YoloV1论文解读
摘要
我们提出了一种新的物体检测方法:YOLO。之前的物体检测工作都是重新利用分类器来执行检测。相反,我们将物体检测视为一个回归问题,针对空间分离的边界框和相关类别概率。一个单一的神经网络可以在一次评估中直接从完整图像中预测边界框和类别概率。由于整个检测流水线是单一的网络,因此可以直接在检测性能上进行端到端的优化。
我们的统一架构非常快速。我们的基本YOLO模型以每秒45帧的速度实时处理图像。网络的较小版本Fast YOLO以惊人的每秒155帧的速度处理图像,同时仍然实现了其他实时检测器的两倍mAP。与最先进的检测系统相比,YOLO在定位方面可能会出现更多的错误,但在背景上预测假阳性的可能性较小。最后,YOLO学习到非常通用的物体表示。它在从自然图像到艺术品等其他领域进行泛化时,优于其他检测方法,包括DPM和R-CNN。
1.介绍
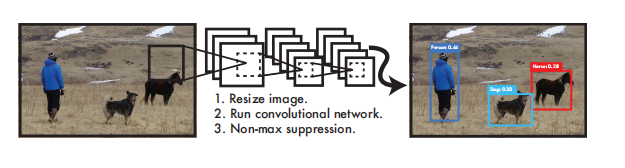
图1:YOLO检测系统。使用YOLO处理图像既简单又直接。我们的系统(1)将输入图像的大小调整为448×448,(2)在图像上运行一个卷积网络,以及(3)通过模型的置信度对检测结果进行阈值。
人类在瞥一眼图像后就能瞬间知道图像中有哪些物体、它们在哪里以及它们之间的互动关系。人类的视觉系统快速而准确,使我们能够执行像驾驶等复杂任务,几乎没有意识到自己在思考。快速而准确的物体检测算法将使计算机能够在没有专用传感器的情况下驾驶汽车,使辅助设备向人类用户传递实时场景信息,并释放出通用、响应迅速的机器人系统的潜力。
当前的检测系统都是将分类器重新用于检测。为了检测一个物体,这些系统需要在测试图像的各个位置和比例上对该物体的分类器进行评估。像可变形零件模型(DPM)这样的系统使用滑动窗口方法,在整个图像上均匀地运行分类器[10]。更近期的方法,如R-CNN,使用区域提议方法首先在图像中生成潜在的边界框,然后在这些提议的边界框上运行分类器。分类后,使用后处理来细化边界框、消除重复检测,并根据场景中的其他物体对边界框进行重新评分[13]。这些复杂的流水线很慢,很难优化,因为每个单独的组件必须分别进行训练。
我们将物体检测重新构建为一个单一的回归问题,直接从图像像素到边界框坐标和类别概率。使用我们的系统,您只需一次看图就能预测出图像中存在哪些物体以及它们的位置。这个方法被我们称为“you only look once” (YOLO),非常简单,如图1所示。一个卷积网络同时预测多个边界框和这些边界框的类别概率。
YOLO使用完整图像进行训练,并直接优化检测性能。这个统一模型比传统的物体检测方法有几个好处。首先,YOLO非常快速。由于我们将检测视为一个回归问题,因此不需要复杂的流水线。我们只需要在测试时在新图像上运行我们的神经网络来预测检测结果即可。我们的基本网络在Titan X GPU上以45帧每秒的速度运行,而快速版本则以超过150帧每秒的速度运行。这意味着我们可以实时处理流媒体视频,延迟不到25毫秒。此外,YOLO的平均精度比其他实时系统高出一倍以上。如果想在网络摄像头上实时演示我们的系统,请参见我们的项目网页:http://pjreddie.com/yolo/。
其次,YOLO在进行预测时全局考虑了图像。与滑动窗口和基于区域提议的技术不同,YOLO在训练和测试时都可以看到整个图像,因此隐含地编码了关于类别及其外观的上下文信息。一个顶尖的检测方法Fast R-CNN,由于无法看到更大的上下文,会将图像中的背景区域误认为是物体。相比之下,YOLO的背景错误少了一半以上。
第三,YOLO学习到了物体的可泛化表示。当在自然图像上进行训练并在艺术品上进行测试时,YOLO的表现优于DPM和R-CNN等顶尖检测方法。由于YOLO高度可泛化,因此在应用于新的领域或意外输入时不太可能出现故障。
YOLO在准确性上仍然落后于最先进的检测系统。虽然它可以快速地识别图像中的物体,但对于一些物体,特别是小物体,它很难精确定位。我们在实验中进一步探讨了这些权衡。
2.统一检测
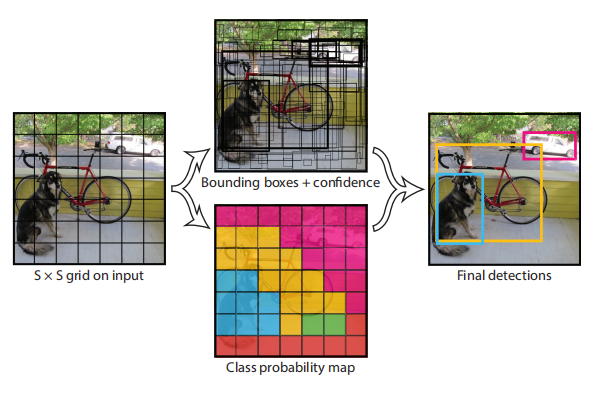
图2:模型。我们的系统将检测建模为一个回归问题。它将图像划分为一个S×S网格,并为每个网格单元预测B边界框、这些框的置信度和C类概率。这些预测被编码为一个 S × S × ( B ∗ 5 + C ) S×S×(B∗5 + C) S×S×(B∗5+C)张量。
我们将目标检测的各个组件统一到一个单一的神经网络中。我们的网络使用整个图像的特征来预测每个边界框。它还同时预测图像中所有类别的所有边界框。这意味着我们的网络对整个图像以及图像中的所有对象进行全局推理。YOLO的设计使得我们可以进行端到端的训练,并在保持高平均精度的同时实现实时速度。
我们的系统将输入图像划分成一个 S × S S×S S×S的网格。如果一个物体的中心落入一个网格单元中,那么该网格单元就负责检测该物体。
每个网格单元预测 B B B个边界框和相应的置信度分数。这些置信度分数反映了模型认为该框包含一个物体的置信度以及它预测的框的准确性。我们形式化地定义置信度为 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)∗IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth。如果该单元格中不存在物体,则置信度分数应为零。否则,我们希望置信度分数等于预测框与实际框之间的IOU(交并比)。
每个边界框由5个预测组成: x , y , w , h x,y,w,h x,y,w,h和置信度。其中, ( x , y ) (x,y) (x,y)坐标表示边界框相对于网格单元的中心。宽度和高度相对于整个图像进行预测。最后,置信度预测表示预测框与任何实际框之间的IOU。
每个网格单元还预测C个条件类别概率, P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)。这些概率是在该网格单元包含一个物体的条件下进行预测的。我们每个网格单元只预测一组类别概率,不管边界框数量B为多少。
在测试时,我们将条件类概率和个体盒子置信度预测相乘
P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r ( C l a s s i ) ∗ I O U p r e d t r u t h ( 1 ) Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred} (1) Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth(1)
这给了我们每个盒子的特定类别的信心分数。这些分数既编码了该类出现在框中的概率,也编码了预测的框与对象的匹配程度。
在对PASCAL VOC数据集上评估YOLO时,我们使用S = 7,B = 2。PASCAL VOC数据集有20个标记类别,因此C = 20。我们的最终预测是一个7×7×30的张量。
2.1 网络设计
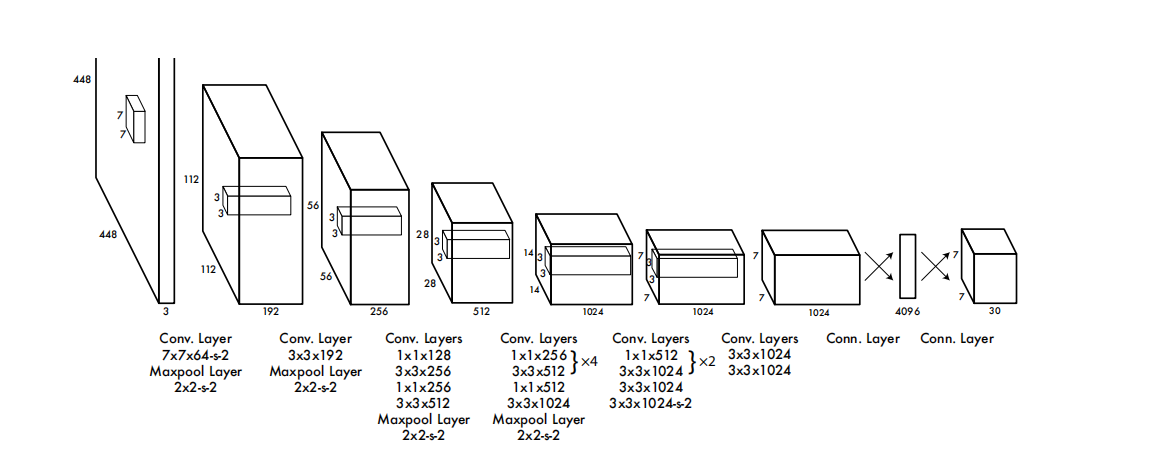
图3:网络结构。我们的检测网络由24个卷积层和2个全连接层组成。交替使用的1×1卷积层可以减少前面层的特征空间。我们在ImageNet分类任务上对卷积层进行半分辨率(224×224输入图像)的预训练,然后在检测时将分辨率加倍。
我们将这个模型实现为卷积神经网络,并在PASCAL VOC检测数据集[9]上进行评估。网络的初始卷积层从图像中提取特征,而完全连接的层预测输出的概率和坐标。
我们的网络架构受到GoogLeNet图像分类模型[34]的启发。我们的网络包括24个卷积层和2个完全连接层。我们不使用GoogLeNet中的Inception模块,而是采用了1×1的降维层,然后是3×3的卷积层,类似于Lin等人[22]的方法。完整的网络结构如图3所示。
我们还训练了一个快速版本的YOLO,旨在推动快速目标检测的边界。快速YOLO使用较少的卷积层(仅有9层而不是24层)和较少的滤波器。除了网络大小之外,YOLO和Fast YOLO之间的所有训练和测试参数都相同。
我们网络的最终输出是7×7×30的预测张量。
2.2 训练
我们在 ImageNet 1000 类竞赛数据集 [30] 上预训练我们的卷积层。对于预训练,我们使用图 3 中的前 20 个卷积层,后面跟着一个平均池化层和一个全连接层。我们训练这个网络大约一个星期, 在 ImageNet 2012 验证集上实现单一裁剪 top-5 准确率为 88%,与 Caffe 模型库 [24] 中的 GoogLeNet 模型相当。我们使用 Darknet 框架进行所有训练和推理 [26]。
然后,我们将模型转换为执行检测。Ren 等人表明,将卷积层和连接层添加到预训练网络可以提高性能 [29]。按照他们的示例,我们添加了四个卷积层和两个全连接层,权重随机初始化。检测通常需要细粒度的视觉信息,因此我们将网络的输入分辨率从 224 × 224 增加到 448 × 448。
我们的最后一层预测类概率和边界框坐标。我们通过图像宽度和高度来对边界框宽度和高度进行归一化,使它们落在 0 到 1 之间。我们将边界框 x 和 y 坐标参数化为特定网格单元位置的偏移,因此它们也被限制在 0 到 1 之间。
我们在最后一层使用线性激活函数,而在所有其他层中使用以下的修正线性激活函数:
f ( x ) = { 0.1 x , x < = 0 x , o t h e r w i s e ( 2 ) f(x) = \begin{cases} 0.1x, & x <= 0 \\ x, & otherwise \end{cases}(2) f(x)={ 0.1x,x,x<=0otherwise(2)
我们的模型输出的优化目标是总均方误差(sum-squared error)。我们使用总均方误差是因为它易于优化,然而它并不完全符合我们最大化平均精度的目标。它同等地权衡了定位误差和分类误差,这可能不是理想的。此外,在每张图像中,许多网格单元格中不包含任何物体。这会使这些单元格的“置信度”得分趋近于零,往往会压倒包含物体的单元格的梯度。这可能导致模型不稳定,使训练过早发散。
为了解决这个问题,我们增加了边界框坐标预测的损失,并减小了不包含物体的边界框置信度预测的损失。我们使用了两个参数 λ c o o r d λ_{coord} λcoord和 λ n o o b j λ_{noobj} λnoobj来实现这一点。我们将 λ c o o r d λ_{coord} λcoord设置为5,将 λ n o o b j λ_{noobj} λnoobj设置为0.5。
总均方误差同等地权衡了大框和小框中的误差。我们的误差度量应该反映出大框和小框中小偏差的重要性不同。为了部分解决这个问题,我们预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO在每个网格单元格中预测多个边界框。在训练时,我们只希望一个边界框预测器负责每个物体的预测。我们分配一个预测器来“负责”预测一个物体,该预测器基于当前与真实值具有最高IOU的预测。这导致边界框预测器之间的专业化。每个预测器在预测特定大小、长宽比或类别的物体方面变得更加准确,提高了整体召回率。
在训练过程中,我们优化以下多部分损失函数:
λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ( C i − C i ^ ) 2 + λ n o o j b ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j ( C i − C i ^ ) 2 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) − p i ^ ( c ) ) 2 ( 3 ) \lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{obj}_{ij}[(x_i-\hat{x}_i)^2+(y_i-\hat{y}_i)^2]\\+\lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{obj}_{ij}[(\sqrt{w_i}-\sqrt{\hat{w}_i})^2+(\sqrt{h_i}-\sqrt{\hat{h}_i})^2] \\ +\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{obj}_{ij}(C_i-\hat{C_i})^2\\ + \lambda_{noojb}\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{noobj}_{ij}(C_i-\hat{C_i})^2\\+\sum^{S^2}_{i=0}1^{obj}_{i}\sum_{c\in classes}(p_i(c)-\hat{p_i}(c))^2(3) λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2]+λcoordi=0∑S2j=0∑B1ijobj[(wi−w^i)2+(hi−h^i)2]+i=0∑S2j=0∑B1ijobj(Ci−Ci^)2+λnoojbi=0∑S2j=0∑B1ijnoobj(Ci−Ci^)2+i=0∑S21iobjc∈classes∑(pi(c)−pi^(c))2(3)
其中, 1 i j o b j 1^{obj}_{ij} 1ijobj表示对象是否出现在第 $i $个单元格中, 1 i j o b j 1^{obj}_{ij} 1ijobj表示第 $i 个单元格中的第 个单元格中的第 个单元格中的第 j $个边界框预测器“负责”该预测。
需要注意的是,仅当网格单元格中存在物体时,损失函数才惩罚分类误差(因此前面讨论的条件类概率)。如果该预测器“负责”地面真实框(即在该网格单元格中具有最高IOU的预测器),则它仅惩罚边界框坐标误差。
我们在 PASCAL VOC 2007 和 2012 的训练和验证数据集上训练网络约 135 个 epoch。在针对 2012 进行测试时,我们还包括 VOC 2007 的测试数据进行训练。在整个训练过程中,我们使用批量大小为 64、动量为 0.9 和衰减率为 0.0005。
我们的学习率计划如下:在前几个 epoch 中,我们缓慢地将学习率从 10^(-3) 提高到 10^(-2)。如果我们从高学习率开始,由于不稳定的梯度,模型往往会发散。我们继续使用 10^(-2) 进行 75 个 epoch 的训练,然后使用 10^(-3) 进行 30 个 epoch 的训练,最后使用 10^(-4) 进行 30 个 epoch 的训练。
为了避免过拟合,我们使用了 dropout 和广泛的数据增强。在第一个连接层之后,dropout 层的速率为 0.5,以防止层之间的共适应[18]。对于数据增强,我们引入了随机缩放和平移,最多可达到原始图像大小的 20%。我们还随机调整图像在 HSV 色彩空间中的曝光和饱和度,最多可达到 1.5 倍的因子。
2.3 推理
就像在训练中一样,在测试图像中预测检测只需要进行一次网络评估。在 PASCAL VOC 上,网络对每个图像预测 98 个边界框和每个框的类别概率。由于它只需要一次网络评估,因此 YOLO 在测试时非常快速,不像基于分类器的方法。
网格设计在边界框预测中强制实施空间多样性。通常情况下,可以确定对象属于哪个网格单元格,因此网络仅为每个对象预测一个框。然而,一些大物体或靠近多个单元格边界的物体可以被多个单元格很好地定位。非极大值抑制可以用来修复这些多个检测。虽然对于 R-CNN 或 DPM 一样关键,但非极大值抑制可以增加 2-3% 的 mAP。
2.4. YOLO 的局限性
YOLO 对边界框预测施加了强烈的空间约束,因为每个网格单元格仅预测两个框,并且只能有一个类别。这种空间约束限制了模型能够预测附近对象的数量。我们的模型很难识别出出现在群体中的小物体,例如一群鸟。
由于我们的模型从数据中学习预测边界框,因此它很难推广到具有新的或不寻常长宽比或配置的对象。我们的模型还使用相对粗糙的特征来预测边界框,因为我们的架构从输入图像中具有多个下采样层。
最后,虽然我们训练的损失函数近似于检测性能,但我们的损失函数在小边界框和大边界框中同等处理误差。在大框中的小误差通常是无害的,但在小框中的小误差对 IOU 有更大的影响。我们主要的误差来源是错误的定位。
3.与其他目标检测框架的比较
目标检测是计算机视觉中的核心问题。检测流程通常从输入图像中提取一组稳健的特征(如Haar [25]、SIFT [23]、HOG [4]、卷积特征 [6]),然后使用分类器[36、21、13、10]或定位器[1、32]在特征空间中识别对象。这些分类器或定位器在整个图像上以滑动窗口的方式运行,或者在图像的某些区域的子集上运行[35、15、39]。我们将 YOLO 检测系统与几个顶级检测框架进行比较,突出显示关键的相似之处和不同之处。
可变形部件模型(DPM)
DPM使用滑动窗口方法进行对象检测[10]。DPM使用不相交的流水线来提取静态特征、分类区域、预测高分区域的边界框等等。我们的系统使用单个卷积神经网络替换了所有这些不同的部分。网络执行特征提取、边界框预测、非极大值抑制和上下文推理,所有这些都是同时进行的。网络训练特征线并为检测任务优化它们,而不是使用静态特征。我们的统一架构比DPM更快、更准确。
R-CNN
R-CNN及其变体使用区域建议代替滑动窗口在图像中查找对象。Selective Search[35]生成潜在的边界框,卷积网络提取特征,SVM对框进行评分,线性模型调整边界框,非极大值抑制消除重复的检测。这个复杂流程的每个阶段必须精确地独立调整,结果系统非常缓慢,测试时每张图像需要超过40秒。
YOLO与R-CNN有一些相似之处。每个网格单元格提议潜在的边界框,并使用卷积特征对这些框进行评分。然而,我们的系统对网格单元格提议施加了空间约束,有助于减轻相同对象的多个检测。我们的系统还提出了远远少于Selective Search的边界框,每个图像只有98个。最后,我们的系统将这些单独的组件合并成一个统一优化的模型。
其他快速检测器
Fast和Faster R-CNN专注于通过共享计算和使用神经网络代替Selective Search来提高R-CNN的速度[14][28]。虽然它们在速度和准确性方面都比R-CNN有所提高,但仍然无法达到实时性能。许多研究工作都专注于加速DPM管道[31][38][5]。它们加速HOG计算,使用级联并将计算推向GPU。然而,只有30Hz的DPM[31]实际上可以实时运行。与优化大型检测管道的各个组件不同,YOLO完全抛弃了管道,并通过设计实现了快速检测。
单类别的检测器,如人脸或人形检测器,可以进行高度优化,因为它们需要处理的变化范围较小[37]。YOLO是一个通用检测器,可以学习同时检测各种对象。
Deep MultiBox
与R-CNN不同的是,Szegedy等人训练卷积神经网络来预测感兴趣的区域[8],而不是使用Selective Search。MultiBox也可以通过将置信度预测替换为单个类别预测来执行单个对象检测。然而,MultiBox无法执行通用对象检测,仍然只是较大检测管道中的一部分,需要进一步的图像补丁分类。YOLO和MultiBox都使用卷积网络在图像中预测边界框,但YOLO是一个完整的检测系统。
OverFeat
Sermanet等人训练了一个卷积神经网络来执行定位,并将该定位器适应为执行检测[32]。OverFeat有效地执行滑动窗口检测,但仍然是一个不相交的系统。OverFeat优化了定位而不是检测性能。像DPM一样,当进行预测时,定位器只看到局部信息。OverFeat无法推理全局上下文,因此需要进行大量的后处理才能产生连贯的检测结果。
MultiGrasp
我们的设计与Redmon等人关于抓取检测的工作类似[27]。我们对边界框预测的网格方法基于MultiGrasp系统用于回归到抓取区域。然而,抓取检测比对象检测要简单得多。MultiGrasp只需要为包含一个对象的图像预测一个可抓取的区域。它不需要估计对象的大小、位置或边界,也不需要预测其类别,只需要找到一个适合抓取的区域。YOLO在图像中预测多个类别的多个对象的边界框和类别概率。
4. 实验
我们首先将YOLO与其他实时检测系统在PASCAL VOC 2007上进行比较。为了理解YOLO和R-CNN变体之间的差异,我们探索了YOLO和Fast R-CNN在VOC 2007上的错误。Fast R-CNN是R-CNN的最高性能版本之一[14]。基于不同的错误配置文件,我们展示了YOLO可以用于重新评分Fast R-CNN检测结果,并减少背景假阳性的错误,从而显着提高性能。我们还展示了VOC 2012的结果,并将平均精度与当前最先进的方法进行比较。最后,我们展示了YOLO在两个艺术品数据集上相比其他检测器更好地泛化的结果。
4.1.与其他实时系统的比较
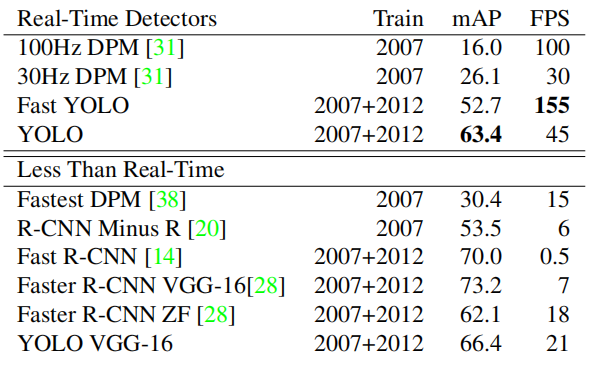
表1:PASCAL VOC 2007上的实时系统。比较快速检测器的性能和速度。快速YOLO是PASCAL VOC检测记录中最快的检测器,仍然比任何其他实时检测器准确性高出两倍。YOLO比快速版本准确性高10个mAP,同时速度仍然远高于实时。
许多目标检测的研究集中于提高标准检测流程的速度。[5] [38] [31] [14] [17] [28] 然而,只有Sadeghi等人真正实现了一个实时运行的检测系统(每秒30帧或更快)[31]。我们将YOLO与他们的GPU实现的DPM进行比较,后者可以以30Hz或100Hz运行。尽管其他研究没有达到实时里程碑,但我们仍然比较它们相对的mAP和速度,以研究目标检测系统中可用的准确性-性能权衡。
快速YOLO是PASCAL上最快的目标检测方法;据我们所知,它是现有最快的目标检测器。具有52.7%的mAP,比实时检测的先前工作准确性高出两倍以上。YOLO将mAP推到了63.4%,同时仍保持实时性能。
我们还使用VGG-16对YOLO进行训练。这个模型更准确,但比YOLO慢得多。它有助于与其他依赖VGG-16的检测系统进行比较,但由于比实时更慢,本文的其余部分集中于我们更快的模型。
最快的DPM有效地加速了DPM而不牺牲太多的mAP,但它仍然相对于实时性能慢了两倍[38]。它也受到DPM在检测方面相对低的准确性的限制,与神经网络方法相比,准确性较低。
R-CNN减去R用静态边界框提议替换了选择性搜索[20]。虽然它比R-CNN快得多,但仍然无法达到实时,并且由于没有好的提议,准确性受到了重大影响。
快速R-CNN加速了R-CNN的分类阶段,但它仍然依赖于选择性搜索,每张图像大约需要2秒钟来生成边界框提议。因此,它具有高mAP,但以0.5 fps远未达到实时。
最近的Faster R-CNN使用神经网络来提出边界框,类似于Szegedy等人[8]。在我们的测试中,它们最准确的模型达到了7 fps,而较小但不太准确的模型以18 fps运行。Faster R-CNN的VGG-16版本比YOLO低10个mAP,但比YOLO慢6倍。Zeiler-Fergus Faster R-CNN比YOLO慢2.5倍,但准确性较低。
4.2. VOC 2007错误分析
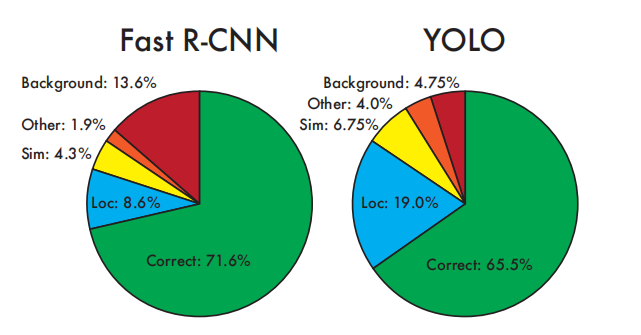
图4:错误分析:Fast R-CNN vs. YOLO。这些图表显示了各个类别(N =该类别中的对象数量)中前N个检测结果中定位错误和背景错误的百分比。
为了进一步研究YOLO和最先进的检测器之间的差异,我们查看了在VOC 2007上的详细结果分析。我们将YOLO与Fast R-CNN进行比较,因为Fast R-CNN是PASCAL上性能最好的检测器之一,其检测结果是公开可用的。
我们使用Hoiem等人的方法和工具[19]。在测试时间内,对于每个类别,我们查看该类别的前N个预测结果。每个预测结果可以是正确的,也可以是根据错误类型进行分类:
• 正确:正确的类别和IOU> .5
• 定位:正确的类别,.1 < IOU < .5
• 相似:类别相似,IOU > .1
• 其他:类别错误,IOU > .1
• 背景:任何对象的IOU < .1
图4显示了所有20个类别平均分解每种错误类型的情况。
YOLO难以正确定位物体。定位错误占据了YOLO错误的大部分比例,比所有其他来源的错误加起来还要多。Fast R-CNN的定位错误远少于YOLO,但背景错误要多得多。其前N个检测结果中有13.6%是不包含任何对象的误报。Fast R-CNN比YOLO更有可能预测背景检测结果,将近三倍。
4.3. 结合Fast R-CNN和YOLO
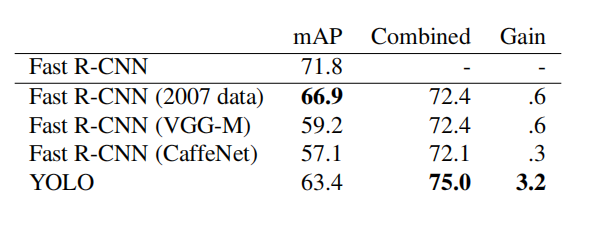
表2:在VOC 2007上的模型组合实验。我们研究了将各种模型与最佳的Fast R-CNN版本结合起来的效果。其他版本的Fast R-CNN提供的只是微小的好处,而YOLO则可以显著提高性能。
YOLO比Fast R-CNN少犯背景错误。通过使用YOLO消除Fast R-CNN的背景检测结果,我们可以显著提高性能。对于R-CNN预测的每个边界框,我们检查是否有类似的边界框被YOLO预测。如果确实有,我们将根据YOLO预测的概率和两个边界框之间的重叠给予该预测结果加成。
最佳的Fast R-CNN模型在VOC 2007测试集上达到71.8%的mAP。与YOLO组合后,它的mAP增加了3.2%至75.0%。我们还尝试将最佳的Fast R-CNN模型与其他几个Fast R-CNN版本结合起来。这些集合产生了0.3%至0.6%之间的小幅增长,详见表2。
YOLO的提升并不仅仅是模型集成的副产品,因为组合不同版本的Fast R-CNN几乎没有多大的好处。相反,正是因为YOLO在测试时间犯了不同类型的错误,所以它对提高Fast R-CNN的性能非常有效。
不幸的是,这种组合无法从YOLO的速度中受益,因为我们分别运行每个模型,然后将结果组合。然而,由于YOLO速度非常快,与Fast R-CNN相比,它不会增加任何显著的计算时间。
4.4.VOC 2012结果
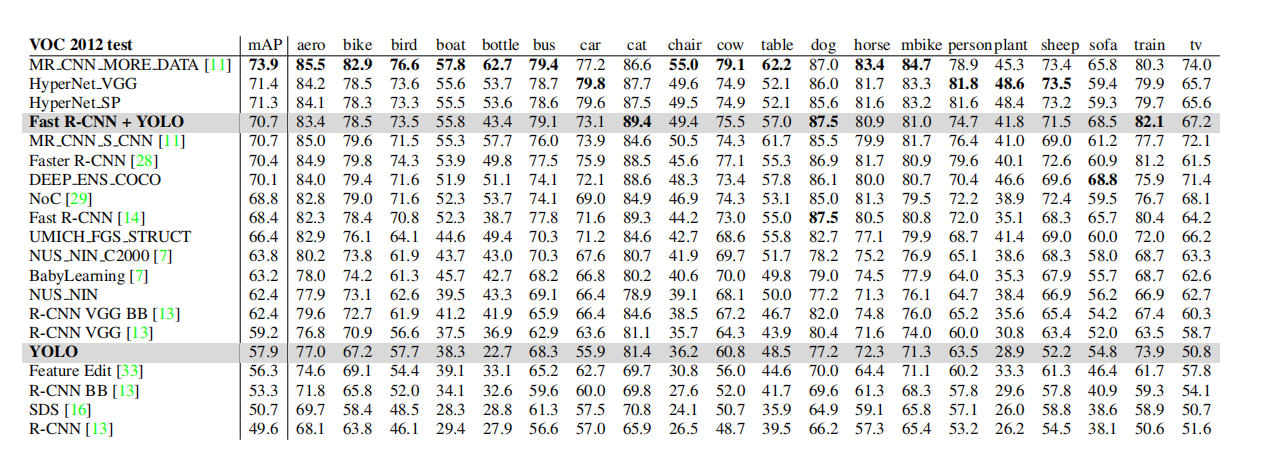
表3:PASCAL VOC 2012排行榜。截至2015年11月6日,YOLO与允许使用外部数据的完整comp4公共排行榜进行了比较。显示了各种检测方法的平均精度和每类平均精度。YOLO是唯一的实时检测器。Fast R-CNN + YOLO是第四高得分的方法,比Fast R-CNN提高了2.3%。
4.5. 通用性:艺术品中的人物检测
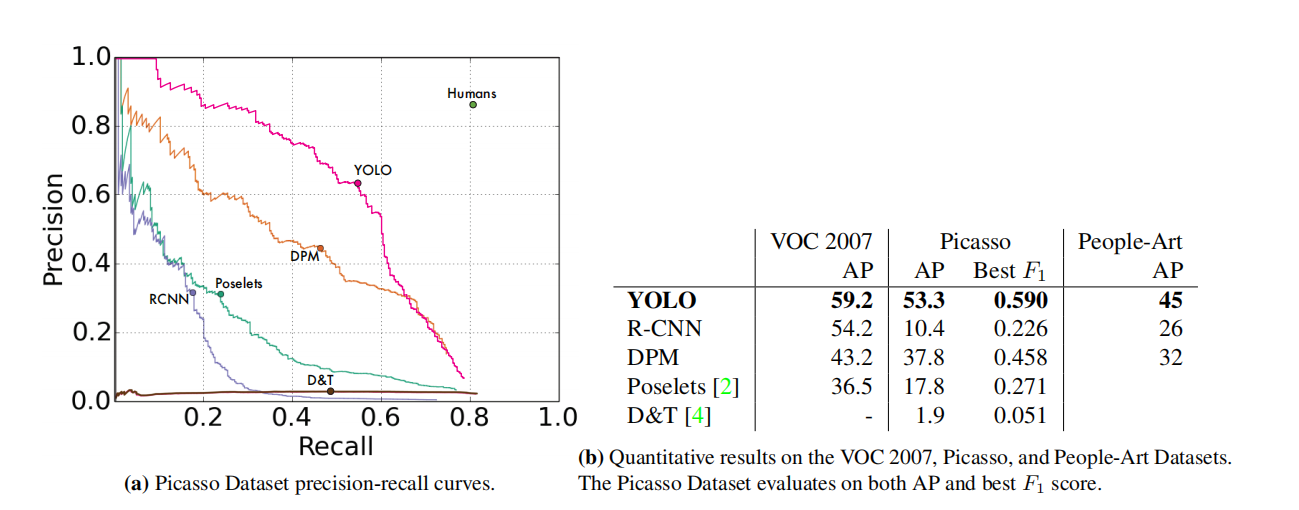
图5:Picasso和People-Art数据集的通用性结果。
用于物体检测的学术数据集从同一分布中提取训练和测试数据。在实际应用中,很难预测所有可能的用例,测试数据可能会与系统以前看到的数据不同[3]。我们在Picasso数据集[12]和People-Art数据集[3]上将YOLO与其他检测系统进行了比较,这两个数据集用于测试艺术品中的人物检测。
图5显示了YOLO和其他检测方法之间的比较性能。为参考,我们给出了在所有模型仅在VOC 2007数据上训练时,对人物的VOC 2007检测AP。在Picasso上,模型是在VOC 2012上训练的,而在People-Art上,模型是在VOC 2010上训练的。
在VOC 2007上,R-CNN具有较高的AP。然而,在应用于艺术品时,R-CNN的表现大幅下降。R-CNN使用选择性搜索来提出边界框,这适用于自然图像。R-CNN中的分类器仅查看小区域,并需要良好的提议。
DPM在应用于艺术品时保持其AP水平。先前的工作理论认为DPM表现良好是因为它具有强大的物体形状和布局的空间模型。虽然DPM不像R-CNN那样退化,但其起点较低。
YOLO在VOC 2007上具有良好的性能,并且在应用于艺术品时,其AP下降的程度小于其他方法。与DPM类似,YOLO模拟了物体的大小和形状,以及物体之间的关系和物体通常出现的位置。虽然艺术品和自然图像在像素级别上非常不同,但它们在物体的大小和形状方面是相似的,因此YOLO仍可以预测出好的边界框和检测结果。

图6:定性结果。YOLO运行在样本艺术品和自然图像从互联网上。虽然它确实认为一个人是飞机,但它基本上是准确的
5. 在野外的实时检测
YOLO是一个快速、准确的物体检测器,非常适合计算机视觉应用。我们将YOLO连接到网络摄像头上,并验证它能够保持实时性能,包括从摄像头获取图像并显示检测结果的时间。
结果系统具有交互性和吸引力。虽然YOLO单独处理每个图像,但连接到网络摄像头时,它就像一个跟踪系统一样工作,检测物体移动和外观变化。我们的项目网站上提供了该系统的演示和源代码:http://pjreddie.com/yolo/。
6.结论
我们介绍了YOLO,一种用于物体检测的统一模型。我们的模型构建简单,可以直接在完整图像上进行训练。与基于分类器的方法不同,YOLO是在直接对应检测性能的损失函数上进行训练,并且整个模型是联合训练的。
Fast YOLO是文献中最快的通用物体检测器,而YOLO则推动了实时物体检测的最新技术水平。YOLO还具有很好的泛化性,适用于新的领域,因此非常适合依赖快速、稳健的物体检测的应用。
代码解释
本文代码来自:code,侵删
项目结构:
- 读取XML文件信息(write_txt.py)
- 数据集预处理(yoloData.py)
- YOLOV1网络结构定义(resnet50.py)
- 损失函数定义(yoloLoss.py)
- 训练网络(train.py)
- 进行预测(predict.py)
write_txt.py
VOC格式
首先介绍一下VOC数据格式:
VOC(Visual Object Classes)数据格式是一种广泛使用的数据格式,主要用于计算机视觉任务,如图像分类、物体检测和分割。它起源于 PASCAL VOC(Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes)挑战赛,这是一项在 2005-2012 年间举办的计算机视觉竞赛。
VOC 数据格式包含两大部分:图像数据和标注数据。
-
图像数据:存储图像文件,通常为 JPG 格式。
-
标注数据:存储与图像相关的标注信息,通常为 XML 文件。每个图像的标注信息在一个单独的 XML 文件中。XML 文件遵循以下结构:
<annotation>
<folder>图像所在文件夹名称</folder>
<filename>图像文件名</filename>
<source>
<database>图像来源数据库</database>
<annotation>标注来源</annotation>
<image>图像来源</image>
</source>
<size>
<width>图像宽度</width>
<height>图像高度</height>
<depth>图像通道数</depth>
</size>
<segmented>是否用于分割任务(0或1)</segmented>
<object>
<name>物体类别名称</name>
<pose>物体姿态</pose>
<truncated>物体是否被截断(0或1)</truncated>
<difficult>物体是否难以识别(0或1)</difficult>
<bndbox>
<xmin>边界框左上角 x 坐标</xmin>
<ymin>边界框左上角 y 坐标</ymin>
<xmax>边界框右下角 x 坐标</xmax>
<ymax>边界框右下角 y 坐标</ymax>
</bndbox>
</object>
...
</annotation>
VOC 数据格式的主要优点是简单易懂、易于解析。然而,随着深度学习和计算机视觉领域的发展,新的数据格式(如 COCO 和 YOLO)已经出现并得到广泛应用,它们在某些方面具有更高的灵活性和效率。尽管如此,VOC 数据格式仍然是计算机视觉领域的一种基本数据格式。
代码
导包
import xml.etree.ElementTree as ET
import os
import random
定义类
VOC_CLASSES = ( # 定义所有的类名
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor') # 使用其他训练集需要更改
定义路径
train_set = open('voctrain.txt', 'w')
test_set = open('voctest.txt', 'w')
Annotations = 'VOCdevkit//VOC2007//Annotations//'
分割数据集测试集
xml_files = os.listdir(Annotations)
random.shuffle(xml_files) # 打乱数据集
train_num = int(len(xml_files) * 0.7) # 训练集数量
train_lists = xml_files[:train_num] # 训练列表
test_lists = xml_files[train_num:] # 测测试列表
解析xml文件
def parse_rec(filename): # 输入xml文件名
tree = ET.parse(filename)
objects = []
# 查找xml文件中所有object元素
for obj in tree.findall('object'):
# 定义一个字典,存储对象名称和边界信息
obj_struct = {
}
difficult = int(obj.find('difficult').text)
if difficult == 1: # 若为1则跳过本次循环
continue
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(float(bbox.find('xmin').text)),
int(float(bbox.find('ymin').text)),
int(float(bbox.find('xmax').text)),
int(float(bbox.find('ymax').text))]
objects.append(obj_struct)
return objects
yoloData.py
用于整理数据集和数据增强,这个数据集有如下几个方法:
class yoloDataset(Dataset):
def __init__(self, img_root, list_file, train, transform):#初始化
def __getitem__(self, idx): #获取一个图片
def __len__(self):
def encoder(self, boxes, labels): # 输出ground truth (一个7*7*30的张量)
# 以下都是数据增强操作
def random_flip(self, im, boxes): # 随机翻转
def randomScale(self, bgr, boxes): # 随机伸缩变换
def randomBlur(self, bgr): # 随机模糊处理
def RandomBrightness(self, bgr): # 随机调整图片亮度
def randomShift(self, bgr, boxes, labels): # 平移变换
初始化
def __init__(self, img_root, list_file, train, transform):
# 初始化参数
self.root = img_root
self.train = train
self.transform = transform
# 后续要提取txt文件的信息,分类后装入以下三个列表
# 文件名
self.fnames = []
# 位置信息
self.boxes = []
# 类别信息
self.labels = []
# 网格大小
self.S = 7
# 候选框个数
self.B = 2
# 类别数目
self.C = CLASS_NUM
# 求均值用的
self.mean = (123, 117, 104)
# 打开文件,就是voctrain.txt或者voctest.txt文件
file_txt = open(list_file)
# 读取txt文件每一行
lines = file_txt.readlines()
# 逐行开始操作
for line in lines:
# 去除字符串开头和结尾的空白字符,然后按照空白字符(包括空格、制表符、换行符等)分割字符串并返回一个列表
splited = line.strip().split()
# 存储图片的名字
self.fnames.append(splited[0])
# 计算一幅图片里面有多少个bbox,注意voctrain.txt或者voctest.txt一行数据只有一张图的信息
num_boxes = (len(splited) - 1) // 5
# 保存位置信息
box = []
# 保存标签信息
label = []
# 提取坐标信息和类别信息
for i in range(num_boxes):
x = float(splited[1 + 5 * i])
y = float(splited[2 + 5 * i])
x2 = float(splited[3 + 5 * i])
y2 = float(splited[4 + 5 * i])
# 提取类别信息,即是20种物体里面的哪一种 值域 0-19
c = splited[5 + 5 * i]
# 存储位置信息
box.append([x, y, x2, y2])
# 存储标签信息
label.append(int(c))
# 解析完所有行的信息后把所有的位置信息放到boxes列表中,boxes里面的是每一张图的坐标信息,也是一个个列表,即形式是[[[x1,y1,x2,y2],[x3,y3,x4,y4]],[[x5,y5,x5,y6]]...]这样的
self.boxes.append(torch.Tensor(box))
# 形式是[[1,2],[3,4]...],注意这里是标签,对应位整型数据
self.labels.append(torch.LongTensor(label))
# 统计图片数量
self.num_samples = len(self.boxes)
接收四个参数:图片路径,标注文件路径,训练模式,图像变换方法,做了如下操作:
对每一行文本数据进行处理:
-
去除字符串开头和结尾的空白字符,然后按照空白字符分割字符串并返回一个列表。
-
提取并存储图像文件名。
-
计算每个图像中的边界框(bbox)数量。
-
提取边界框的坐标信息(x, y, x2, y2)和类别信息(c),分别保存到 box 和 label 列表中。
将所有图片的边界框信息和类别信息分别存储到 self.boxes 和 self.labels 列表中。
统计图片的数量,并将结果保存到 self.num_samples 属性中。
获取一张图像
def __getitem__(self, idx):
# 获取一张图像
fname = self.fnames[idx]
# 读取这张图像
img = cv2.imread(os.path.join(self.root + fname))
# 拷贝一份,避免在对数据进行处理时对原始数据进行修改
boxes = self.boxes[idx].clone()
labels = self.labels[idx].clone()
"""
数据增强里面的各种变换用pytorch自带的transform是做不到的,因为对图片进行旋转、随即裁剪等会造成bbox的坐标也会发生变化,
所以需要自己来定义数据增强,这里推荐使用功albumentations更简单便捷
"""
if self.train:
img, boxes = self.random_flip(img, boxes)
img, boxes = self.randomScale(img, boxes)
img = self.randomBlur(img)
img = self.RandomBrightness(img)
# img = self.RandomHue(img)
# img = self.RandomSaturation(img)
img, boxes, labels = self.randomShift(img, boxes, labels)
# img, boxes, labels = self.randomCrop(img, boxes, labels)
# 获取图像高宽信息
h, w, _ = img.shape
# 归一化位置信息,.expand_as(boxes)的作用是将torch.Tensor([w, h, w, h])扩展成和boxes一样的维度,这样才能进行后面的归一化操作
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes) # 坐标归一化处理[0,1],为了方便训练
# cv2读取的图像是BGR,转成RGB
img = self.BGR2RGB(img)
# 减去均值,帮助网络更快地收敛并提高其性能
img = self.subMean(img, self.mean)
# 调整图像到统一大小
img = cv2.resize(img, (self.image_size, self.image_size))
# 将图片标签编码到7x7*30的向量,也就是我们yolov1的最终的输出形式,这个地方不了解的可以去看看yolov1原理
target = self.encoder(boxes, labels)
# 进行数据增强操作
for t in self.transform:
img = t(img)
# 返回一张图像和所有标注信息
return img, target
以下是代码的流程:
- 从文件名列表 self.fnames 中获取索引为 idx 的文件名。
- 使用 OpenCV(cv2)从文件中读取图像。
- 复制边界框(boxes)和标签(labels),以避免在处理数据时修改原始数据。
- 对于训练数据,执行数据增强操作,包括随机翻转、随机缩放、随机模糊、随机亮度调整和随机平移。这些操作同时会更新边界框的坐标。
- 获取图像的高度和宽度。
- 将边界框的坐标归一化到 [0, 1] 区间,以便于训练。
- 将图像从 OpenCV 默认的 BGR 格式转换为 RGB 格式。
- 减去图像的均值,以帮助网络更快地收敛并提高性能。
- 将图像调整为统一大小。
- 使用自定义的 encoder 函数将边界框和标签编码为 YOLOv1 网络的输出格式(7x7x30 的向量)。
- 对图像应用数据增强操作。
- 返回处理后的图像和编码后的标注信息。
编码
思考为什么有这步,上述论文中写出模型的输出为 7 × 7 × 30 7\times7\times30 7×7×30,我们这里将结果转化为与其相同的维度,使其可以进行运算损失函数
def encoder(self, boxes, labels):
# 网格大小
grid_num = 7
# 定义一个空的7*7*30的张量
target = torch.zeros((grid_num, grid_num, int(CLASS_NUM + 10)))
# 对网格进行归一化操作
cell_size = 1. / grid_num # 1/7
# 计算每个边框的宽高,wh是一个列表,里面存放的是每一张图的标注框的高宽,形式为[[h1,w1,[h2,w2]...]
wh = boxes[:, 2:] - boxes[:, :2]
# 每一张图的标注框的中心点坐标,cxcy也是一个列表,形式为[[cx1,cy1],[cx2,cy2]...]
cxcy = (boxes[:, 2:] + boxes[:, :2]) / 2
# 遍历每个每张图上的标注框信息,cxcy.size()[0]为标注框个数,即计算一张图上几个标注框
for i in range(cxcy.size()[0]):
# 取中心点坐标
cxcy_sample = cxcy[i]
# 中心点坐标获取后,计算这个标注框属于哪个grid cell,因为上面归一化了,这里要反归一化,还原回去,坐标从0开始,所以减1,注意坐标从左上角开始
ij = (cxcy_sample / cell_size).ceil() - 1
# 把标注框框所在的gird cell的的两个bounding box置信度全部置为1,多少行多少列,多少通道的值置为1
target[int(ij[1]), int(ij[0]), 4] = 1
target[int(ij[1]), int(ij[0]), 9] = 1
# 把标注框框所在的gird cell的的两个bounding box类别置为1,这样就完成了该标注框的label信息制作了
target[int(ij[1]), int(ij[0]), int(labels[i]) + 10] = 1
# 预测框的中心点在图像中的绝对坐标(xy),归一化的
xy = ij * cell_size
# 标注框的中心点坐标与grid cell左上角坐标的差值,这里又变为了相对于(7*7)的坐标了,目的应该是防止梯度消失,因为这两个值减完后太小了
delta_xy = (cxcy_sample - xy) / cell_size
# 坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例
# 将目标框的宽高信息存储到target张量中对应的位置上
target[int(ij[1]), int(ij[0]), 2:4] = wh[i] # w1,h1
# 目标框的中心坐标相对于所在的grid cell左上角的偏移量保存在target张量中对应的位置上,注意这里保存的是偏移量,并且是相对于(7*7)的坐标,而不是归一的1*1
target[int(ij[1]), int(ij[0]), :2] = delta_xy # x1,y1
# 两个bounding box,这里同上
target[int(ij[1]), int(ij[0]), 7:9] = wh[i] # w2,h2
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy # [5,7) 表示x2,y2
# 返回制作的标签,可以看到,除了有标注框所在得到位置,其他地方全为0
return target # (xc,yc) = 7*7 (w,h) = 1*1
这段代码定义了一个名为 encoder 的方法,用于将边界框 (bounding boxes) 和对应的类别标签 (labels) 编码为 YOLOv1 网络的输出格式。具体来说,它将目标信息编码为一个 7x7x(10 + 20) 的张量。以下是代码的详细解释:
- 设置网格数量
grid_num为 7。 - 初始化一个全零的 7x7x(10 + CLASS_NUM) 张量
target。 - 归一化网格大小,计算
cell_size。 - 计算每个边界框的宽度和高度,并将其存储在
wh列表中。 - 计算每个边界框的中心点坐标,并将其存储在
cxcy列表中。 - 遍历每个边界框,依次执行以下操作:
- 计算边界框的中心点所属的网格单元 (grid cell) 的索引
ij。 - 将目标框所在的 grid cell 的两个 bounding box 的置信度设置为 1。
- 将目标框所在 grid cell 的类别信息设置为 1。
- 计算预测框的中心点坐标(相对于整个图像的坐标)。
- 计算目标框的中心点坐标与所在 grid cell 左上角的偏移量,并将其除以
cell_size。 - 将目标框的宽高信息存储到
target张量的对应位置。 - 将目标框的中心坐标相对于所在 grid cell 左上角的偏移量存储到
target张量的对应位置。 - 对第二个 bounding box 执行相同的操作。
- 计算边界框的中心点所属的网格单元 (grid cell) 的索引
最后,返回编码后的 target 张量。
这个编码过程将原始的边界框和标签信息转换为 YOLOv1 网络所需要的格式,以便于训练和预测过程中的计算。
数据增强
def BGR2RGB(self, img):
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
def BGR2HSV(self, img):
return cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
def HSV2BGR(self, img):
return cv2.cvtColor(img, cv2.COLOR_HSV2BGR)
这段代码定义了三个方法,用于在不同的颜色空间之间转换图像。这些方法依赖于 OpenCV 库(cv2)实现颜色空间转换。以下是方法的详细解释:
-
BGR2RGB(self, img):此方法将输入图像从 BGR(蓝绿红)颜色空间转换为 RGB(红绿蓝)颜色空间。OpenCV 通常使用 BGR 格式表示图像,而其他库(如 PIL、Matplotlib 等)更常用 RGB 格式。因此,此转换在与其他库交互时可能会派上用场。 -
BGR2HSV(self, img):此方法将输入图像从 BGR 颜色空间转换为 HSV(色相、饱和度、亮度)颜色空间。在 HSV 颜色空间中,颜色信息与亮度信息是分离的,这使得 HSV 空间在某些图像处理任务(如颜色分割、跟踪等)中更为实用。 -
HSV2BGR(self, img):此方法将输入图像从 HSV 颜色空间转换回 BGR 颜色空间。在处理完 HSV 颜色空间中的图像后,可能需要将图像转换回 BGR 格式,以便于在 OpenCV 中进一步处理或显示。
def RandomBrightness(self, bgr):
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr)
h, s, v = cv2.split(hsv)
adjust = random.choice([0.5, 1.5])
v = v * adjust
v = np.clip(v, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h, s, v))
bgr = self.HSV2BGR(hsv)
return bgr
def RandomSaturation(self, bgr):
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr)
h, s, v = cv2.split(hsv)
adjust = random.choice([0.5, 1.5])
s = s * adjust
s = np.clip(s, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h, s, v))
bgr = self.HSV2BGR(hsv)
return bgr
def RandomHue(self, bgr):
if random.random() < 0.5:
hsv = self.BGR2HSV(bgr)
h, s, v = cv2.split(hsv)
adjust = random.choice([0.5, 1.5])
h = h * adjust
h = np.clip(h, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h, s, v))
bgr = self.HSV2BGR(hsv)
return bgr
def randomBlur(self, bgr):
if random.random() < 0.5:
bgr = cv2.blur(bgr, (5, 5))
return bgr
def randomShift(self, bgr, boxes, labels):
# 平移变换
center = (boxes[:, 2:] + boxes[:, :2]) / 2
if random.random() < 0.5:
height, width, c = bgr.shape
after_shfit_image = np.zeros((height, width, c), dtype=bgr.dtype)
after_shfit_image[:, :, :] = (104, 117, 123) # bgr
shift_x = random.uniform(-width * 0.2, width * 0.2)
shift_y = random.uniform(-height * 0.2, height * 0.2)
# print(bgr.shape,shift_x,shift_y)
# 原图像的平移
if shift_x >= 0 and shift_y >= 0:
after_shfit_image[int(shift_y):,
int(shift_x):,
:] = bgr[:height - int(shift_y),
:width - int(shift_x),
:]
elif shift_x >= 0 and shift_y < 0:
after_shfit_image[:height + int(shift_y),
int(shift_x):,
:] = bgr[-int(shift_y):,
:width - int(shift_x),
:]
elif shift_x < 0 and shift_y >= 0:
after_shfit_image[int(shift_y):, :width +
int(shift_x), :] = bgr[:height -
int(shift_y), -
int(shift_x):, :]
elif shift_x < 0 and shift_y < 0:
after_shfit_image[:height + int(shift_y), :width + int(
shift_x), :] = bgr[-int(shift_y):, -int(shift_x):, :]
shift_xy = torch.FloatTensor(
[[int(shift_x), int(shift_y)]]).expand_as(center)
center = center + shift_xy
mask1 = (center[:, 0] > 0) & (center[:, 0] < width)
mask2 = (center[:, 1] > 0) & (center[:, 1] < height)
mask = (mask1 & mask2).view(-1, 1)
boxes_in = boxes[mask.expand_as(boxes)].view(-1, 4)
if len(boxes_in) == 0:
return bgr, boxes, labels
box_shift = torch.FloatTensor(
[[int(shift_x), int(shift_y), int(shift_x), int(shift_y)]]).expand_as(boxes_in)
boxes_in = boxes_in + box_shift
labels_in = labels[mask.view(-1)]
return after_shfit_image, boxes_in, labels_in
return bgr, boxes, labels
def randomScale(self, bgr, boxes):
# 固定住高度,以0.8-1.2伸缩宽度,做图像形变
if random.random() < 0.5:
scale = random.uniform(0.8, 1.2)
height, width, c = bgr.shape
bgr = cv2.resize(bgr, (int(width * scale), height))
scale_tensor = torch.FloatTensor(
[[scale, 1, scale, 1]]).expand_as(boxes)
boxes = boxes * scale_tensor
return bgr, boxes
return bgr, boxes
def randomCrop(self, bgr, boxes, labels):
if random.random() < 0.5:
center = (boxes[:, 2:] + boxes[:, :2]) / 2
height, width, c = bgr.shape
h = random.uniform(0.6 * height, height)
w = random.uniform(0.6 * width, width)
x = random.uniform(0, width - w)
y = random.uniform(0, height - h)
x, y, h, w = int(x), int(y), int(h), int(w)
center = center - torch.FloatTensor([[x, y]]).expand_as(center)
mask1 = (center[:, 0] > 0) & (center[:, 0] < w)
mask2 = (center[:, 1] > 0) & (center[:, 1] < h)
mask = (mask1 & mask2).view(-1, 1)
boxes_in = boxes[mask.expand_as(boxes)].view(-1, 4)
if (len(boxes_in) == 0):
return bgr, boxes, labels
box_shift = torch.FloatTensor([[x, y, x, y]]).expand_as(boxes_in)
boxes_in = boxes_in - box_shift
boxes_in[:, 0] = boxes_in[:, 0].clamp_(min=0, max=w)
boxes_in[:, 2] = boxes_in[:, 2].clamp_(min=0, max=w)
boxes_in[:, 1] = boxes_in[:, 1].clamp_(min=0, max=h)
boxes_in[:, 3] = boxes_in[:, 3].clamp_(min=0, max=h)
labels_in = labels[mask.view(-1)]
img_croped = bgr[y:y + h, x:x + w, :]
return img_croped, boxes_in, labels_in
return bgr, boxes, labels
def subMean(self, bgr, mean):
mean = np.array(mean, dtype=np.float32)
bgr = bgr - mean
return bgr
def random_flip(self, im, boxes):
if random.random() < 0.5:
im_lr = np.fliplr(im).copy()
h, w, _ = im.shape
xmin = w - boxes[:, 2]
xmax = w - boxes[:, 0]
boxes[:, 0] = xmin
boxes[:, 2] = xmax
return im_lr, boxes
return im, boxes
def random_bright(self, im, delta=16):
alpha = random.random()
if alpha > 0.3:
im = im * alpha + random.randrange(-delta, delta)
im = im.clip(min=0, max=255).astype(np.uint8)
return im
这段代码定义了多个方法,用于对输入图像进行数据增强。数据增强是在训练过程中应用的一种技术,它通过对原始图像进行变换来创建新的训练样本,提高模型的泛化能力。以下是各个方法的详细解释:
-
RandomBrightness(self, bgr):此方法随机调整输入图像的亮度。首先,它将图像从 BGR 转换为 HSV 颜色空间。然后,它随机选择一个亮度调整因子(0.5 或 1.5),并将 V 通道(亮度)乘以该因子。最后,将调整后的 V 通道与原始的 H 和 S 通道组合,然后将结果从 HSV 转换回 BGR。 -
RandomSaturation(self, bgr):此方法随机调整输入图像的饱和度。与RandomBrightness类似,它首先将图像从 BGR 转换为 HSV 颜色空间。然后,它随机选择一个饱和度调整因子(0.5 或 1.5),并将 S 通道(饱和度)乘以该因子。最后,将调整后的 S 通道与原始的 H 和 V 通道组合,然后将结果从 HSV 转换回 BGR。 -
RandomHue(self, bgr):此方法随机调整输入图像的色彩。与前两个方法类似,它首先将图像从 BGR 转换为 HSV 颜色空间。然后,它随机选择一个色相调整因子(0.5 或 1.5),并将 H 通道(色相)乘以该因子。最后,将调整后的 H 通道与原始的 S 和 V 通道组合,然后将结果从 HSV 转换回 BGR。 -
randomBlur(self, bgr):此方法随机对输入图像进行模糊。它使用cv2.blur函数,应用一个 5x5 的均值滤波器来实现模糊效果。 -
randomShift(self, bgr, boxes, labels):此方法随机平移输入图像。它首先计算边界框的中心坐标,然后根据图像的高度和宽度随机选择一个平移量。接下来,它创建一个新的图像,并将原始图像平移到新图像上。最后,它根据平移量更新边界框的坐标,并返回平移后的图像、边界框和标签。 -
randomScale(self, bgr, boxes):此方法随机缩放输入图像。它固定高度,并在 0.8 到 1.2 的范围内随机选择一个伸缩因子来调整图像的宽度。然后,根据伸缩因子更新边界框的坐标。 -
randomCrop(self, bgr, boxes, labels):此方法随机裁剪输入图像。它首先随机选择一个裁剪区域,然后根据裁剪区域更新边界框的坐标。接下来,裁剪图像并返回裁剪后的图像、边界框和标签。 -
subMean(self, bgr, mean):此方法从输入图像中减去给定的均值。这是一种常用的图像预处理方法,用于去除图像中的全局亮度成分,使图像数据更接近零均值。 -
random_flip(self, im, boxes):此方法随机翻转输入图像。它使用numpy.fliplr函数实现左右翻转,并更新边界框的坐标以保持一致。
yoloLoss.py
计算损失函数,结构如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import warnings
warnings.filterwarnings('ignore') # 忽略警告消息
CLASS_NUM = 20 # (使用自己的数据集时需要更改)
class yoloLoss(nn.Module):
def __init__(self, S, B, l_coord, l_noobj):#初始化
def compute_iou(self, box1, box2): # box1(2,4) box2(1,4)#计算交并比
def forward(self, pred_tensor, target_tensor):#主要计算函数
上文提到损失函数为:
λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ( C i − C i ^ ) 2 + λ n o o j b ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j ( C i − C i ^ ) 2 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) − p i ^ ( c ) ) 2 ( 3 ) \lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{obj}_{ij}[(x_i-\hat{x}_i)^2+(y_i-\hat{y}_i)^2]\\+\lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{obj}_{ij}[(\sqrt{w_i}-\sqrt{\hat{w}_i})^2+(\sqrt{h_i}-\sqrt{\hat{h}_i})^2] \\ +\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{obj}_{ij}(C_i-\hat{C_i})^2\\ + \lambda_{noojb}\sum^{S^2}_{i=0}\sum^{B}_{j=0}1^{noobj}_{ij}(C_i-\hat{C_i})^2\\+\sum^{S^2}_{i=0}1^{obj}_{i}\sum_{c\in classes}(p_i(c)-\hat{p_i}(c))^2(3) λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2]+λcoordi=0∑S2j=0∑B1ijobj[(wi−w^i)2+(hi−h^i)2]+i=0∑S2j=0∑B1ijobj(Ci−Ci^)2+λnoojbi=0∑S2j=0∑B1ijnoobj(Ci−Ci^)2+i=0∑S21iobjc∈classes∑(pi(c)−pi^(c))2(3)
初始化
def __init__(self, S, B, l_coord, l_noobj):
# 一般而言 l_coord = 5 , l_noobj = 0.5
super(yoloLoss, self).__init__()
# 网格数
self.S = S # S = 7
# bounding box数量
self.B = B # B = 2
# 权重系数
self.l_coord = l_coord
# 权重系数
self.l_noobj = l_noobj
定义S,B和权重系数
计算交并比
首先介绍一下交并比,在计算机视觉中,交并比(Intersection over Union,IoU)是一种衡量目标检测算法预测边界框(bounding box)与实际边界框(ground truth)重合程度的指标。IoU 通常用于评估目标检测、分割等任务的模型性能。
IoU 的计算方法如下:
- 计算预测边界框与实际边界框的交集区域(intersection)面积。
- 计算预测边界框与实际边界框的并集区域(union)面积。
- 计算交集面积与并集面积的比值,即 IoU = (intersection) / (union)。
IoU 的取值范围为 0 到 1。当 IoU 为 0 时,表示预测边界框与实际边界框完全不重叠;当 IoU 为 1 时,表示预测边界框与实际边界框完全重合。因此,较高的 IoU 值表示目标检测算法具有较好的性能。
在评估模型性能时,通常会设置一个 IoU 阈值(例如 0.5),只有当预测边界框与实际边界框的 IoU 大于该阈值时,才认为预测是正确的。不同的阈值设置会影响模型的精度和召回率,从而影响模型的整体性能评估。
解释一下为什么两个box形状不一样,box1为预测结果,上文说一个网格允许预测B个检测框,所以box1的形状为[B,4],box2为真实值,只有一个值
def compute_iou(self, box1, box2): # box1(2,4) box2(1,4)
N = box1.size(0) # 2
M = box2.size(0) # 1
lt = torch.max( # 返回张量所有元素的最大值
# [N,2] -> [N,1,2] -> [N,M,2]
box1[:, :2].unsqueeze(1).expand(N, M, 2),
# [M,2] -> [1,M,2] -> [N,M,2]
box2[:, :2].unsqueeze(0).expand(N, M, 2),
)
rb = torch.min(
# [N,2] -> [N,1,2] -> [N,M,2]
box1[:, 2:].unsqueeze(1).expand(N, M, 2),
# [M,2] -> [1,M,2] -> [N,M,2]
box2[:, 2:].unsqueeze(0).expand(N, M, 2),
)
wh = rb - lt # [N,M,2]
wh[wh < 0] = 0 # clip at 0
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M] 重复面积
area1 = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1]) # [N,]
area2 = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1]) # [M,]
area1 = area1.unsqueeze(1).expand_as(inter) # [N,] -> [N,1] -> [N,M]
area2 = area2.unsqueeze(0).expand_as(inter) # [M,] -> [1,M] -> [N,M]
iou = inter / (area1 + area2 - inter)
# iou的形状是(2,1),里面存放的是两个框的iou的值
return iou # [2,1]
函数的输入参数box1和box2都是表示边界框的张量(Tensor),其中每个边界框用一个4元素数组表示:左上角的x, y坐标,和右下角的x, y坐标。box1的形状是(N, 4),box2的形状是(M, 4)。
代码里的主要步骤如下:
- 初始化两个变量
N和M分别表示box1中边界框的数量和box2中边界框的数量。 - 计算两组边界框的交集区域的左上角(lt)和右下角(rb)坐标。这里使用
torch.max和torch.min函数分别对应交集区域的左上角和右下角坐标。 - 计算交集区域的宽度(wh)和高度(wh)。
- 将宽度和高度中小于0的值设为0,表示没有交集。
- 计算交集区域的面积(inter)。
- 计算两组边界框的面积(area1和area2)。
- 将面积张量扩展为与交集区域相同的形状。
- 计算交并比(iou):交集区域的面积除以两组边界框的面积总和减去交集区域的面积。
- 返回交并比张量(iou),它的形状是(N, M),表示
box1的每个边界框与box2的每个边界框之间的交并比。
计算损失函数
def forward(self, pred_tensor, target_tensor):
'''
pred_tensor: (tensor) size(batchsize,7,7,30)
target_tensor: (tensor) size(batchsize,7,7,30),就是在yoloData中制作的标签
'''
# batchsize大小
N = pred_tensor.size()[0]
# 判断目标在哪个网格,输出B*7*7的矩阵,有目标的地方为True,其他地方为false,这里就用了第4位,第9位和第4位一样就没判断
coo_mask = target_tensor[:, :, :, 4] > 0
# 判断目标不在那个网格,输出B*7*7的矩阵,没有目标的地方为True,其他地方为false
noo_mask = target_tensor[:, :, :, 4] == 0
# 将 coo_mask tensor 在最后一个维度上增加一维,并将其扩展为与 target_tensor tensor 相同的形状,得到含物体的坐标等信息,大小为batchsize*7*7*30
coo_mask = coo_mask.unsqueeze(-1).expand_as(target_tensor)
# 将 noo_mask 在最后一个维度上增加一维,并将其扩展为与 target_tensor tensor 相同的形状,得到不含物体的坐标等信息,大小为batchsize*7*7*30
noo_mask = noo_mask.unsqueeze(-1).expand_as(target_tensor)
# 根据label的信息从预测的张量取出对应位置的网格的30个信息按照出现序号拼接成以一维张量,这里只取包含目标的
coo_pred = pred_tensor[coo_mask].view(-1, int(CLASS_NUM + 10))
# 所有的box的位置坐标和置信度放到box_pred中,塑造成X行5列(-1表示自动计算),一个box包含5个值
box_pred = coo_pred[:, :10].contiguous().view(-1, 5)
# 类别信息
class_pred = coo_pred[:, 10:] # [n_coord, 20]
# pred_tensor[coo_mask]把pred_tensor中有物体的那个网格对应的30个向量拿出来,这里对应的是label向量,只计算有目标的
coo_target = target_tensor[coo_mask].view(-1, int(CLASS_NUM + 10))
box_target = coo_target[:, :10].contiguous().view(-1, 5)
class_target = coo_target[:, 10:]
# 不包含物体grid ceil的置信度损失,这里是label的输出的向量。
noo_pred = pred_tensor[noo_mask].view(-1, int(CLASS_NUM + 10))
noo_target = target_tensor[noo_mask].view(-1, int(CLASS_NUM + 10))
# 创建一个跟noo_pred相同形状的张量,形状为(x,30),里面都是全0或全1,再使用bool将里面的0或1转为true和false
noo_pred_mask = torch.cuda.ByteTensor(noo_pred.size()).bool()
# 把创建的noo_pred_mask全部改成false,因为这里对应的是没有目标的张量
noo_pred_mask.zero_()
# 把不包含目标的张量的置信度位置置为1
noo_pred_mask[:, 4] = 1
noo_pred_mask[:, 9] = 1
# 跟上面的pred_tensor[coo_mask]一个意思,把不包含目标的置信度提取出来拼接成一维张量
noo_pred_c = noo_pred[noo_pred_mask]
# 同noo_pred_c
noo_target_c = noo_target[noo_pred_mask]
# 计算loss,让预测的值越小越好,因为不包含目标,置信度越为0越好
nooobj_loss = F.mse_loss(noo_pred_c, noo_target_c, size_average=False) # 均方误差
# 注意:上面计算的不包含目标的损失只计算了置信度,其他的都没管
"""
计算包含目标的损失:位置损失+类别损失
"""
# 先创建两个张量用于后面匹配预测的两个编辑框:一个负责预测,一个不负责预测
# 创建一跟box_target相同的张量,这里用来匹配后面负责预测的框
coo_response_mask = torch.cuda.ByteTensor(box_target.size()).bool()
# 全部置为False
coo_response_mask.zero_() # 全部元素置False
# 创建一跟box_target相同的张量,这里用来匹配不负责预测的框
no_coo_response_mask = torch.cuda.ByteTensor(box_target.size()).bool()
# 全部置为False
no_coo_response_mask.zero_()
# 创建一个全0张量,匹配后面的预测框的iou
box_target_iou = torch.zeros(box_target.size()).cuda()
# 遍历每一个标注框,每次遍历两个是因为一个标注框对应有两个预测框要跟他匹配,box1 = 预测框 box2 = ground truth
# box_target.size()[0]:有多少bbox,并且一次取两个bbox,因为两个bbox才是一个完整的预测框
for i in range(0, box_target.size()[0], 2): #
# 第i个grid ceil对应的两个bbox
box1 = box_pred[i:i + 2]
# 创建一个和box1大小(2,5)相同的浮点型张量用来存储坐标,这里代码使用的torch版本可能比较老,其实Variable可以省略的
box1_xyxy = Variable(torch.FloatTensor(box1.size()))
# box1_xyxy[:, :2]为预测框中心点坐标相对于所在grid cell左上角的偏移,前面在数据处理的时候讲过label里面的值是归一化为(0-7)的,
# 因此这里得反归一化成跟宽高一样比例,归一化到(0-1),减去宽高的一半得到预测框的左上角的坐标相对于他所在的grid cell的左上角的偏移量
box1_xyxy[:, :2] = box1[:, :2] / float(self.S) - 0.5 * box1[:, 2:4]
# 计算右下角坐标相对于预测框所在的grid cell的左上角的偏移量
box1_xyxy[:, 2:4] = box1[:, :2] / float(self.S) + 0.5 * box1[:, 2:4]
# target中的两个框的目标信息是一模一样的,这里取其中一个就行了
box2 = box_target[i].view(-1, 5)
box2_xyxy = Variable(torch.FloatTensor(box2.size()))
box2_xyxy[:, :2] = box2[:, :2] / float(self.S) - 0.5 * box2[:, 2:4]
box2_xyxy[:, 2:4] = box2[:, :2] / float(self.S) + 0.5 * box2[:, 2:4]
# 计算两个预测框与标注框的IoU值,返回计算结果,是个列表
iou = self.compute_iou(box1_xyxy[:, :4], box2_xyxy[:, :4])
# 通过max()函数获取与gt最大的框的iou和索引号(第几个框)
max_iou, max_index = iou.max(0)
# 将max_index放到GPU上
max_index = max_index.data.cuda()
# 保留IoU比较大的那个框
coo_response_mask[i + max_index] = 1 # IOU最大的bbox
# 舍去的bbox,两个框单独标记为1,分开存放,方便下面计算
no_coo_response_mask[i + 1 - max_index] = 1
# 将预测框比较大的IoU的那个框保存在box_target_iou中,
# 其中i + max_index表示当前预测框对应的位置,torch.LongTensor([4]).cuda()表示在box_target_iou中存储最大IoU的值的位置。
box_target_iou[i + max_index, torch.LongTensor([4]).cuda()] = max_iou.data.cuda()
# 放到GPU上
box_target_iou = Variable(box_target_iou).cuda()
# 负责预测物体的预测框的位置信息(含物体的grid ceil的两个bbox与ground truth的IOU较大的一方)
box_pred_response = box_pred[coo_response_mask].view(-1, 5)
# 标注信息,拿出来一个计算就行了,因为两个信息一模一样
box_target_response_iou = box_target_iou[coo_response_mask].view(-1, 5)
# IOU较小的一方
no_box_pred_response = box_pred[no_coo_response_mask].view(-1, 5)
no_box_target_response_iou = box_target_iou[no_coo_response_mask].view(-1, 5)
# 不负责预测物体的置信度置为0,本来就是0,这里有点多此一举
no_box_target_response_iou[:, 4] = 0
# 负责预测物体的标注框对应的label的信息
box_target_response = box_target[coo_response_mask].view(-1, 5)
# 包含物的体grid ceil中IOU较大的bbox置信度损失
contain_loss = F.mse_loss(box_pred_response[:, 4], box_target_response_iou[:, 4], size_average=False)
# 不包含物体的grid ceil中舍去的bbox的置信度损失
no_contain_loss = F.mse_loss(no_box_pred_response[:, 4], no_box_target_response_iou[:, 4], size_average=False)
# 负责预测物体的预测框的位置损失
loc_loss = F.mse_loss(box_pred_response[:, :2], box_target_response[:, :2], size_average=False) + F.mse_loss(
torch.sqrt(box_pred_response[:, 2:4]), torch.sqrt(box_target_response[:, 2:4]), size_average=False)
# 负责预测物体的所在grid cell的类别损失
class_loss = F.mse_loss(class_pred, class_target, size_average=False)
# 计算总损失,这里有个权重
return (self.l_coord * loc_loss + contain_loss + self.l_noobj * (nooobj_loss + no_contain_loss) + class_loss) / N
new_resnet.py
这部分网络结构,使用了ResNet50结构,具体了解ResNet残差网络,请点击我的另外一篇文章:点我地址
import torch
from torch.nn import Sequential, Conv2d, MaxPool2d, ReLU, BatchNorm2d
from torch import nn
from torch.utils import model_zoo
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth'}
# 预测类别
CLASS_NUM = 20
class Bottleneck(nn.Module): # 定义基本块
def __init__(self, in_channel, out_channel, stride, downsample):
super(Bottleneck, self).__init__()
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.in_channel = in_channel
self.out_channel = out_channel
self.bottleneck = Sequential(
Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False),
BatchNorm2d(out_channel),
ReLU(inplace=True),
Conv2d(out_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False),
BatchNorm2d(out_channel),
ReLU(inplace=True),
Conv2d(out_channel, out_channel * 4, kernel_size=1, stride=stride[2], padding=0, bias=False),
BatchNorm2d(out_channel * 4),
)
if self.downsample is False: # 如果 downsample = True则为Conv_Block 为False为Identity_Block
self.shortcut = Sequential()
else:
self.shortcut = Sequential(
Conv2d(self.in_channel, self.out_channel * 4, kernel_size=1, stride=stride[0], bias=False),
BatchNorm2d(self.out_channel * 4)
)
def forward(self, x):
out = self.bottleneck(x)
out += self.shortcut(x)
out = self.relu(out)
return out
class output_net(nn.Module):
# no expansion
# dilation = 2
# type B use 1x1 conv
expansion = 1
def __init__(self, in_planes, planes, stride=1, block_type='A'):
super(output_net, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2, bias=False, dilation=2)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.downsample = nn.Sequential()
self.relu = nn.ReLU(inplace=True)
if stride != 1 or in_planes != self.expansion * planes or block_type == 'B':
self.downsample = nn.Sequential(
nn.Conv2d(
in_planes,
self.expansion * planes,
kernel_size=1,
stride=stride,
bias=False),
nn.BatchNorm2d(self.expansion * planes))
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.downsample(x)
out = self.relu(out)
return out
class ResNet50(nn.Module):
def __init__(self, block):
super(ResNet50, self).__init__()
self.block = block
self.layer0 = Sequential(
Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
BatchNorm2d(64),
ReLU(inplace=True),
MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.layer1 = self.make_layer(self.block, channel=[64, 64], stride1=[1, 1, 1], stride2=[1, 1, 1], n_re=3)
self.layer2 = self.make_layer(self.block, channel=[256, 128], stride1=[2, 1, 1], stride2=[1, 1, 1], n_re=4)
self.layer3 = self.make_layer(self.block, channel=[512, 256], stride1=[2, 1, 1], stride2=[1, 1, 1], n_re=6)
self.layer4 = self.make_layer(self.block, channel=[1024, 512], stride1=[2, 1, 1], stride2=[1, 1, 1], n_re=3)
# 调整输出通道
self.layer5 = self._make_output_layer(in_channels=2048)
# 调整尺寸
self.avgpool = nn.AvgPool2d(2) # kernel_size = 2 , stride = 2
# 得到最后输出张量
self.conv_end = nn.Conv2d(256, int(CLASS_NUM + 10), kernel_size=3, stride=1, padding=1, bias=False)
self.bn_end = nn.BatchNorm2d(int(CLASS_NUM + 10))
def make_layer(self, block, channel, stride1, stride2, n_re):
layers = []
for num_layer in range(0, n_re):
if num_layer == 0:
layers.append(block(channel[0], channel[1], stride1, downsample=True))
else:
layers.append(block(channel[1]*4, channel[1], stride2, downsample=False))
return Sequential(*layers)
def _make_output_layer(self, in_channels):
layers = []
layers.append(
output_net(
in_planes=in_channels,
planes=256,
block_type='B'))
layers.append(
output_net(
in_planes=256,
planes=256,
block_type='A'))
layers.append(
output_net(
in_planes=256,
planes=256,
block_type='A'))
return nn.Sequential(*layers)
def forward(self, x):
# print(x.shape) # 3*448*448
out = self.layer0(x)
# print(out.shape) # 64*112*112
out = self.layer1(out)
# print(out.shape) # 256*112*112
out = self.layer2(out)
# print(out.shape) # 512*56*56
out = self.layer3(out)
# print(out.shape) # 1024*28*28
out = self.layer4(out) # 2048*14*14
out = self.layer5(out) # batch_size*256*14*14
out = self.avgpool(out) # batch_size*256*7*7
out = self.conv_end(out) # batch_size*30*7*7
out = self.bn_end(out)
out = torch.sigmoid(out)
out = out.permute(0, 2, 3, 1) # bitch_size*7*7*30
return out
def resnet50(pretrained=False):
model = ResNet50(Bottleneck)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
主要说一下output层:主要包括三个卷积层 conv1、conv2 和 conv3,以及相应的批量归一化层 bn1、bn2 和 bn3。此外,还包括一个下采样层 downsample 和 ReLU 激活函数。
以下是代码的详细解释:
-
expansion类变量:设置网络的输出通道扩展因子,默认值为 1。 -
__init__方法:定义网络结构和参数。接受输入参数:in_planes:输入张量的通道数。planes:中间卷积层的通道数。stride:conv2的卷积层的步长,默认值为 1。block_type:模块类型,可以是 ‘A’ 或 ‘B’。当类型为 ‘B’ 时,使用 1x1 卷积进行下采样。
-
在
__init__方法中,定义了三个卷积层和相应的批量归一化层:conv1:1x1 卷积层,接受in_planes通道输入,输出planes通道。bn1:对应于conv1的批量归一化层。conv2:3x3 卷积层,接受planes通道输入,输出planes通道。具有步长stride、填充 2 和空洞卷积扩张系数 2。bn2:对应于conv2的批量归一化层。conv3:1x1 卷积层,接受planes通道输入,输出expansion * planes通道。bn3:对应于conv3的批量归一化层。
-
定义了一个下采样层
downsample,它是一个空的nn.Sequential()容器。当stride不等于 1 或in_planes不等于expansion * planes或block_type等于 ‘B’ 时,为其添加一个 1x1 卷积层和一个相应的批量归一化层。 -
在
forward方法中,定义了模块的前向传播过程。输入张量x依次通过conv1、bn1、ReLU 激活、conv2、bn2、ReLU 激活、conv3和bn3层。然后将结果与通过downsample层的输入张量相加,最后通过 ReLU 激活函数输出。
Train.py
这部分代码负责训练
导包和某些变量定义
from yoloData import yoloDataset
from yoloLoss import yoloLoss
from new_resnet import resnet50
from torchvision import models
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch
device = 'cuda'
file_root = 'VOCdevkit/VOC2007/JPEGImages/'
batch_size = 4
learning_rate = 0.001
num_epochs = 100
数据集
# 自定义训练数据集
train_dataset = yoloDataset(img_root=file_root, list_file='voctrain.txt', train=True, transform=[transforms.ToTensor()])
# 加载自定义的训练数据集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
# 自定义测试数据集
test_dataset = yoloDataset(img_root=file_root, list_file='voctest.txt', train=False, transform=[transforms.ToTensor()])
# 加载自定义的测试数据集
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
print('the dataset has %d images' % (len(train_dataset)))
处理预训练模型
"""
下面这段代码主要适用于迁移学习训练,可以将预训练的ResNet-50模型的参数赋值给新的网络,以加快训练速度和提高准确性。
"""
# 创建改编的ResNet50
net = resnet50()
# 放到GPU上
net = net.cuda()
# 直接使用pytorch加载resnet50,带预训练权重
resnet = models.resnet50(pretrained=True) # torchvison库中的网络
# 获取resnet的训练参数
new_state_dict = resnet.state_dict()
# 获取刚创建的改编的resnet50()的参数
op = net.state_dict()
# 无论名称是否相同都可以使用
for new_state_dict_num, new_state_dict_value in enumerate(new_state_dict.values()):
# op.keys()表示获取模型参数字典中的所有键值
for op_num, op_key in enumerate(op.keys()):
# 320个key中不需要最后的全连接层的两个参数
if op_num == new_state_dict_num and op_num <= 317:
op[op_key] = new_state_dict_value
# 将预训练好的参数放入改编的ResNet的网络中,加快训练速度
net.load_state_dict(op)
损失函数
# 创建损失函数
criterion = yoloLoss(7, 2, 5, 0.5)
# 放到GPU上
criterion = criterion.to(device)
# 训练前需要加入的语句,一般有Dropout()的时候要加
net.train()
优化器
# 里面存字典
params = []
# net.named_parameters()是一个PyTorch函数,它返回一个包含模型中所有需要学习的参数(即权重和偏置项)及其名称的迭代器。
params_dict = dict(net.named_parameters())
for key, value in params_dict.items():
# 把字典放到列表中,这个“+”可以理解为append
params += [{
'params': [value], 'lr':learning_rate}]
# 定义优化器 “随机梯度下降”
optimizer = torch.optim.SGD(
# 上面已经将模型参数打包成字典了,这里不需要用net.parameters()了
params,
# 学习率
lr=learning_rate,
# 动量
momentum=0.9,
# 正则化
weight_decay=5e-4)
这里解释下自己定义参数列表和直接使用net.parameter()的区别:
在大多数情况下,直接使用net.parameters()和将模型参数放到字典中是没有区别的,
因为net.parameters()本身就是一个包含模型所有参数的列表。
但是,如果我们想要对不同的参数设置不同的超参数,那么将模型参数放到字典中会更加方便。
使用net.parameters()的话,我们需要手动区分不同的参数,
再分别进行超参数的设置。而将模型参数放到字典中后,我们可以直接对每个参数设置对应的超参数,更加简洁和灵活。
举个例子,如果我们想要对卷积层和全连接层设置不同的学习率,使用net.parameters()的话,
我们需要手动区分哪些参数属于卷积层,哪些参数属于全连接层,
然后分别对这两部分参数设置不同的学习率。而将模型参数放到字典中后,
我们可以直接对卷积层和全连接层的参数分别设置不同的学习率,更加方便和清晰。
开始训练
# 开始训练
for epoch in range(num_epochs):
# 这个地方形成习惯,因为网络可能会用到Dropout和batchnorm
net.train()
# 调整学习率
if epoch == 60:
learning_rate = 0.0001
if epoch == 80:
learning_rate = 0.00001
# optimizer.param_groups 返回一个包含优化器参数分组信息的列表,每个分组是一个字典,主要包含以下键值:
# params:当前参数分组中需要更新的参数列表,如网络的权重,偏置等。
# lr:当前参数分组的学习率。就是我们要提取更新的
# momentum:当前参数分组的动量参数。
# weight_decay:当前参数分组的权重衰减参数。
for param_group in optimizer.param_groups:
param_group['lr'] = learning_rate # 更改全部的学习率
print('\n\nStarting epoch %d / %d' % (epoch + 1, num_epochs))
print('Learning Rate for this epoch: {}'.format(learning_rate))
# 计算损失
total_loss = 0.
# 开始迭代训练
for i, (images, target) in enumerate(train_loader):
images, target = images.cuda(), target.cuda()
pred = net(images)
# 创建损失函数
loss = criterion(pred, target)
total_loss += loss.item()
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if (i + 1) % 5 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f, average_loss: %.4f' % (epoch +1, num_epochs, i + 1, len(train_loader), loss.item(), total_loss / (i + 1)))
# 开始测试
validation_loss = 0.0
net.eval()
for i, (images, target) in enumerate(test_loader):
images, target = images.cuda(), target.cuda()
# 输入图像
pred = net(images)
# 计算损失
loss = criterion(pred, target)
# 累加损失
validation_loss += loss.item()
# 计算平均loss
validation_loss /= len(test_loader)
best_test_loss = validation_loss
print('get best test loss %.5f' % best_test_loss)
# 保存模型参数
torch.save(net.state_dict(), 'yolo.pth')
predict.py
预测部分
导包和某些变量的定义
import numpy as np
import torch
from PIL import ImageFont, ImageDraw
from cv2 import cv2
from matplotlib import pyplot as plt
# import cv2
from torchvision.transforms import ToTensor
from draw_rectangle import draw
from new_resnet import resnet50
# voc数据集的类别信息,这里转换成字典形式
classes = {
"aeroplane": 0, "bicycle": 1, "bird": 2, "boat": 3, "bottle": 4, "bus": 5, "car": 6, "cat": 7, "chair": 8, "cow": 9, "diningtable": 10, "dog": 11, "horse": 12, "motorbike": 13, "person": 14, "pottedplant": 15, "sheep": 16, "sofa": 17, "train": 18, "tvmonitor": 19}
# 测试图片的路径
img_root = "D:\\program\\Object_detection\\YOLOV1-pytorch-main\\test.jpg"
# 设置置信度
confident = 0.2
# 设置iou阈值
iou_con = 0.4
# 类别信息,这里写的都是voc数据集的,如果是自己的数据集需要更改
VOC_CLASSES = (
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
# 类别总数:20
CLASS_NUM = len(VOC_CLASSES)
加载模型
# 网络模型
model = resnet50()
# 加载权重,就是在train.py中训练生成的权重文件yolo.pth
model.load_state_dict(torch.load("D:\\program\\Object_detection\\YOLOV1-pytorch-main\\yolo.pth"))
# 测试模式
model.eval()
预测函数
结构如下:
class Pred():
# 参数初始化
def __init__(self, model, img_root):#初始化
def result(self):#获取结果,画框
def Decode(self, result):#解码获取标准格式的结果
def NMS(self, bbox, iou_con=iou_con):#非极大值抑制处理去除冗余边界框
初始化
定义模型和图片路径
def __init__(self, model, img_root):
self.model = model
self.img_root = img_root
result
def result(self):
# 读取测试的图像
img = cv2.imread(self.img_root)
# 获取高宽信息
h, w, _ = img.shape
# 调整图像大小
image = cv2.resize(img, (448, 448))
# CV2读取的图像是BGR,这里转回RGB模式
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 图像均值
mean = (123, 117, 104) # RGB
# 减去均值进行标准化操作
img = img - np.array(mean, dtype=np.float32)
# 创建数据增强函数
transform = ToTensor()
# 图像转为tensor,因为cv2读取的图像是numpy格式
img = transform(img)
# 输入要求是BCHW,加一个batch维度
img = img.unsqueeze(0)
# 图像输入模型,返回值为1*7*7*30的张量
Result = self.model(img)
# 获取目标的边框信息
bbox = self.Decode(Result)
# 非极大值抑制处理
bboxes = self.NMS(bbox) # n*6 bbox坐标是基于7*7网格需要将其转换成448
# draw(image, bboxes, classes)
if len(bboxes) == 0:
print("未识别到任何物体")
print("尝试减小 confident 以及 iou_con")
print("也可能是由于训练不充分,可在训练时将epoch增大")
for i in range(0, len(bboxes)): # bbox坐标将其转换为原图像的分辨率
bboxes[i][0] = bboxes[i][0] * 64
bboxes[i][1] = bboxes[i][1] * 64
bboxes[i][2] = bboxes[i][2] * 64
bboxes[i][3] = bboxes[i][3] * 64
x1 = bboxes[i][0].item() # 后面加item()是因为画框时输入的数据不可为tensor类型
x2 = bboxes[i][1].item()
y1 = bboxes[i][2].item()
y2 = bboxes[i][3].item()
class_name = bboxes[i][5].item()
print(x1, x2, y1, y2, VOC_CLASSES[int(class_name)])
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (144, 144, 255)) # 画框
plt.imsave('test_001.jpg', image)
这段代码定义了一个名为 result 的方法,用于读取图像、预处理图像、将图像输入到模型中、解码模型输出、进行非极大值抑制(NMS)处理,并在图像上绘制边界框。
以下是代码的详细解释:
- 使用 OpenCV 的
cv2.imread读取图像文件。 - 获取图像的高度和宽度信息。
- 将图像调整为大小为 (448, 448)。
- 将图像从 BGR 格式转换为 RGB 格式。
- 将图像减去均值以进行标准化操作。
- 使用自定义的
ToTensor函数将图像转换为 PyTorch 张量。 - 为张量添加 batch 维度,使其形状为 BCHW。
- 将张量输入到模型中,获得模型输出结果。
- 使用
Decode方法解码模型输出,获取目标的边界框信息。 - 对解码后的边界框应用 NMS 处理。
- 如果未检测到任何物体,打印提示信息。
- 遍历所有检测到的边界框,将坐标从 7x7 网格空间转换到原始图像空间。
- 提取边界框的坐标和类别信息。
- 使用 OpenCV 的
cv2.rectangle函数在图像上绘制边界框。 - 使用
plt.imsave保存绘制边界框后的图像。
Decode
def Decode(self, result):
# 去掉batch维度
result = result.squeeze()
# 提取置信度信息,并在最后一个维度增加一维,跟后面匹配result[:, :, 4]的形状为7*7,最后变为7*7*1
grid_ceil1 = result[:, :, 4].unsqueeze(2)
# 同上
grid_ceil2 = result[:, :, 9].unsqueeze(2)
# 两个置信度信息按照维度2拼接
grid_ceil_con = torch.cat((grid_ceil1, grid_ceil2), 2)
# 按照第二个维度进行最大值求取,一个grid ceil两个bbox,两个confidence,也就是找置信度比较大的那个,形状都是7*7
grid_ceil_con, grid_ceil_index = grid_ceil_con.max(2)
# 找出一个gird cell中预测类别最大的物体的索引和预测条件类别概率
class_p, class_index = result[:, :, 10:].max(2)
# 计算出物体的真实概率,类别最大的物体乘上置信度比较大的那个框得到最终的真实物体类别概率
class_confidence = class_p * grid_ceil_con
# 定义一个张量,记录位置信息
bbox_info = torch.zeros(7, 7, 6)
for i in range(0, 7):
for j in range(0, 7):
# 获取置信度比较大的索引位置
bbox_index = grid_ceil_index[i, j]
# 把置信度比较大的那个框的位置信息保存到bbox_info中,另一个直接抛弃
bbox_info[i, j, :5] = result[i, j, (bbox_index * 5):(bbox_index+1) * 5]
# 真实目标概率
bbox_info[:, :, 4] = class_confidence
# 类别信息
bbox_info[:, :, 5] = class_index
# 返回预测的结果,7*7*6 6 = bbox4个信息+类别概率+类别代号
return bbox_info
非极大值抑制处理
非极大值抑制(Non-Maximum Suppression,NMS)是计算机视觉中一种用于去除冗余边界框(bounding box)的技术。它主要用于目标检测任务,在物体检测模型输出多个相似或重叠边界框时,通过 NMS 可以选择最有可能代表实际物体的边界框。
NMS 通过以下步骤执行:
- 对所有预测边界框的置信度(confidence score)进行排序,从高到低排列。
- 选择置信度最高的边界框,并将其添加到最终结果列表中。
- 计算置信度最高的边界框与其余边界框的交并比(IoU,Intersection over Union)。
- 移除与置信度最高的边界框具有高于设定阈值的 IoU 的所有边界框。
- 重复步骤2-4,直到所有边界框都被处理或移除。
通过这个过程,NMS 有效地去除了相似或重叠的边界框,保留了具有高置信度的独特边界框。这样可以减少检测结果中的冗余信息,并提高模型在目标检测任务中的性能。
需要注意的是,NMS 阈值的选择对结果有很大影响。较低的阈值可以保留更多不重叠的边界框,但可能导致检测到的物体较少;较高的阈值可能导致更多重叠边界框被保留,但可能增加误报。根据具体应用场景和需求,可以调整 NMS 阈值以获得最佳性能。
def NMS(self, bbox, iou_con=iou_con):
for i in range(0, 7):
for j in range(0, 7):
# xc = bbox[i, j, 0]
# yc = bbox[i, j, 1]
# w = bbox[i, j, 2] * 7
# h = bbox[i, j, 3] * 7
# Xc = i + xc
# Yc = j + yc
# xmin = Xc - w/2
# xmax = Xc + w/2
# ymin = Yc - h/2
# ymax = Yc + h/2
# 注意,目前bbox的四个坐标是以grid ceil的左上角为坐标原点,而且单位不一致中心点偏移的坐标是归一化为(0-7),宽高是(0-7),,单位不一致,全部归一化为(0-7)
# 计算预测框的左上角右下角相对于7*7网格的位置
xmin = j + bbox[i, j, 0] - bbox[i, j, 2] * 7 / 2 # xmin
xmax = j + bbox[i, j, 0] + bbox[i, j, 2] * 7 / 2 # xmax
ymin = i + bbox[i, j, 1] - bbox[i, j, 3] * 7 / 2 # ymin
ymax = i + bbox[i, j, 1] + bbox[i, j, 3] * 7 / 2 # ymax
bbox[i, j, 0] = xmin
bbox[i, j, 1] = xmax
bbox[i, j, 2] = ymin
bbox[i, j, 3] = ymax
# 调整形状,bbox本来就是(49*6),这里感觉没必要
bbox = bbox.view(-1, 6)
# 存放最终需要保留的预测框
bboxes = []
# 取出每个gird cell中的类别信息,返回一个列表
ori_class_index = bbox[:, 5]
# 按照类别进行排序,从高到低,返回的是排序后的类别列表和对应的索引位置,如下:
"""
类别排序
tensor([ 1., 1., 1., 1., 1., 1., 1., 2., 2., 2., 2., 2., 2., 2.,
3., 3., 3., 4., 4., 4., 4., 5., 5., 5., 6., 6., 6., 6.,
6., 6., 6., 6., 7., 8., 8., 8., 8., 8., 14., 14., 14., 14.,
14., 14., 14., 15., 15., 16., 17.], grad_fn=<SortBackward0>)
位置索引
tensor([48, 47, 46, 45, 44, 43, 42, 7, 8, 22, 11, 16, 14, 15, 24, 20, 1, 2,
6, 0, 13, 23, 25, 27, 32, 39, 38, 35, 33, 31, 30, 28, 3, 26, 10, 19,
9, 12, 29, 41, 40, 21, 37, 36, 34, 18, 17, 5, 4])
"""
class_index, class_order = ori_class_index.sort(dim=0, descending=False)
# class_index是一个tensor,这里把他转为列表形式
class_index = class_index.tolist()
# 根据排序后的索引更改bbox排列顺序
bbox = bbox[class_order, :]
a = 0
for i in range(0, CLASS_NUM):
# 统计目标数量,即某个类别出现在grid cell中的次数
num = class_index.count(i)
# 预测框中没有这个类别就直接跳过
if num == 0:
continue
# 提取同一类别的所有信息
x = bbox[a:a+num, :]
# 提取真实类别概率信息
score = x[:, 4]
# 提取出来的某一类别按照真实类别概率信息高度排序,递减
score_index, score_order = score.sort(dim=0, descending=True)
# 根据排序后的结果更改真实类别的概率排布
y = x[score_order, :]
# 先看排在第一位的物体的概率是否大有给定的阈值,不满足就不看这个类别了,丢弃全部的预测框
if y[0, 4] >= confident:
for k in range(0, num):
# 真实类别概率,排序后的
y_score = y[:, 4]
# 对真实类别概率重新排序,保证排列顺序依照递减,其实跟上面一样的,多此一举
_, y_score_order = y_score.sort(dim=0, descending=True)
y = y[y_score_order, :]
# 判断概率是否大于0
if y[k, 4] > 0:
# 计算预测框的面积
area0 = (y[k, 1] - y[k, 0]) * (y[k, 3] - y[k, 2])
for j in range(k+1, num):
# 计算剩余的预测框的面积
area1 = (y[j, 1] - y[j, 0]) * (y[j, 3] - y[j, 2])
x1 = max(y[k, 0], y[j, 0])
x2 = min(y[k, 1], y[j, 1])
y1 = max(y[k, 2], y[j, 2])
y2 = min(y[k, 3], y[j, 3])
w = x2 - x1
h = y2 - y1
if w < 0 or h < 0:
w = 0
h = 0
inter = w * h
# 计算与真实目标概率最大的那个框的iou
iou = inter / (area0 + area1 - inter)
# iou大于一定值则认为两个bbox识别了同一物体删除置信度较小的bbox
# 同时物体类别概率小于一定值也认为不包含物体
if iou >= iou_con or y[j, 4] < confident:
y[j, 4] = 0
for mask in range(0, num):
if y[mask, 4] > 0:
bboxes.append(y[mask])
# 进入下个类别
a = num + a
# 返回最终预测的框
return bboxes