文章目录
论文: 《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》
github: https://github.com/meituan/YOLOv6
摘要
YOLOv6-N在T4平台COCO数据集达到35.9 AP,推理速度1234FPS;YOLOv6-S达到43.5 AP,推理速度495FPS,超越YOLOv5-S、YOLOX-S、PPYOLOE-S;YOLOv6-M/L达到49.5%/52.3%;如图1所示

问题
作者发现以下几点可用于优化YOLO
1、RepVGG重参数化可应用于检测器;
2、基于重参数化的探测器的量化也需要精心处理,由于其异构配置而导致的性能下降将难以处理;
3、之前工作较少关注部署;
4、标签分配策略及损失函数设计需要进一步验证 ;
5、对于部署,训练过程可以使用知识蒸馏等策略,但不增加推理成本;
为了推理加速,作者使用了PTQ、QAT量化方法;
YOLOv6总结如下:
1、设计不同结构,达到速度与性能均衡;
2、在分类及回归任务使用自蒸馏策略;
3、充分验证标签分配、损失函数、数据增强策略;
4、使用RepOptimizer及channel级蒸馏改进量化机制;
算法
YOLOv6整体框架如图2所示

网络设计
Backbone
RepVGG将训练时多分支重参数化为推理时单分支结构,达到速度与精度平衡;
受此影响,对于小模型作者设计EfficientRep,如图3a为训练时RepBlock,图3b为推理时将RepBlock转换为33卷积+ReLU形式;
随着模型增大,平铺直连网络结构计算量、参数量指数级增长;对此作者提出CSPStackRep Block如图3c所示,由3个11卷积及多个子网络组成,其中子网络包括两个RepConv+ReLU构成,除此之外,使用CSP连接;与PP-YOLOE中CSPRepResStage相比,CSPStackRep更加简洁,达到速度与精度平衡。

Neck
作者使用YOLOv4、YOLOv5中魔改的PAN(将shortcut改为concat),同时对于小模型使用RepBlock替换CSPBlock,对于大模型使用CSPStackRep Block替换CSPBlock,YOLOv6中neck命名为Rep-PAN。
Head
作者使用分类回归解耦头,并引入混合通道策略(hybrid-channel,HC),每个仅使用一个1个3*3卷积层,称为Efficient Decoupled Head,进一步降低计算量;
Anchor-free方案不需要预设参数,同时后处理耗时短;Anchor-free方案有两种:point-base(FCOS)、keypoint-based(CornerNet),YOLOv6使用point-based方案;
标签分配
SimOTA(YOLOX提出):
SimOTA过程如下:
1、计算成对预测框与真值框代价,由分类及回归loss构成;
2、计算真值框与前k个预测框iou,其和为Dynamic k;因此对于不同真值框,其Dynamic k存在差异。
3、最后选择代价最小的前Dynamic k个预测框作为正样本;
但是SimOTA导致训练过程变慢,因此作者未使用SimOTA.
TAL(Task alignment learning,TOOD提出)
1、在各个特征层计算gt与预测框iou及与分类得分乘积作为score,进行分类检测任务对齐;
2、对于每个gt选择top-k个最大的score对应bbox;
3、选取bbox所使用anchor的中心落在gt内的为正样本;
4、若一个anchor box对应多个gt,则选择gt与预测框iou最大那个预测框对应anchor负责该gt;
TAL使用代价函数(包含分类及回归信息)代替iou进行划分样本标签,从一定程度上解决分类回归不统一问题,比如分类效果不好但定位效果好。
经过实验,作者发现TAL相对于SimOTA性能更好且训练稳定,因此YOLOv6使用TAL;
作者发现PP-YOLOE中改进的ET-head为带来性能增益,但降低推理耗时,因此作者仍使用Efficient decoupled head.
损失函数
分类损失
Focal Loss通过更改cross-entropy损失权重解决正负样本类别不均衡及难易样本不均衡问题;
QFL为解决训练推理时框质量及分类得分用法不一致问题,比如训练过程各个分支分别训练,但是推理时分类得分与质量得分相乘作为nms score进行排序;QFL将FL中硬标签转为软标签,由类别与iou乘积作为软标签;
VFL考虑到正负样本不同重要程度,正样本少而负样本多,VFL降低负样本损失权重;
Poly Loss将分类损失拆分为一系列加权多项式,实验表明效果优于交叉熵损失和FL。
经过实验作者选择VariFocal Loss作为分类损失
框回归损失
框回归损失由最初L1损失,到iou系列损失,iou损失已经证明有效,因为其与评价指标一致;作者在YOLOv6-N及YOLOv6-T使用SIoU损失,其余使用GIoU损失;
DFL将框位置连续分布简化为离散概率分布;YOLOv6-M/L使用DFL,其余未使用。
def distribution_focal_loss(pred, label):
r"""Distribution Focal Loss (DFL) is from `Generalized Focal Loss: Learning
Qualified and Distributed Bounding Boxes for Dense Object Detection
<https://arxiv.org/abs/2006.04388>`_.
Args:
pred (torch.Tensor): Predicted general distribution of bounding boxes
(before softmax) with shape (N, n+1), n is the max value of the
integral set `{0, ..., n}` in paper.
label (torch.Tensor): Target distance label for bounding boxes with
shape (N,).
Returns:
torch.Tensor: Loss tensor with shape (N,).
"""
dis_left = label.long()
dis_right = dis_left + 1
weight_left = dis_right.float() - label
weight_right = label - dis_left.float()
loss = (
F.cross_entropy(pred, dis_left, reduction="none") * weight_left
+ F.cross_entropy(pred, dis_right, reduction="none") * weight_right
)
return loss
目标损失
FCOS引入centerness用于降低低质量框得分,YOLOX通过IoU分支进行,作者尝试目标损失,但未带来增益。
行业有用改进
作者训练时长由300epoch提升到400epoch,性能提升
自蒸馏
作者限制教师模型与学生模型网络结构相同,但经过预训练,因此称为自蒸馏。
归因于DFL损失,回归分支也可使用知识蒸馏,损失函数如式1所示,

图像灰度边界填充
与YOLOv5、YOLOv7一致,作者对图片边界进行half-stride灰度填充,这一策略有助于提升图像边界目标检出能力,但会增加推理耗时。
对此作者认为与马赛克增强有关,最后一轮训练时关闭马赛克操作,同时原图增加灰度边界后,resize到原始图片尺寸,可在不增加耗时情况下,保持或提升模型性能。
量化及部署
作者使用RepOptimizer训练模型获取PTQ(训练后量化)友好权重,如图4所示,特征分布大幅收缩;
为进一步提升PTQ表现,作者选择部分量化敏感层仍使用浮点计算;作者使用MSE、SNR、余弦相似度、AP进行评估,选择top-6量化敏感层仍使用浮点计算。
为防止PTQ不足,作者引入QAT(训练中量化),保证训练推理一致,作者同样使用RepOptimizer,此外使用channel-wise蒸馏,如图5所示;
YOLOv6-S达到42.3 AP,在batch32时达到869FPS。

实验
表1汇总YOLO系列在COCO数据集性能,
与YOLOv5-N/YOLOv7-Tiny相比,YOLOv6-N分别提升7.9%/2.6%,并且诉苦更快;
与YOLOX-S/PPYOLOE-S相比,YOLOv6-S性能分别提升3.0%/0.4%,且速度更快;
YOLOv6-M相比于YOLOv5-M,性能提升4.2%,耗时接近,相比于YOLOX-M/PPYOLOE-M,性能提升2.7%/0.6%,耗时更短;
YOLOv6-L相比于YOLOX-L/PPYOLOE-L,耗时接近,性能分别提升2.8%/1.1%;
YOLOv6-L-ReLU中将YOLOv6-L中SiLU替换为ReLU,速度更快,性能略下降;

消融实验
表2作者比较backbone及neck中不同block及CSPStackRep Block中channel系数(CC)影响,作者发现不同网络结构适用不同策略;

表3表示YOLOv6-L neck中参数影响,窄深网络相对于宽浅网络,性能提升0.2%,耗时接近;
YOLO系列中常用激活函数有ReLU、LReLU、Swish、SiLU、Mish等,虽然SiLU最常用,带来性能提升,但是部署时无法与卷积层融合,ReLU更具有速度优势;

表4作者验证卷积层与激活函数不同组合性能,Conv+SiLU性能最佳,但RepConv+ReLU达到性能与速度均衡;作者在YOLOv6-N/T/S/M中使用RepConv/ReLU,为了达到更高推理速度,YOLOv6-L中使用Conv/SiLU,为了追求性能;

表5作者以YOLOv5-N为基线,验证YOLOv6-N中不同部件影响,解耦头(DH)性能提升1.4%
,耗时增加5%;anchor-free(AF)方案耗时降低51%;
EfficientRep Backbone+Rep-PAN neck(EB+RN)使得性能提升3.6%,耗时降低21%;
Head中混合通道策略(hybrid-channel,HC)使得性能太好0.2%,耗时降低6.8%;

表6展示不同label assign策略影响;

损失函数
损失函数包括分类损失、回归损失、可选择的目标损失,如式3,

表8作者对不同分类损失函数进行验证,作者选用VFL;

表示9作者对不同回归损失,进行比较;YOLOv6-N及YOLOv6-T使用SIoU损失,其余使用GIoU损失;

表10表示概率损失函数影响,YOLOv6-M/L使用DFL,其余未使用;

表11表示目标损失影响,可见YOLOv6-N/S/M中目标损失均为带来增益;作者分析由于TAL中两分支与目标分支存在冲突,TAL中将IoU与分类联合作为,额外引入一分支导致两分支对齐变为三分支,增加对齐难度;

表12表明延长训练epoch,性能提升;

表13表明自蒸馏应用于分类分支性能提升0.4%,回归分支性能提升0.3%,weight decay带来性能提升0.6%;

表14表明当不进行灰度补边时,移除马赛克带来性能下降;使用马赛克,同时输入图片634*634,进行3个像素灰度补边,性能进一步提升;

量化实验
表15表明RepOptimizer带来性能大幅改进;

表16表明**Partial QAT(只对敏感层进行量化)**比full QAT性能更佳,但耗时略增加;

表17表明作者量化的YOLOv6-S速度快性能佳,其余检测器使用PaddleSlim中基于蒸馏量化方法;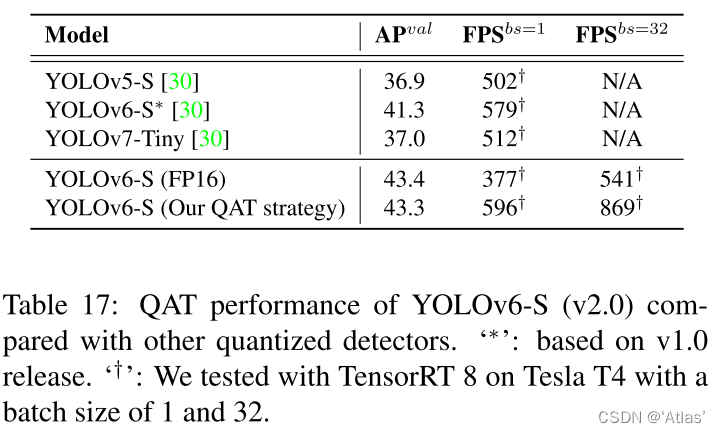
结论
YOLOv6实验了目前先进目标检测策略,同时引入作者想法,在速度及性能上超越当前实时目标检测器。