YOLOV1:You only look once
1.介绍
1.1 简介:
传统的目标检测算法如R-CNN都是先生成候选框,然后在分类器上进行分类,由于每个部分都是分开训练,所以很难去优化而且速度比较慢。而yolov1把目标检测当成一个回归问题,图像输入经过训练后直接输出候选框的坐标和物体属于某个类别的概率。
1.2 优点:
- 1.yolo很快
- 2.yolo在训练时能看到整个图片,因此它隐式的编码有关类别及其外观的上下文信息。而Fast R-CNN是一种顶部检测方法,由于无法看到更大的背景,它会将图像中的背景误认为是物体。
- 3.yolo泛化能力比DPM和R-CNN要好很多,当训练的是一个自然物而预测的是艺术品,它也能表现的很好。
2.统一检测
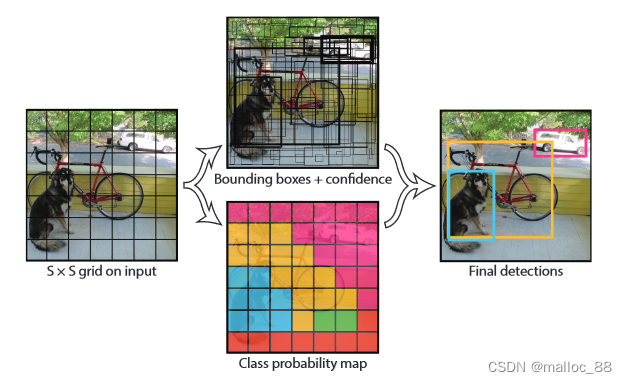
2.1 检测流程
1.首先我们的系统将图片分成S*S个格子,如果一个物体的中心落到这个格子里面,这个格子就负责检测这个物体。
2.每个格子会预测B个候选框的x,y,w,h和物体属于哪个类别的置信度(总共C个类别)。
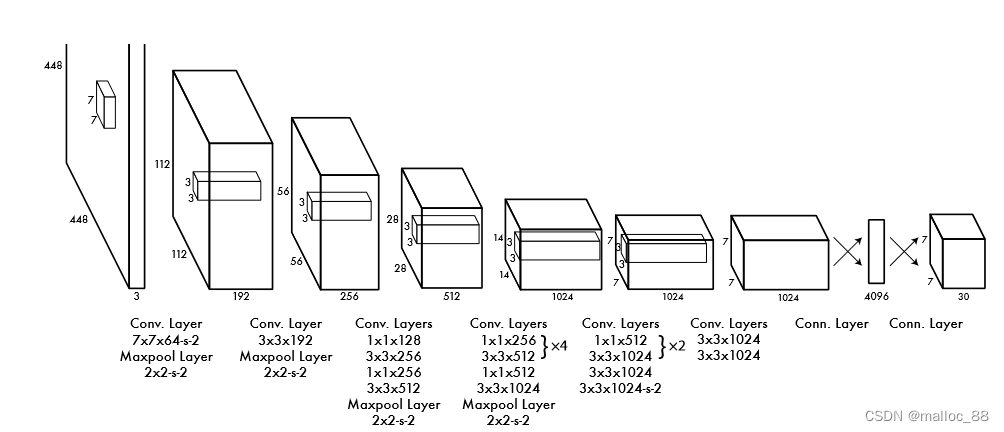
3.网络结构:卷积层用于提取特征,全连接层用于输出坐标和类别概率。
2.2 训练过程
1.我们用224224的图片用于训练,448448的图片用于检测。
2.我们预测的候选框的宽和高是除以整张图片的长和高之后的结果,这样能使结果总是落在0~1之间;预测的x,y坐标是候选框的中心点相对于预测这个物体的格子边界的偏移量,这样也能使结果总是落在0 ~ 1 之间。
3.关于损失函数:
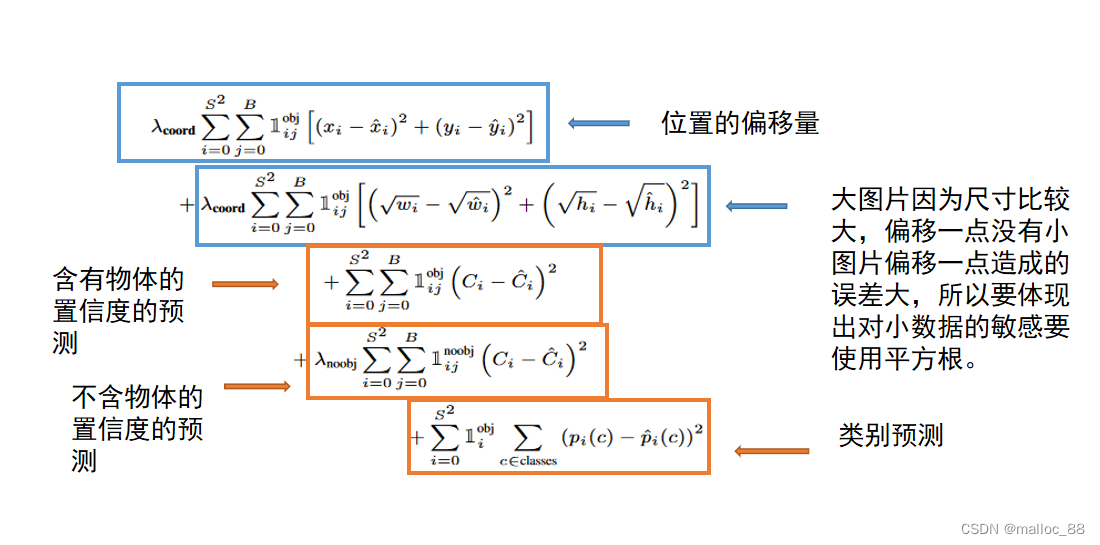
- 置信度误差:分两种情况,一是有object的单元格的置信度计算,另一种是没有object的单元格的置信度计算。两种情况都是单元格中所有的候选框都参与计算。对于有object的单元格中的候选框的置信度的ground truth就是1IOU,需要注意的是这个IOU是在训练过程中不断计算出来的,因为网络在训练过程中每次预测的候选框是变化的,所以候选框和ground truth计算出来的IOU每次也会不一样。而对于没有object的单元格中的bbox的置信度的ground truth为0IOU,因为不包含物体。
- 分类误差:当作回归误差来计算,使用sum-squared error来计算分类误差,需要注意的是只有包含object中心的单元格才参与分类loss的计算,即有object中心点落入的单元格才进行分类loss的计算。
4.非极大值抑制:由于一个格子可以生成很多候选框,我们只取最大置信度的候选框。
3.缺点
- 因为YOLO中每个cell只预测两个bbox和一个类别,这就限制了能预测重叠或邻近物体的数量,比如说两个物体的中心点都落在这个cell中,但是这个cell只能预测一个类别。
- 此外,不像Faster R-CNN一样预测offset,YOLO是直接预测bbox的位置的,这就增加了训练的难度。
- YOLO是根据训练数据来预测bbox的,但是当测试数据中的物体出现了训练数据中的物体没有的长宽比时,YOLO的泛化能力低
- 同时经过多次下采样,使得最终得到的feature的分辨率比较低,就是得到coarse feature,这可能会影响到物体的定位。
- 损失函数的设计存在缺陷,使得物体的定位误差有点儿大,尤其在不同尺寸大小的物体的处理上还有待加强。