1.前言
继faster rcnn后RGB大神在目标检测领域再放大招,凭借着接近于艺术般的殿堂级表现。RGB大神成功论证那句名言,每个不断进步的人看到昨天的自己都好像是垃圾。我们都知道faster rcnn是分为两个阶段进行学习的,RCNN+RPN网络。但大神那艺术般的天人为一的直觉告诉他,不对,不对,you only look once。在一个月黑风高的晚上,这个灵感让大神激动地彻夜难眠。人生有几个百年,何不现在起来就干,于是有了这片洋洋洒洒几千余字的大作。
2.you only look once
1.整体概述
通俗一点来讲yolo,计算机本质上是人的延伸,所以我们让他尽可能的接近人,甚至是超越人类。基于faster 的二阶段目标检测理论就像是,你要知道你看到的物体在什么为位置,得先在脑海中想象一下它是什么形状,怎样的大小。但是常识告诉我们,当人们看到一个 物体的时候,并不需要停下来思考该物体可能的形状和大小。so,you only look once.

2.检测流程
整个检测的流程也是非常的简单,如图我们看到有三步,第一步将图片缩放为网络可以接受的大小(448*448);第二步使用卷积网络提取特征,然后使用全连接输出预测框;第三步进行非极大值抑制,删除掉多余的框。
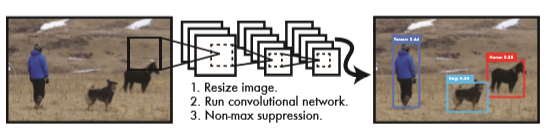
3.网络结构
下面就是整个网络的结构示意图,总共有24个卷积层,2个全连接层,后面接一个输出层。借鉴了残差网络思想,使用1*1的卷积层来对上一层特征进行下采样。同时训练了一个fast yolo,使用9层卷积替换 24层卷积。
最后输出是一个7*7*30的张量,对于这个数据进行解释一下,yolo会将原始的图片切分成S*S(7*7)的cell网格;每个cell只负责预测一个类别物体C;每个cell预测两个候选框B;每一个候选框需要输出五个值x、y、w、h、Pr(Object)。其中包括框的中心点位置(x,y)(相对于cell左上角的偏移量)宽高w、h,和置信度Pr(是否有物体的概率*IOU)因为在pascal数据集上是20分类,每个类别有对应的概率信息。所以最后的输出就是上面的 S*S*(2*5+20) = 7*7*30;
4.损失函数
看起来好麻烦的这个损失函数其实可以分为三个部分,候选框、置信度、分类;均采用se平方差损失。其中λcoord(5)和λnoobj(0.5)为了均衡正例太少负例太多对损失的影响;w、h开根号是为了平衡不同大小的框(相同的差距对于小框的影响要大于大框,平方根来缓和这种不一致性);然后就是对于正例三种损失都有,对于负例只有置信度的损失。

5.激活函数
yolov1使用的是leaky relu,而非传统的relu;也就是说小于0的值,不是按照0来处理,而是乘以0.1。
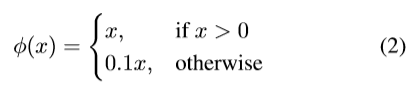
6.训练
1.在训练的时候,数据预处理包括随机的缩放、旋转、将色域转换为HSV后进行曝光度和饱和度的调整。
2.现在imagenet数据集上预训练前20个卷积层,最后的训练和测试使用darknet进行
3.将学习率缓慢的有0.001增长到0.01训练75个轮次、再使用0.001训练30轮次、最后使用0.0001训练30轮次
4.在第一个全连接层使用了0.5的dropout率
5.最后yolo在voc数据集MAP(准确率和召回率计算)达到了63.4,速度达到45FPS,如果主干使用VGG16的话MAP可达到66.4,但是速度会下降为21FPS,勉强可以达到实时。我们看到伟大的yolo虽然在准确率方面比faster有所下降,但是其速度达到了一个 质的提升,能满足大多数场景下对于实时性的需求。但是其召回率方面确实还需要在提升一下,不要担心我们还有yolov2、yolov3和今年刚出来的yolov4,以及刚出来却被别人评价配不上yolo5这个名字的yolov5;反正4、5都不是大神RGB自己做的了,RGB走了,就像周杰伦也不出歌了。

3.相关问题
1.论文说物体中心点所在的cell负责预测这个物体,如何实现?
这个属于工程上的具体实现问题,确实很头疼,但是搞清楚了这个问题你基本上就把yolo代码的内部处理逻辑搞清楚了。
通过源码我们知道,yolo会预先组织出图片中真实框所对应的信息S*S*25(S*S*(置信度+真实框(x,y,w,h)+分类)),对比我们预测框S*S*(2*5+20),因为真实图片中一个cell只负责预测一个框所以不需要乘2。然后会计算真实框的中心点坐标落在哪一个cell中,使用x*(cell_size/image_size)的方式。比如真实框的中心点位置为(224*224),那么负责预测这个真实框的cell就是(int(224*7/448)=3,int(224*7/448)=3),即第三行第三列个cell。
def load_pascal_annotation(self, index):
"""
Load image and bounding boxes info from XML file in the PASCAL VOC
format.
"""
imname = os.path.join(self.data_path, 'JPEGImages', index + '.jpg')
im = cv2.imread(imname)
h_ratio = 1.0 * self.image_size / im.shape[0]
w_ratio = 1.0 * self.image_size / im.shape[1]
# im = cv2.resize(im, [self.image_size, self.image_size])
label = np.zeros((self.cell_size, self.cell_size, 25))
filename = os.path.join(self.data_path, 'Annotations', index + '.xml')
tree = ET.parse(filename)
objs = tree.findall('object')
for obj in objs:
bbox = obj.find('bndbox')
# Make pixel indexes 0-based
#如果图像进行了缩放 框也要进行相应的缩放
x1 = max(min((float(bbox.find('xmin').text) - 1) * w_ratio, self.image_size - 1), 0)
y1 = max(min((float(bbox.find('ymin').text) - 1) * h_ratio, self.image_size - 1), 0)
x2 = max(min((float(bbox.find('xmax').text) - 1) * w_ratio, self.image_size - 1), 0)
y2 = max(min((float(bbox.find('ymax').text) - 1) * h_ratio, self.image_size - 1), 0)
#name属性代表了类别
cls_ind = self.class_to_ind[obj.find('name').text.lower().strip()]
#中心点坐标 宽 高
boxes = [(x2 + x1) / 2.0, (y2 + y1) / 2.0, x2 - x1, y2 - y1]
#计算中心点的坐标落在哪一个cell单元格内
x_ind = int(boxes[0] * self.cell_size / self.image_size)
y_ind = int(boxes[1] * self.cell_size / self.image_size)
if label[y_ind, x_ind, 0] == 1:
continue
#置信度为1 框的坐标 对应的类别为1
label[y_ind, x_ind, 0] = 1
label[y_ind, x_ind, 1:5] = boxes
label[y_ind, x_ind, 5 + cls_ind] = 1
return label, len(objs)
最后在计算loss的时候response对应的就是真实框的置信度,计算loss的时候一个cell中对应的IOU最大的那个框会被预测置信度会置为1,response过滤了所有不负责预测的cell,IOU最大值过滤掉了预测不准确的框,两者相乘就是我们需要调节的框。

2.如何将原图划分为S*S个cell
由问题一可知,我们会把真实框划分为 S*S*25,就将我们的真实框表示为了区域划分的形式,最后计算loss也是以这样划分区域的方式来计算的。这就实现了划分区域来预测的功能。
4.总结
本文我们介绍了曾经很牛逼的yoloV1,其使用一个统一的网络实现了目标检测端到端处理。先使用darknet网络提取特征,再接全连接层进行预测。将原图分成了S*S个区域cell,对物体中心所在的cell进行调整。在NMS非极大值抑制的时候,跟以往的按照阈值留取的方式不同,而是直接取IOU最大的框,来进行调整。还介绍了yolo的三段形式的损失函数。通过这么一种简洁的形式,yolo在预测速度上满足了实时性,美中不足的是在准确率方面yolo还需要再加加油。人家也努力了,也成功了,后面我们就会介绍到。敬请期待!
卧槽,又这么晚了。我发现晚睡晚起是我最舒服的作息时间。我现在特别喜欢那种不学习,一味的玩游戏的负罪感。这么多年,我被这种负罪感折磨着,现在终于成功的摆脱了。那个字叫做爽,现在我再也不是学习的奴隶,而学习是我的小弟了。我明天就要挑战自己什么都不干,我就看电影,往死了看。我就睡觉,我就发呆,反正我就是不学习。牛逼,真牛逼!
Giao哥与徐真真合作最新单曲《开心真Giao》