继上篇介绍的集成学习大框架后https://blog.csdn.net/weixin_42001089/article/details/84935462
本文介绍其框架里面的GBDT。
原论文:https://statweb.stanford.edu/~jhf/ftp/trebst.pdf
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
首先举一个简单例子来生动形象的看一下其思想,拿预测年龄来讲:
假设小明的年龄是20岁,我们通过训练第一个弱分类器(目标值是20)得到预测结果比如是11岁,那么差值(残差)是9岁,那么在训练下一个弱分类器将9作为目标值,假如第二个弱分类器预测的结果是12,那么差值(残差)是-3岁,那么在训练第三个弱分类器将-3作为目标值,假如正确预测即-3。
那么最终预测结果便是三个弱分类器预测结果线性组合即相加11+12-3=20
这就是GBDT的过程,只不过GBDT将这里的残差是换成了梯度,当采用 MSE作为loss function时,梯度正好就是残差,两者一致,从这一方面看,选用残差作为梯度的这一种方法只不过是GBDT在选用了MSE作为loss function所导致的一种特例,所以总体思想就是如此,只不过随着loss function选取的不同,梯度的具体表达式也随之换一换即可。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
以上只是很简单的一个比如,具体还有很多细节在里面比如决策树的构建,学习率等等,下面我们开始讲解
对于GBDT我们先整体上从三方面来剖析其通用框架:

Regression Decistion Tree即GBDT中的DT
Gradient Boosting即GBDT中的GB,也是GBDT的核心
Shrinkage
然后再看其具体解决回归,二分类以及多分类问题。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
DT决策树
首先说明一棵树是由分裂节点和叶子节点的输出值组成的,即可以将其比作是一个分段函数,其是由分段点和段内函数值组成的。
注意GBDT中的DT本质上并不是决策树(ID3、C4.5、CART等等)而是回归树,为什么呢?
因为我们最终的预测结果是多个弱分类器的预测结果线性相加,回归树预测结果是连续值,最后相加才有意义,就像上面举的那个例子,如果采用真真的回归树,那么每个弱分类器的预测结果(比如二分类)就只有1,0,一系列0和1相加显然没有意义,或者说远没有连续值更能包含更多的信息。那么GBDT到底是怎么解决分类问题呢?毕竟分类问题最后结果要的是类别,很简单就采用回归树,对于二分类我们就将0和1看做是回归问题中的y,只不过其采用的loss function函数logloss,对于对分类问题采用one-hot的形式后续会详细介绍。
其次需要注意的就是在构建回归树的过程中分支节点的选取及取值(对比分类树来看)
1)回归树不是像分类树那样采用最大熵来作为划分标准,而是采用均方差
2)回归树的每个叶子节点得到的不是像分类树那样的样本计数,而是属于这个叶子节点所有样本的平均值(当然根据的loss function这里具体也会不同,下面会看到)。
总之记住一句话DT本质是回归树
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GB梯度提升
关于梯度的知识这里不做理论介绍,不懂的请自行查阅资料,其实也很简单,而且也是深度学习中必不可少的利用工具,所以一定要理解透彻。
首先看一下GBDT的算法过程

代表的就是前m个弱分类器预测结果的累加值(注意是前m个,不是第m个)
L代表的是损失函数
下面我先来宏观看一下其是怎么工作的:
假设我们现在要训练第m个弱分离器h,那么我们要达到的目标是什么呢?
那就是使得最小,y代表真实值
怎么训练h(x)这棵树使得上面最小呢?那就是求梯度,假设这里选用的损失函数是系数为四分之一二次函数如下:

假设真实值y为0,,那么在-1处求导变得到是-1/2,那么
看是不是距离0相较于-1更近了一步呢?
实际上梯度的含义就是下降速度最快的方向,
于是乎我们就将负的梯度值作为h(x)这棵树的目标值,只要它能够拟合出负的梯度值,那么我们通过加上这个梯度值就可以得到真实值。
好了上面就是核心过程,下面我们来一步步看看上面图片中公式的意思。
这里有较多的数学符号,所幸的是都比较容易理解,就提一下
其在数学中代表的含义是求变量q使得f(x,q)最小,是一个最优化求参数问题。
步骤1:是一个初始化求的过程,公式的意思就是说,求一个
,然后其分别和各个目标值
带入到损失函数L中,使得总体 损失最小,其实这里只是为了使得给出的算法更具普遍性才写的这么复杂,大多数的时候这里的
就取所有
的平均值 就 好。
步骤2:这里就是一个for循环,M代表的就是一共要生成M个弱分类器即最终的强分类器是由M个弱分类器线性组合而成的
步骤3:这里就是求负梯度值了,随着L函数的不同,所求出的结果也是不尽相同,比如:
步骤4:这里其实就是训练当前这一个分类器h,该树以x作为输入数据,以步骤3求得的负梯度值为拟合目标,然后训练得到构造 该树的参数,可以看到在构造树的过程中没有采用最大熵而是采用了均方差,正如一开头DT中介绍的那样。至于这里 还有一个
参数,其实就是更进一步提供了泛化能力,还是那句话为了使得给出的算法更具普遍性这里就再加一个参 数。
步骤5:该步骤的目的就是训练得到模型相加时权值,Boosting模型不是将多个弱分类器线性相加嘛,比如
a,b,c就是系数对吧,
其实就是这里的a,b,c,大多时候这里的
可以看成是训练模 型时需要一个调的一个超参数即学习率。
步骤6:就是更新得到第m次的值,即前m颗树预测值的线性累加和。
说明一点:从数学角度来看,步骤4和步骤5其实都是采用了最小二乘法。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Shrinkage
其是一个规避过拟合的方法,具体来说就是每次走一大步可能错过最优解,导致的结果就是在最优解周围来回徘徊,却永远得不到最优解,所以Shrinkage的思想就是每一次走的都是小碎步,虽然收敛速度可能慢些,但是却能保证最大可能的到达最优解,即以收敛速度为代价来换取最优解,体现在GBDT中就是我们会训练更多的树,其实对应到GBDT算法图片中,步骤4中的,步骤5中的
所做的目的就是Shrinkage过程即防止过拟合。
为了好理解我们还是举个小例子,还是以二次函数为类:

假设目标值是0,当前值为-2,那么-2处的导数是-4对吧,接下来我们更新下一步即
-2+(4)=2,你会发现其跳到2了,那么2处的导数是4,接着更新下一步即
2+(-4)=-2,其又跳到-2了
实际上其会一直在-2和2中徘徊却永远不能更近一步的到达0
那我们用一下Shrinkage思想吧,就是缩减步伐,假设将步伐缩减为一半,即
当前值是-2时,导数是-2,接下来我们更新看一下:
-2+(2)=0,是不是直接就达到最优值啦!!!!!!!
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GBDT回归问题
首先还是给出其算法

对比其通用框架,这里只是将每一步更加具体化
步骤1 :采用了均值作为初始化
步骤2 :不变
步骤3:由于这里采用了作为损失函数,所以得到了负梯度值为
步骤4:通用模板这里是采用均方差训练树,这里一样,只不过这里将树的参数写成了叶子节点
,其含义是第m颗树的第j个 叶子节点集合

假设这是第8颗树,那么
步骤5:准确来说并不是通用模板的步骤5,其其实就是通用模板中步骤6中的的值,即当前树h预测的输出值,具体是多 少呢?其计算结果其实是和选用的loss function有关系的
当选用MSE作为loss function时结果就是均值,,例如上面的例子,左边的叶子节点输出值为 (8+10)/2=9,右边叶子节点输出为(25+30+47)/2=51,所以下次来一个输入值,当其落在左面这个叶子节点的时候,该 树的输出值就是9,右边则是51,注意这里的
并不是样本真真的目标值,而是当前的梯度,即
上面还有个~号,因为输 入的原因,笔者这里给y上面加不了~
当选用MAE作为loss function时,输出值是
当使用Logistic loss作为时,输出值为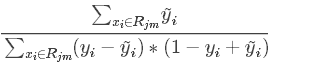
注意使用GBDT作为二分类时,正是这种情况。
步骤6:没变
那么通用步骤中的步骤5呢?其实这里并没有给出,还是那句话,该步骤其实就是一个学习率
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GBDT二分类问题
还是先给出其算法,和回归问题相比这里本质没什么大的不同,只不过目标值只有0和1这两个值,再一个不同就是采用了Logistic loss作为损失函数

步骤1:这里并没有采用均值,而是采用如图所示的形式。
步骤2:不变
步骤3:这里采用Logistic loss作为损失函数即
其中
那么求其梯度可以得到上图所示的形式。
步骤4:没啥说的和回归问题一样
步骤5:这里是因为采用Logistic loss作为损失函数导致的该结果
步骤6:没变
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
说明:通过看上面两部分可能有人会对步骤5公式的得来产生疑问,其到底是怎么得到的,其实其有严密的数学推导过程和逻辑在里面,GBDT论文作者在论文中也并没有详细介绍,有兴趣的同学可以自行查阅资料推导看看对于不同的loss function函数这里是怎么得到不同结果的,笔者这里直接就给出了结果
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GBDT多分类问题
还是先给出算法:

这里比以前的多了一个for循环,其是这样做的:
现将分类转化为one-hot形式比如有如下:假设有三个类别,7个样本。

其针对类别1一共训练M颗树,类别2一共训练M颗树,类别3一共训练M颗树
所以假设有K个类别,实际上一共训练了M*K颗树
训练过程是先训练各个类别的第一棵树,然后再训练各个类别的第二棵树,,,,,,直到M即每个类别下有M棵树。
其它所有步骤和上面基本相同需要注意的就是其选用的损失函数:
其中
----------------------------------------------------------------------------------------------------------------------------------------------------------------
说明:对于二分类和多分类中选用的损失的函数其实分别看做是Logistic loss和softmax形式即,本质来说softmax是更具一般形式的,Logistic loss只不过是softmax的一种情况,这两种形式的损失函数在深度学习中尤为常见,如果大家打算入坑深度学习的话,也一定记得这哥俩,哈哈哈。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
总结:
1)不论是回归还是分类,其本质思想没有变,即使用前m-1棵树损失函数总值的负梯度值作为目标值去训练当前这一棵m树,进而 使得m棵树的累加和逼近真实值!
2)通过上述我们发现对于GBDT回归模型也好,分类模型也罢,其在代码实现方面其实都是相同的,所以去看源码的话你会发现 GBDT虽然看似有GradientBoostingRegressor()和GradientBoostingClassifier()两种方法,但是两者都是继承了 BaseGradientBoosting()类的,该类包含了共同的步骤比如求负梯度值
3)简单总结一下其何Adaboost的不同点:
Adaboost是通过前项计算的一种模式,然后通过提升错分数据点的权重来定位模型的不足
更具选取的损失函数等不同其可以分为:

而GBDT求梯度反射可以看成是后向更新是通过算负梯度值来提升模型的不足
------------------------------------------------------------------------------------------------------------------------------------------------------------------
下一篇GBDT的升级版:Xgboost也是实际用的最多的一种模型https://blog.csdn.net/weixin_42001089/article/details/84965333