real-Time Object Detection
摘要
我们提出了一种新的目标检测算法:yolo。先前通过再使用一个分类器实现目标检测,而本文则把目标检测问题看作回归问题,直接预测目标是什么以及目标所在位置(bounding boxes)。一个神经网络通过浏览整张图片,可以直接在一次检测中预测目标是什么以及目标的位置。由于整个检测过程只有一个神经网络,因而可以通过端到端的方法直接优化检测性能。
这种检测结构的速度非常快。本文基础的YOLO模型可以每秒实时监测45张图片。一个结构上较小版本的神经网络, fast yolo,则能够达到惊人的每秒155帧,同时其mAP检测精度也能够达到其他实时检测算法的两倍。与其他顶级的检测系统相比较,YOLO有较多的定位误差,不过在背景上检测到假阳性的目标次数却并不多。最后,YOLO能够学到目标抽象和泛化的特征,因而当把一张自然图片泛化到其他领域(如艺术)时,YOLO比其他的一些检测方法(包括DPM和R-CNN)更优秀。
1 介绍
人类只需要扫一眼图片立马就知道了图片中的物体是什么,它们在哪里以及它们在干什么。人类的视觉系统非常快而且非常准确,因而允许我们完成一些比较复杂的工作(比如自动驾驶)。快速准确的目标识别算法能够允许计算机不需要一些专用传感器而实现自动驾驶,能够确保辅助装置把实时的场景信息传递给人类使用者,同时也打开了实现通用快速响应的机器人操作系统的这种可能。
当前的目标检测算法主要使用分类器用于目标检测。To detect an object, these systems take a classifier for that object and evaluate it at various locations and scales in a test image. Systems like deformable parts models (DPM) use a sliding window approach where the classifier is run at evenly spaced locations over the entire image .
当前大部分的方法如R-CNN,一般首先使用region proposal 生成潜在可能的bounding boxes,然后再对这些精心挑选出来的boxes进行分类;最后进一步的精修bounding boxed消除重复检测区域,同时基于场景内的目标给boxes打分。因而基于上述的这些复杂处理流程,目标识别起来特别的慢;而且很难优化因为每一个独立的环节都需要进行单独的训练。

Figure 1: The YOLO Detection System. Processing images with YOLO is simple and straightforward.
1.检测系统把输入图片reshape为448*448;
2.使用单独的一个卷积神经网络处理图片;
3.根据模型的置信度进行阀值处理检测结果;
我们把目标检测问题视作一个回归问题,因而直接基于图片的像素预测出目标的bounding box坐标以及目标类别。基于本文的识别系统,我们只需要看一次图片就能预测到物体是什么以及它们在哪里?

YOLO的结构非常简单,如见图1。一个单独的卷积神经网络即能够同时预测多个bounding boxes以及这些boxes的类别概率。YOLO以整张图片进行训练,所以能够直接优化检测的性能。这种统一的模型相比较传统的目标检测方法具有很多的优点。
首先,YOLO非常的快。由于本文把目标检测视作回归问题因而不需要很复杂的处理流程,所以速度比较快。在测试目标识别时,我们只需要给我们的神经网络一张图片即可。我们的基础神经网络在Tian X GPU 能够达到45帧每秒,而快速版本的可以达到150帧每秒。这意味着我们能够以低于25毫秒的延迟实时处理stream video。此外,YOLO的mean average precision大概是其他实时检测精度的两倍。关于我们的系统在网络摄像头上实时运行的演示,请参阅我们的项目网页:http://pjreddie.com/yolo/。
第二, YOLO reasons globally about the image when making predictions. 不同于滑窗法或者是基于region proposal 技术,YOLO无论是在训练还是测试的时候看到的都是一整张照片,因而它隐式地编码了关于类的上下文信息以及它们的外观。 Fast R-CNN, 一种顶级的目标检测方法,有时会把背景块误判为目标就是因为它看不到较大的这种上下文关系。不过与快速R-CNN相比较,YOLO的背景误检数量少了一半。
第三,YOLO可以学到目标的抽象特征。当使用一般自然图像进行训练并在艺术作品上进行测试,YOLO比其他的一些顶级目标检测方法比如DPM和R-CNN表现的更为优异。由于YOLO具有高度泛化能力,因此在应用于新领域或碰到意外的输入时出问题的可能比较小。
不过YOLO在精度上还是比一些顶级的目标检测系统还是差一点。尽管YOLO能够快速的识别图像中的物体,但是YOLO还需要努力改善目标的定位精度问题,特别是一些小目标。我们正在实验并努力找到速度和精度的平衡。此外,所有训练和测试程序都是开源的,各种经预训练的模型也都可以使用和下载。
2 统一检测
我们把原目标检测所使用的各个部分统一为一个单独的神经网络,并以整张图片作为特征预测出所有的bounding boxes,同时预测出bounding boxex框选区域所属的物种类别。The YOLO design enables end-to-end training and realtime speeds while maintaining high average precision. 我们的检测系统把输入图片划分为S*S的网格. 如果某个对象的中心落入到某个方格内,那么这个方格就对这个检测目标负责。
每个grid cell 负责预测B个bounding boxes 以及它们的confidence 分数。These confidence scores reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts.Formally we define confidence as ![]() . 如果cell中没有物体,那么confidence即为零。Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth.
. 如果cell中没有物体,那么confidence即为零。Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth.
每个bounding box包含了5个预测值:x,y,w,h和confidence。The (x,y) coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. 最后预测的confidence代表了 预测box与实际的box之间的IOU。
每个grid cell预测了C个条件概率, Pr(Class i |Object). These probabilities are conditioned on the grid cell containing an object. 每一个grid cell 只预测一组条件概率值,而不管有多少个boxes。
在测试的时候,使用条件概率分别乘以每个boxes的confidence,则得到了每个box在每个类别上的得分。

这些得分代表了每个类别出现在box中的概率和预测的box同目标对象的契合程度。

图2:模型。我们的模型把目标检测视作回归问题。它把输入图像分为 S ×S 方格,并且每个方格预测B个bounding boses,这些bounding boxes的confidence,以及C个类别的概率。这些预测值被编码为S × S × (B ∗ 5 + C) 张量.
当在PASCAL VOC上评估YOLO时,我们令S=7,B=2。PASCAL VOC有20个类别的对象,所以C=20。因此,我们最终的预测输出是一个 7 × 7 × 30 张量。
2.1 网络设计
我们使用卷积神经网络实现我们的模型,并且在PASCAL VOC数据集上进行评估。前面的卷积层提取图像中的特征,而全连接层则预测输出的概率和坐标。
我们神经网络的结构受到了GoogleNet的启发。本文的神经网络有24个卷积层以及接下来的2个全连接层,不过并没有使用GoogleNet的inception 模块,我们的神经网络仅仅在3×3的卷积层后面使用了 1×1 卷积层进行降维。整个神经网络如图3所示。

图3: 结构. 我们的神经网络含有24个卷积层,2个全连接层。选择使用1 × 1的卷积层降低特征空间的维度。我们在ImageNet 上预训练卷积层,并令输入图片的分辨率为(224 × 224);不过当进行检测时,将恢复分辨率为448 × 448。
The final output of our network is the 7 × 7 × 30 tensor of predictions.
We also train a fast version of YOLO designed to push the boundaries of fast object detection. fast YOLO 使用较少的卷积层,9层而不是普通版的24层,和更小的卷积核。除了网络较小,Fast YOLO和YOLO训练和测试参数是一样的。我们的网络最终输出是7 × 7 × 30的预测张量。
2.2 训练
我们在含有1000个种类的ImageNet数据集上预训练卷积层。在预训练阶段,我们使用了如图3所示的20个卷积层,然后一个平均池化层和一个全连接层。 We train this network for approximately a week and achieve a single crop top-5 accuracy of 88% on the ImageNet 2012 validation set, comparable to the GoogLeNet models in Caffe’s Model Zoo . 我们使用了Darknet深度学习框架进行训练和前向传播。
然后使用这个模型进行检测。Ren等人证明当adding both convolutional and connected layers to pretrained networks can improve performance. 因而按照他们的例子,我们添加了四个卷积层和两个全连接层,并且使用随机的方法初始化权重。 此外由于检测通常需要 fine-grained 视觉信息,因此我们把输入图片的分辨率从224 × 224 提高到 448 × 448。
Our final layer predicts both class probabilities and bounding box coordinates. We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1. We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
我们在最后一层使用了线性激活函数,其他所有层则使用下面的leaky rectified linear 激活函数:
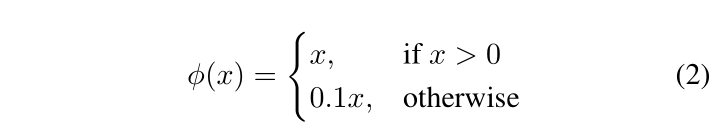
We optimize for sum-squared error in the output of our model. 使用平均和误差作为代价函数是因为它比较容易优化, 但是它并不完全符合我们优化最大平均精度的目标。另外,它把坐标误差和分类误差同等看待,这实际上并不是很理想。Also,in every image many grid cells do not contain any object;这些cells的置信度分数为零, 因而这常常导致了这些cells的梯度overpowering那些包含目标cells的梯度。使得模型不稳定,导致了训练早期就会出现了梯度爆炸的现象。
为了纠正这些问题,我们提高了来自bounding box坐标预测的损失,并减小了来自不包含目标的boxes的置信度预测损失。We
use two parameters, λ coord and λ noobj to accomplish this. We set λ coord = 5 and λ noobj =0.5 。
平方和误差同样也等同看待large boxes和small boxes的误差。Our error metric should reflect that small deviations in large boxes matter less than in small boxes. To partially address this we predict the square root of the bounding box width and height instead of the width and height directly.
YOLO在每个grid cell会预测多个bounding boxes。在训练的时候,我们希望一个bounding box predictor只对一个物体负责。We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain
sizes, aspect ratios, or classes of object, improving overall recall.
在训练的时候,我们优化如下的由多个部分构成的代价函数:

![]() 代表了第i个cell中存在物体;
代表了第i个cell中存在物体;
![]() 代表了第j个bounding boxes对该次预测负责。
代表了第j个bounding boxes对该次预测负责。
注意:当grid cell中包含有物体的时候,代价函数只考虑分类预测损失(也就是前面讨论过的条件概率)。当第j个bounding boxes predictor(grid cell中具有最高IOU得分的预测器)负责预测这个真实的边界框的时候,此时代价函数只考虑坐标预测损失。
We train the network for about 135 epochs on the training and validation data sets from P ASCAL VOC 2007 and 2012. When testing on 2012 we also include the VOC 2007 test data for training. Throughout training we use a batch size of 64, a momentum of 0.9 and a decay of 0.0005.
Our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from 0.001 to 0.01. If we start at a high learning rate our model often diverges due to unstable gradients. We continue training with 0.01 for 75 epochs, then 0.001for 30 epochs, and finally 0.0001 for 30 epochs.
为了避免过拟合我们使用了dropout 层和数据增强的办法。在第一个连接层之后,速率为0.5的dropout层防止了层之间的联合性(dropout强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。)。对于数据增强,我们引入达到原始图像大小20%的随机缩放和平移。我们还在HSV色彩空间中随机调整图像的曝光和饱和度达1.5倍。
2.3 前向传播
和训练时一样,在检测图像时则之需要神经网络进行一次计算。 On P ASCAL VOC the network predicts 98 bounding boxes per image and class probabilities for each box.不像基于分类器的检测方法,由于YOLO只需运行一个网络进行计算,所以运行速度很快。
网格的设计在边界框预测中强制实现空间多样性。通常我们很清楚物体落入哪个网格中,并且模型为每个物体只预测一个边界框。因而,一些比较大的物体或者是在跨越多个网格边界的物体,可能会被多个网格都很好的检测出来。可以使用NMS(非极大值抑制)来解决这种多重检测的问题。虽然NMS对YOLO性能的影响不像对R-CNN、DPM性能影响那么大,但也能提升2-3%的mAP值。
2.4 YOLO的局限性
YOLO给与边界框施加了强制的空间约束,也就是一个网格预测两个边界框且只能预测一个类别。这种强制的空间约束限制了我们的模型检测周围物体的数量。因而我们的模型正在努力解决识别出一些成群出现小物体(比如成群飞行的鸟类)的问题。
由于我们的模型是根据数据学习预测边界框,因而在遇到新的或者不同寻常的宽高比的物体时,将难以适应。 Our model also uses relatively coarse features for predicting bounding boxes since our architecture has multiple downsampling layers from the
input image.
Finally, while we train on a loss function that approximates detection performance, our loss function treats errors the same in small bounding boxes versus large bounding boxes. 个较小损失值对较大的边界框来说影响较小,但是对较小的边界框则意味着会极大地影响IOU。我们主要的误差来源于检测定位误差。
3 与其他检测系统对比
4 实验
4.1和其他实时系统对比
4.2. VOC 2007误差分析
4.3 Fast R-CNN和YOLO相结合
4.4 VOC 2012结果
4.5 抽象性 艺术作品中的人物检测
5 实地场景的实时检测
6 结论
我们提出了YOLO算法,一个统一的用于目标检测的模型。我们的模型易于构建,且能够直接使用整张图片进行训练。与基于分类器的方法不同,YOLO针对与检测性能直接相关的损失函数来训练,因而整个模型是联合训练的。Fast YOLO is the fastest general-purpose object detector in the literature and YOLO pushes the state-of-the-art in real-time object detection. YOLO also generalizes well to new domains making it ideal for applications that rely on fast, robust object detection.