文章目录
一、论文相关信息
1.论文题目
You Only Look Once
2.论文时间
2015年
3.论文文献
4.论文源码
二、论文背景及简介
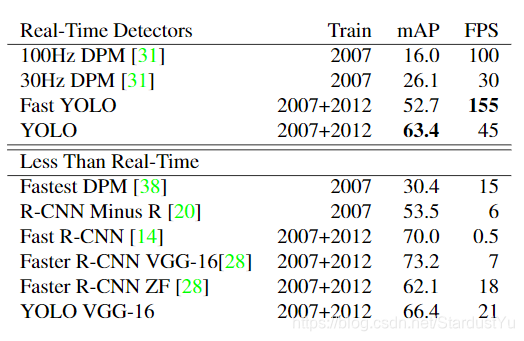
2015年,Fast RCNN改正了RCNN,大幅度提高了精度和速度,尽管如此,Fast RCNN也只能做到0.5 FPS,难以用在实时检测中。当时,目标检测实时检测领域,SOTA为DPM,可以达到30 FPS、mAP 26.1 ( 100 FPS、mAP为16.0),精度太低。这是,YOLO出世,将目标检测视为回归问题,借助一个卷积网络,直接得到一张图片中所有的目标种类以及定位,end to end的优化方法,使得网络达到了 45 FPS、 mAP 63.4,且Fast YOLO版本达到了155 FPS、mAP 52.7。这虽然达不到Fast RCNN的精度,但可以实现实时检测,且作者通过比较,测得Faster RCNN在18 FPS时,精度只有62.1。
三、知识储备
1、YOLOv1的思想
YOLO v1使用一个神经网络就获得所有的目标以及定位信息,他是怎么做到的呢?
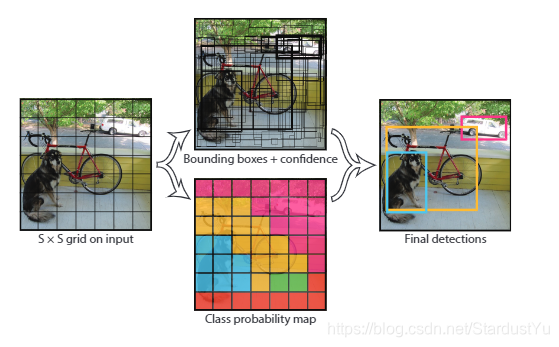
YOLO 将输入图片划分为S * S个栅格,如果一个物体的中心落到某个栅格中,那么这个栅格就负责检测这个物体。作者假设每个栅格可以检测B个物体。一个栅格需要预测的信息如下:
- B个检测框,每个检测狂包含物体框中心相对其所在网格单元格边界的偏移(一般是相对于单元格左上角坐标点的位置偏移,以下用x,y表示)和检测框真实宽高相对于整幅图像的比例(注意这里w,h不是实际的边界框宽和高)且x,y,w,h,confidence都被限制在区间[0,1]。
- 每个框的Confidence,这个confidence代表了预测框含有目标的置信度和这个预测框预测的有多准2重。信息置信度confidence值只有2种情况,要么为0(边界框中不含目标,P(object)=0),要么为预测框与标注框的IOU,因为P(Object)只有0或1,两种可能,有目标的中心落在格子内,那么P(object)=1,否则为0,不存在(0,1)区间中的值。

- 每个格子预测一共C个类别的条件概率分数,并且这个分数和物体框是不相关的,只是基于这个格子。

那么网络就会输出一个 S * S * (5 * B + C)的一个矩阵。
作者通过confidence * 条件概率得到每一个类的置信度。
经过NMS后,得到最终的结果

四、test阶段
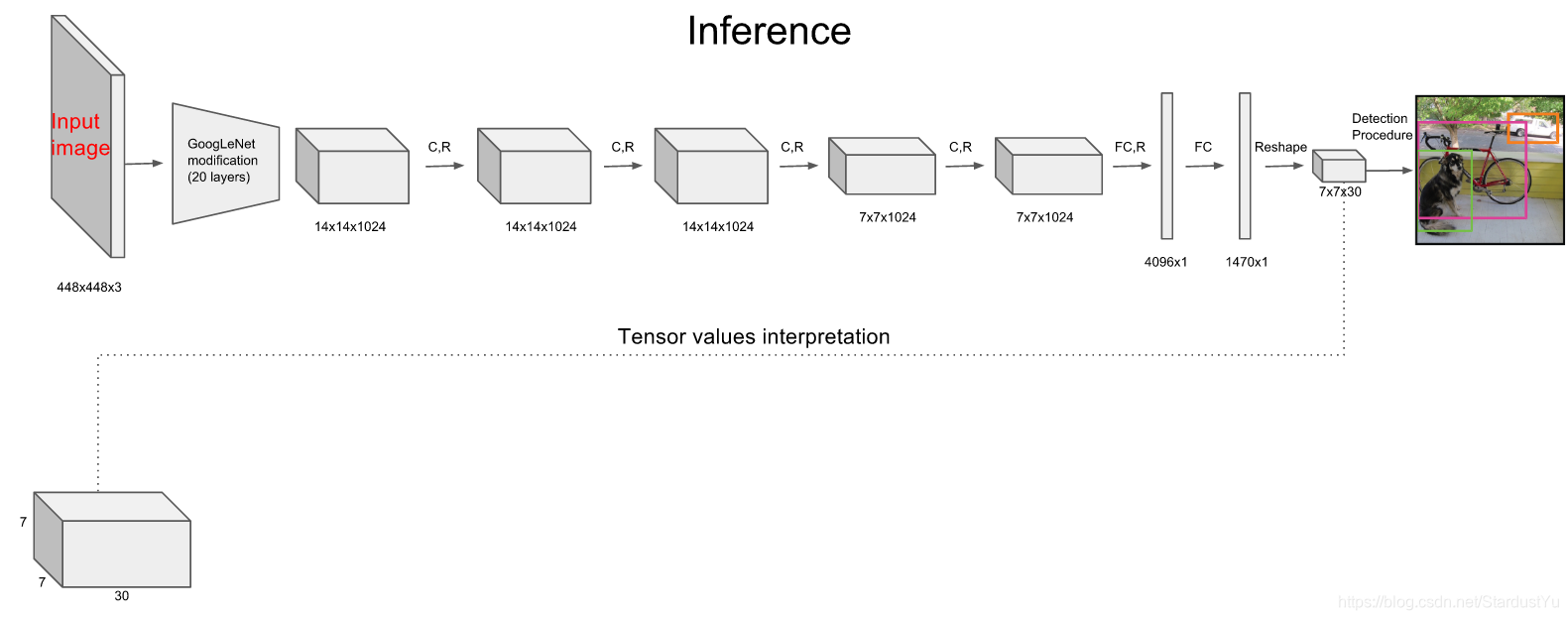
假设在论文实现的模型中,S=7, B = 2, C = 20,因此最后的输出为7 * 7 * (5 * 2 + 20),一些细节将会在下文进行介绍
- 输入一张图片
- 经过一个卷积网络的到7 * 7 * 30的矩阵
- 将该矩阵检测出来的目标框放入NMS中,得到最后的结果
五、train阶段
YOLOv1 为 one-stage模型,一步优化即可,十分简单。
下文将会对其细节进行讲解
1、Loss的确定
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
sum-squared error loss 会让所有的loss的加权一致,因此简单的全部采用了sum-squared error loss来做这件事会有以下不足:
- 会使分类和定位的Loss权重相等,但不包含物体的框太多,不带物体的框的confidence = 0,对网络loss的贡献远大于带物体的检测框,这会使网络发散。作者给定位和分类分配了权重,其中给定位权重为5,分类权重为0.5

- 会给大box和小box分配相同的权重,因为我们知道小box对小的偏差更加敏感,偏离一点会使结果影响更多,因此应该赋予更大的加权。作者通过在计算loss时使用w,h的平方根来解决这个问题。
因此最后的loss为:(仔细分析还是可以看的出来的)

六、实验结果
七、论文细节与思考
1、YOLO相比于RCNN系列对背景分类错误的更少,可以配合Faster RCNN一起使用
因为RCNN只能看得到图片的一部分,不能看到更大的上下文,因此相比于YOLO,会在背景上有更多的错误。因此在Faster RCNN预测出目标框后,在经过YOLO可以减少Faster RCNN的错误率,作者通过这个方法,提高了Faster RCNN的3.2的精度
八、论文优缺点
优点
- YOLO更加快,可以应用于实时场景,可以达到45FPS
- YOLO可以鲁棒性更好,通用性强,对其他不相关的物体预测依旧很好。
- 背景误检率低。YOLO在训练和推理过程中能‘看到’整张图像的整体信息,而基于region proposal的物体检测方法(如rcnn/fast rcnn),在检测过程中,只‘看到’候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。测试证明,YOLO对于背景图像的误检率低于fast rcnn误检率的一半。
缺点
- YOLO仍然是一个速度换精度的算法,目标检测的精度不如RCNN
- 和基于region proposal的方法相比召回率较低。